Putting that talk together reminded me about how far we have come in the last year both with the progress of WebRTC, its standards and browser implementations, as well as with our own small team at NICTA and our rtc.io WebRTC toolbox.
One of the most exciting opportunities is still under-exploited: the data channel. When I talked about the above slide and pointed out Bananabread, PeerCDN, Copay, PubNub and also later WebTorrent, that’s where I really started to get Web Developers excited about WebRTC. They can totally see the shift in paradigm to peer-to-peer applications away from the Server-based architecture of the current Web.
Many were also excited to learn more about rtc.io, our own npm nodules based approach to a JavaScript API for WebRTC.
We believe that the World of JavaScript has reached a critical stage where we can no longer code by copy-and-paste of JavaScript snippets from all over the Web universe. We need a more structured module reuse approach to JavaScript. Node with JavaScript on the back end really only motivated this development. However, we’ve needed it for a long time on the front end, too. One big library (jquery anyone?) that does everything that anyone could ever need on the front-end isn’t going to work any longer with the amount of functionality that we now expect Web applications to support. Just look at the insane growth of npm compared to other module collections:
Packages per day across popular platforms (Shamelessly copied from: nodejitsu.com)
For those that - like myself - found it difficult to understand how to tap into the sheer power of npm modules as a font end developer, simply use browserify. npm modules are prepared following the CommonJS module definition spec. Browserify works natively with that and “compiles” all the dependencies of a npm modules into a single bundle.js file that you can use on the front end through a script tag as you would in plain HTML. You can learn more about browserify and module definitions and how to use browserify.
For those of you not quite ready to dive in with browserify we have prepared prepared the rtc module, which exposes the most commonly used packages of rtc.io through an “RTC” object from a browserified JavaScript file. You can also directly download the JavaScript file from GitHub.
So, I hope you enjoy rtc.io and I hope you enjoy my slides and large collection of interesting links inside the deck, and of course: enjoy WebRTC! Thanks to Damon, JEeff, Cathy, Pete and Nathan - you’re an awesome team!
On a side note, I was really excited to meet the author of browserify, James Halliday (@substack) at WDCNZ, whose talk on “building your own tools” seemed to take me back to the times where everything was done on the command-line. I think James is using Node and the Web in a way that would appeal to a Linux Kernel developer. Fascinating!!
If you’ve been interested in WebRTC and haven’t lived under a rock, you will know about Google’s open source testing application for WebRTC: AppRTC.
When you go to the site, a new video conferencing room is automatically created for you and you can share the provided URL with somebody else and thus connect (make sure you’re using Google Chrome, Opera or Mozilla Firefox).
We’ve been using this application forever to check whether any issues with our own WebRTC applications are due to network connectivity issues, firewall issues, or browser bugs, in which case AppRTC breaks down, too. Otherwise we’re pretty sure to have to dig deeper into our own code.
Now, AppRTC creates a pretty poor quality video conference, because the browsers use a 640x480 resolution by default. However, there are many query parameters that can be added to the AppRTC URL through which the connection can be manipulated.
Here are my favourite parameters:
hd=true : turns on high definition, ie. minWidth=1280,minHeight=720
stereo=true : turns on stereo audio
debug=loopback : connect to yourself (great to check your own firewalls)
tt=60 : by default, the channel is closed after 30min - this gives you 60 (max 1440)
deck.js is one of the new HTML5-based presentation tools. It’s simple to use, in particular for your basic, every-day presentation needs. You can also create more complex slides with animations etc. if you know your HTML and CSS.
Yesterday at linux.conf.au (LCA), I gave a presentation using deck.js. But I didn’t give it from the lectern in the room in Perth where LCA is being held - instead I gave it from the comfort of my home office at the other end of the country.
I used my laptop with in-built webcam and my Chrome browser to give this presentation. Beforehand, I had uploaded the presentation to a Web server and shared the link with the organiser of my speaker track, who was on site in Perth and had set up his laptop in the same fashion as myself. His screen was projecting the Chrome tab in which my slides were loaded and he had hooked up the audio output of his laptop to the room speaker system. His camera was pointed at the audience so I could see their reaction.
I loaded a slide master URL: http://html5videoguide.net/presentations/lca_2014_webrtc/?master
and the room loaded the URL without query string: http://html5videoguide.net/presentations/lca_2014_webrtc/.
Then I gave my talk exactly as I would if I was in the same room. Yes, it felt exactly as though I was there, including nervousness and audience feedback.
How did we do that? WebRTC (Web Real-time Communication) to the rescue, of course!
We used one of the modules of the rtc.io project called rtc-glue to add the video conferencing functionality and the slide navigation to deck.js. It was actually really really simple!
Here are the few things we added to deck.js to make it work:
Code added to index.html to make the video connection work:
The iceServers config is required to punch through firewalls - you may also need a TURN server. Note that you need a signalling server - in our case we used http://rtc.io/switchboard/, which runs the code from rtc-switchboard.
Code added to index.html to synchronize slide navigation:
glue.events.once('connected', function(signaller) { if (location.search.slice(1) !== '') { $(document).bind('deck.change', function(evt, from, to) { signaller.send('/slide', { idx: to, sender: signaller.id }); }); } signaller.on('slide', function(data) { console.log('received notification to change to slide: ', data.idx); $.deck('go', data.idx); });});
This simply registers a callback on the slide master end to send a slide position message to the room end, and a callback on the room end that initiates the slide navigation.
Feel free to write your own slides in this manner - I would love to have more users of this approach. It should also be fairly simple to extend this to share pointer positions, so you can actually use the mouse pointer to point to things on your slides remotely. Would love to hear your experiences!
Note that the slides are actually a talk about the rtc.io project, so if you want to find out more about these modules and what other things you can do, read the slide deck or watch the talk when it has been published by LCA.
Many thanks to Damon Oehlman for his help in getting this working.
BTW: somebody should really fix that print style sheet for deck.js - I’m only ever getting the one slide that is currently showing. ;-)
Rob explains very clearly how to create your first video, audio or data peer-connection using WebRTC in current Google Chrome or Firefox (I think it also now applies to Opera, though that wasn’t the case when his book was published). He makes available example code, so you can replicate it in your own Web application easily, including the setup of a signalling server. He also points out that you need a ICE (STUN/TURN) server to punch through firewalls and gives recommendations for what software is available, but stops short of explaining how to set them up.
Rob’s focus is very much on the features required in a typical Web application:
video calls
audio calls
text chats
file sharing
In fact, he provides the most in-depth demo of how to set up a good file sharing interface I have come across.
Rob then also extends his introduction to WebRTC to two key application areas: education and team communication. His recommendations are spot on and required reading for anyone developing applications in these spaces.
Alan and Dan’s book was written more than a year ago and explains that state of standardisation at that time. It’s probably a little out-dated now, but it still gives you good foundations on why some decisions were made the way they are and what are contentious issues (some of which still remain). If you really want to understand what happens behind the scenes when you call certain functions in the WebRTC APIs of browsers, then this is for you.
Alan and Dan’s book explains in more details than Rob’s book how IP addresses of communication partners are found, how firewall holepunching works, how sessions get negotiated, and how the standards process works. It’s probably less useful to a Web developer who just wants to implement video call functionality into their Web application, though if something goes wrong you may find yourself digging into the details of SDP, SRTP, DTLS, and other cryptic abbreviations of protocols that all need to work together to get a WebRTC call working.
---
Overall, both books are worthwhile and cover different aspects of WebRTC that you will stumble across if you are directly dealing with WebRTC code.
The key driving force for improvements to WebVTT continues to be the accurate representation of CEA608/708 captioning. As part of that drive, we’ve introduced regions (the CEA708 “window” concept) to WebVTT. WebVTT regions satisfy multiple requirements of CEA608/708 captions:
support for rollup captions
support for background color and border color on a group of cues independent of the background color of the individual cue
possibility to move a group of cues from one location on screen to a different
support to specify an anchor point and a growth direction for cues when their text size changes
support for specifying a fixed number of lines to be rendered
possibility to specify which region is rendered in front of which other one when regions overlap
While WebVTT regions enable us to satisfy all of the above points, the specification isn’t actually complete yet and some of the above needs aren’t satisfied yet.
We have an open bug to move a region elsewhere. A first discussion at FOMS seemed to to indicate that we’ll have to add syntax for updating a region at a particular time and thus give region definitions a way to be valid only for a certain time frame. I can imagine that the region definitions that we have in the header of the WebVTT file now would have an implicitly defined time frame from the start to the end of the file, but can be overruled by a re-definition anywhere within the WebVTT file. That redefinition needs to provide a start and end time.
We registered a bug to add specifying the width and height of regions (and possibly of cues) by em (i.e. by multiples of the largest character in a font). This should allow us to have the region grow/shrink around the region anchor point with a change of font size by script or a user. em specifications should also be applied to cues - that matches the column count of CEA708/608 better.
When regions overlap, the original region extension spec already suggested a “layer” cue setting. It will be easy to add it.
Another change that we will ultimately need is the “scroll” setting: we will need to introduce support for scrolling text down or from left-to-right or right-to-left, e.g. vertical scrolling text seems to be used in some Chinese caption use cases.
2. Unify Rendering Approach
The introduction of regions created a second code path in the rendering spec with some duplication. At FOMS we discussed if it was possible to unify that. The suggestion is to render all cues into a region. Those that are not part of a region would be rendered into an anonymous region that covers the complete viewport. There may be some consequences to this, e.g. cue settings should be usable across all cues, no matter whether or not part of a region, and avoiding cue overlap may need to be done within regions.
Here’s a rough outline of the path of the new rendering algorithm:
Create a cue box and put it in its region (anonymous if none given).
Calculate position & size of cue box from cue settings (position, line, size).
Calculate position of cue text inside cue box from remaining cue settings (vertical, align).
3. Vertical Features
WebVTT includes vertical rendering, both right-to-left and left-to-right. However, regions are not defined for vertical. Eventually, we’re going to have to look at the vertical features of WebVTT with more details and figure out whether the spec is working for them and what real-world requirements we have missed. We hope we can get some help from users in countries where vertically rendered captions/subtitles are the norm.
4. Best Practices
Some of he WebVTT users at FOMS suggested it would be advantageous to start a list of “best practices” for how to author captions with WebVTT. Example recommendations are:
Use line numbers only to position cues from top or bottom of viewport. Don’t use otherwise.
Note that when the user increases the fontsize in rollup captions and thus introduces new line breaks, your cues will roll by faster because the number of lines of a rollup is fixed.
Make sure to use and UTF-8 markers to control the directionality of your text.
It would be nice if somebody started such a document.
A common use case for timed data is the use of preview thumbnails on the navigation bar of videos. A native implementation of preview thumbnails would allow crawlers and search engines to have a standardised way of extracting timed images for media files, so introduction of a new @kind value “thumbnails” was suggested.
The content of a “thumbnails” cue could be any of:
an image URL
a sprite URL to a single image
a spatial & temporal media fragment URL to a media resource
base64 encoded image (data URI)
an iframe offset to the media resource
The suggestion is to allow anything that would work in a img @src attribute as value in a cue of @kind=“thumbnails”. Responsive images might also be useful for a track of @kind=“thumbnails”. It may even be possible to define an inband thumbnail track based on the track of @kind=“thumbnails”. Such cues should also work in the JavaScript track API.
5.2 Chapter markers
There is interest to put richer content than just a chapter title into chapter cues. Often, chapters consist of a title, text and and image. The text is not so important, but the image is used almost everywhere that chapters are used. There may be a need to extend chapter cue content with images, similar to what a @kind=“thumbnails” track offers.
The conclusion that we arrived at was that we need to make @kind=“thumbnails” work first and then look at using the learnings from that to extend @kind=“chapters”.
5.3 Inband tracks for live video
A difficult topic was opened with the question of how to transport text tracks in live video. In live captioning, end times are never created for cues, but are implied by the start time of the next cue. This is a use case that hasn’t been addressed in HTML5/WebVTT yet. An old proposal to allow a special end time value of “NEXT” was discussed and recommended for adoption. Also, there was support for the spec change that stops blocking loading VTT until all cues have been loaded.
5.4 Cross-domain VTT loading
A brief discussion centered around the fact that the spec disallows cross-domain loading of WebVTT files, but that no browser implements this. This needs to be discussion at the HTML WG level.
6. Regions in live captioning
The final topic that we discussed was how we could provide support for regions in live captioning.
The currently active region definitions will need to be come part of every header of every VTT file segment that HLS uses, so it’s available in case the cues in the segment file reference it.
“NEXT” in end time markers would make authoring of live captioned VTT files easier.
If the application wants to use 1 word at a time and doesn’t want to delay sending the word until the full cue is authored (e.g. in a Hangout type environment), we will need to introduce the concept of “cue continuation markers”, so we know that a cue could be extended with the next VTT file fragment.
This is an extensive and impressive amount of discussion around WebVTT and a lot of new work to be performed in the future. I’m very grateful for all the people who have contributed to these discussions at FOMS and will hopefully continue to help get the specifications right.
The slide provide a high-level summary of the accessibility features that we’ve developed in the W3C for HTML5, including:
Subtitles & Captions with WebVTT and the track element
Video Descriptions with WebVTT, the track element and speech synthesis
Chapters with WebVTT for semantic navigation
Audio Descriptions through synchronising an audio track with a video
Sign Language video synchronized with a main video
I received some excellent questions.
The obvious one was about why WebVTT and not TTML. While for anyone who has tried to implement TTML support, the advantages of WebVTT should be clear, for some the decision of the browsers to go with WebVTT still seems to be bothersome. The advantages of CSS over XSL-FO in a browser-context are obvious, but not as much outside browsers. So, the simplicity of WebVTT and the clear integration with HTML have to speak for themselves. Conversion between TTML and WebVTT was a feature that was being asked for.
I received a question about how to support ducking (reduce the volume of the main audio track) when using video descriptions. My reply was to either use video descriptions with WebVTT and do ducking during the times that a cue is active, or when using audio descriptions (i.e. actual audio tracks) to add an additional WebVTT file of kind=metadata to mark the intervals in which to do ducking. In both cases some JavaScript will be necessary.
I received another question about how to do clean audio, which I had almost forgotten was a requirement from our earlier media accessibility document. “Clean audio” consists of isolating the audio channel containing the spoken dialog and important non-speech information that can then be amplified or otherwise modified, while other channels containing music or ambient sounds are attenuated. I suggested using the mediagroup attribute to provide a main video element (without an audio track) and then the other channels as parallel audio tracks that can be turned on and off and attenuated individually. There is some JavaScript coding involved on top of the APIs that we have defined in HTML, but it can be implemented in browsers that support the mediagroup attribute.
Another question was about the possibilities to extend the list of @kind attribute values. I explained that right now we have a proposal for a new text track kind=“forced” so as to provide forced subtitles for sections of video with foreign language. These would be on when no other subtitle or caption tracks are activated. I also explained that if there is a need for application-specific text tracks, the kind=“metadata” would be the correct choice.
I received some further questions, in particular about how to apply styling to captions (e.g. color changes to text) and about how closely the browser are able to keep synchronization across multiple media elements. The earlier was easily answered with the ::cue pseudo-element, but the latter is a quality of implementation feature, so I had to defer to individual browsers.
Overall it was a good exercise to summarize the current state of HTML5 video accessibility and I was excited to show off support in Chrome for all the features that we designed into the standard.
I finished up at Google last week and am now working at NICTA, an Australian ICT research institute.
My work with Google was exciting and I learned a lot. I like to think that Google also got a lot out of me - I coded and contributed to some YouTube caption features, I worked on Chrome captions and video controls, and above all I worked on video accessibility for HTML at the W3C.
I was one of the key authors of the W3C Media Accessibility Requirements document that we created in the Media Accessibility Task Force of the W3C HTML WG. I then went on to help make video accessibility a reality. We created WebVTT and the and applied it to captions, subtitles, chapters (navigation), video descriptions, and metadata. To satisfy the need for synchronisation of video with other media resources such as sign language video or audio descriptions, we got the MediaController object and the @mediagroup attribute.
I must say it was a most rewarding time. I learned a lot about being productive at Google, collaborate successfully over the distance, about how the WebKit community works, and about the new way of writing W3C standard (which is more like pseudo-code). As one consequence, I am now a co-editor of the W3C HTML spec and it seems I am also about to become the editor of the WebVTT spec.
At NICTA my new focus of work is WebRTC. There is both a bit of research and a whole bunch of application development involved. I may even get to do some WebKit development, if we identify any issues with the current implementation. I started a week ago and am already amazed by the amount of work going on in the WebRTC space and the amazing number of open source projects playing around with it. Video conferencing is a new challenge and I look forward to it.
I decided to use socket.io for the signalling following the idea of Luc, which made the server code even smaller and reduced it to a mere reflector:
var app = require('http').createServer().listen(1337); var io = require('socket.io').listen(app); io.sockets.on('connection', function(socket) { socket.on('message', function(message) { socket.broadcast.emit('message', message); }); });
Then I turned to the client code. I was surprised to see the massive changes that PeerConnection has gone through. Check out my slide deck to see the different components that are now necessary to create a PeerConnection.
I was particularly surprised to see the SDP object now fully exposed to JavaScript and thus the ability to manipulate it directly rather than through some API. This allows Web developers to manipulate the type of session that they are asking the browsers to set up. I can imaging e.g. if they have support for a video codec in JavaScript that the browser does not provide built-in, they can add that codec to the set of choices to be offered to the peer. While it is flexible, I am concerned if this might create more problems than it solves. I guess we’ll have to wait and see.
I was also surprised by the need to use ICE, even though in my experiment I got away with an empty list of ICE servers - the ICE messages just got exchanged through the socket.io server. I am not sure whether this is a bug, but I was very happy about it because it meant I could run the whole demo on a completely separate network from the Internet.
The most exciting news since my talk is that Mozilla and Google have managed to get a PeerConnection working between Firefox and Chrome - this is the first cross-browser video conference call without a plugin! The code differences are minor.
Since the specification of the WebRTC API and of the MediaStream API are now official Working Drafts at the W3C, I expect other browsers will follow. I am also looking forward to the possibilities of:
multi-peer video conferencing like the efforts around webrtc.io,
The best places to learn about the latest possibilities of WebRTC are webrtc.org and the W3C WebRTC WG. code.google.com has open source code that continues to be updated to the latest released and interoperable features in browsers.
The video of my talk is in the process of being published. There is a MP4 version on the Linux Australia mirror server, but I expect it will be published properly soon. I will update the blog post when that happens.
TTML has been specified by the W3C Timed Text Working Group and released as a RECommendation v1.0 in November 2010. Since then, several organisations have tried to adopt it as their caption file format. This includes the SMPTE, the EBU (European Broadcasting Union), and Microsoft.
Both, Microsoft and the EBU actually looked at TTML in detail and decided that in order to make it usable for their use cases, a restriction of its functionalities is needed.
EBU-TT
The EBU released EBU-TT, which restricts the set of valid attributes and feature. “The EBU-TT format is intended to constrain the features provided by TTML, especially to make EBU-TT more suitable for the use with broadcast video and web video applications.” (see EBU-TT).
In addition, EBU-specific namespaces were introduce to extend TTML with EBU-specific data types, e.g. ebuttdt:frameRateMultiplierType or ebuttdt:smpteTimingType. Similarly, a bunch of metadata elements were introduced, e.g. ebuttm:documentMetadata, ebuttm:documentEbuttVersion, or ebuttm:documentIdentifier.
The use of namespaces as an extensibility mechanism will ascertain that EBU-TT files continue to be valid TTML files. However, any vanilla TTML parser will not know what to do with these custom extensions and will drop them on the floor.
Simple Delivery Profile
With the intention to make TTML ready for “internet delivery of Captions originated in the United States”, Microsoft proposed a “Simple Delivery Profile for Closed Captions (US)” (see Simple Profile). The Simple Profile is also a restriction of TTML.
Unfortunately, the Microsoft profile is not the same as the EBU-TT profile: for example, it contains the “set” element, which is not conformant in EBU-TT. Similarly, the supported style features are different, e.g. Simple Profile supports “display-region”, while EBU-TT does not. On the other hand, EBU-TT supports monospace, sans-serif and serif fonts, while the Simple profile does not.
Thus files created for the Simple Delivery Profile will not work on players that expect EBU-TT and the reverse.
Fortunately, the Simple Delivery Profile does not introduce any new namespaces and new features, so at least it is an explicit subpart of TTML and not both a restriction and extension like EBU-TT.
SMPTE-TT
SMPTE also created a version of the TTML standard called SMPTE-TT. SMPTE did not decide on a subset of TTML for their purposes - it was simply adopted as a complete set. “This Standard provides a framework for timed text to be supported for content delivered via broadband means,…” (see SMPTE-TT).
However, SMPTE extended TTML in SMPTE-TT with an ability to store a binary blob with captions in another format. This allows using SMPTE-TT as a transport format for any caption format and is deemed to help with “backwards compatibility”.
Now, instead of specifying a profile, SMPTE decided to define how to convert CEA-608 captions to SMPTE-TT. Even if it’s not called a “profile”, that’s actually what it is. It even has its own namespace: “m608:”.
Conclusion
With all these different versions of TTML, I ask myself what a video player that claims support for TTML will do to get something working. The only chance it has is to implement all the extensions defined in all the different profiles. I pity the player that has to deal with a SMPTE-TT file that has a binary blob in it and is expected to be able to decode this.
Now, what is a caption author supposed to do when creating TTML? They obviously cannot expect all players to be able to play back all TTML versions. Should they create different files depending on what platform they are targeting, i.e. a EBU-TT version, a SMPTE-TT version, a vanilla TTML version, and a Simple Delivery Profile version? Should they by throwing all the features of all the versions into one TTML file and hope that the players will pick out the right things that they require and drop the rest on the floor?
Maybe the best way to progress would be to make a list of the “safe” features: those features that every TTML profile supports. That may be the best way to get an “interoperable TTML” file. Here’s me hoping that this minimal set of features doesn’t just end up being the usual (starttime, endtime, text) triple.
UPDATE:
I just found out that UltraViolet have their own profile of SMPTE-TT called CFF-TT (see UltraViolet FAQ and spec). They are making some SMPTE-TT fields optional, but introduce a new @forcedDisplayMode attribute under their own namespace “cff:”.
A bit over a week ago I gave a presentation at Web Directions Code 2012 in Melbourne. Maxine and John asked me to speak about something related to HTML5 video, so I went for the new shiny: WebRTC - real-time communication in the browser.
I only had 20 min, so I had to make it tight. I wanted to show off video conferencing without special plugins in Google Chrome in just a few lines of code, as is the promise of WebRTC. To a large extent, I achieved this. But I made some interesting discoveries along the way. Demos are in the slide deck.
UPDATE: Opera 12 has been released with WebRTC support.
Housekeeping: if you want to replicate what I have done, you need to install a Google Chrome Web Browser 19+. Then make sure you go to chrome://flags and activate the MediaStream and PeerConnection experiment(s). Restart your browser and now you can experiment with this feature. Big warning up-front: it’s not production-ready, since there are still changes happening to the spec and there is no compatible implementation by another browser yet.
Here is a brief summary of the steps involved to set up video conferencing in your browser:
Set up a video element each for the local and the remote video stream.
Grab the local camera and stream it to the first video element.
(*) Establish a connection to another person running the same Web page.
Send the local camera stream on that peer connection.
Accept the remote camera stream into the second video element.
Now, the most difficult part of all of this - believe it or not - is the signalling part that is required to build the peer connection (marked with (*)). Initially I wanted to run completely without a server and just enter the remote’s IP address to establish the connection. This is, however, not a functionality that the PeerConnection object provides [might this be something to add to the spec?].
So, you need a server known to both parties that can provide for the handshake to set up the connection. All the examples that I have seen, such as https://apprtc.appspot.com/, use a channel management server on Google’s appengine. I wanted it all working with HTML5 technology, so I decided to use a Web Socket server instead.
I implemented my Web Socket server using node.js (code of websocket server). The video conferencing demo is in the slide deck in an iframe - you can also use the stand-alone html page. Works like a treat.
While it is still using Google’s STUN server to get through NAT, the messaging for setting up the connection is running completely through the Web Socket server. The messages that get exchanged are plain SDP message packets with a session ID. There are OFFER, ANSWER, and OK packets exchanged for each streaming direction. You can see some of it in the below image:
I’m not running a public WebSocket server, so you won’t be able to see this part of the presentation working. But the local loopback video should work.
At the conference, it all went without a hitch (while the wireless played along). I believe you have to host the WebSocket server on the same machine as the Web page, otherwise it won’t work for security reasons.
A whole new world of opportunities lies out there when we get the ability to set up video conferencing on every Web page - scary and exciting at the same time!
I spoke about the video and audio element in HTML5, how to provide fallback content, how to encode content, how to control them from JavaScript, and briefly about Drupal video modules, though the next presentation provided much more insight into those. I explained how to make the HTML5 media elements accessible, including accessible controls, captions, audio descriptions, and the new WebVTT file format. I ran out of time to introduce the last section of my slides which are on WebRTC.
Linux.conf.au
On the first day of LCA I gave a talk both in the Multimedia Miniconf and the Browser Miniconf.
Browser Miniconf
In the Browser Miniconf I talked about “Web Standardisation – how browser vendors collaborate, or not” (slides). Maybe the most interesting part about this was that I tried out a new slide “deck” tool called impress.js. I’m not yet sure if I like it but it worked well for this talk, in which I explained how the HTML5 spec is authored and who has input.
I also sat on a panel of browser developers in the Browser Miniconf (more as a standards than as a browser developer, but that’s close enough). We were asked about all kinds of latest developments in HTML5, CSS3, and media standards in the browser.
Multimedia Miniconf
In the Multimedia Miniconf I gave a “HTML5 media accessibility update” (slides). I talked about the accessibility problems of Flash, how native HTML5 video players will be better, about accessible video controls, captions, navigation chapters, audio descriptions, and WebVTT. I also provided a demo of how to synchronize multiple video elements using a polyfill for the multitrack API.
Finally, and most importantly, Alice Boxhall and myself gave a talk in the main linux.conf.au titled “Developing Accessible Web Apps - how hard can it be?” (video, slides). I spoke about a process that you can follow to make your Web applications accessible. I’m writing a separate blog post to explain this in more detail. In her part, Alice dug below the surface of browsers to explain how the accessibility markup that Web developers provide is transformed into data structures that are handed to accessibility technologies.
The Open Video Conference that took place on 10-12 September was so overwhelming, I’ve still not been able to catch my breath! It was a dense three days for me, even though I only focused on the technology sessions of the conference and utterly missed out on all the policy and content discussions.
Roughly 60 people participated in the Open Media Software (OMS) developers track. This was an amazing group of people capable and willing to shape the future of video technology on the Web:
HTML5 video developers from Apple, Google, Opera, and Mozilla (though we missed the NZ folks),
codec developers from WebM, Xiph, and MPEG,
Web video developers from YouTube, JWPlayer, Kaltura, VideoJS, PopcornJS, etc.,
content publishers from Wikipedia, Internet Archive, YouTube, Netflix, etc.,
open source tool developers from FFmpeg, gstreamer, flumotion, VideoLAN, PiTiVi, etc,
and many more.
To provide a summary of all the discussions would be impossible, so I just want to share the key take-aways that I had from the main sessions.
Tim Terriberry (Mozilla), Serge Lachapelle (Google) and Ethan Hugg (CISCO) moderated this session together (slides). There are activities both at the W3C and at IETF - the ones at IETF are supposed to focus on protocols, while the W3C ones on HTML5 extensions.
The current proposal of a PeerConnection API has been implemented in WebKit/Chrome as open source. It is expected that Firefox will have an add-on by Q1 next year. It enables video conferencing, including media capture, media encoding, signal processing (echo cancellation etc), secure transmission, and a data stream exchange.
Current discussions are around the signalling protocol and whether SIP needs to be required by the standard. Further, the codec question is under discussion with a question whether to mandate VP8 and Opus, since transcoding gateways are not desirable. Another question is how to measure the quality of the connection and how to report errors so as to allow adaptation.
What always amazes me around RTC is the sheer number of specialised protocols that seem to be required to implement this. WebRTC does not disappoint: in fact, the question was asked whether there could be a lighter alternative than to re-use dozens of years of protocol development - is it over-engineered? Can desktop players connect to a WebRTC session?
We are already in a second or third revision of this part of the HTML5 specification and yet it seems the requirements are still being collected. I’m quietly confident that everything is done to make the lives of the Web developer easier, but it sure looks like a huge task.
Zohar Babin (Kaltura) and myself moderated this session and I must admit that this session was the biggest eye-opener for me amongst all the sessions. There was a large number of Flash developers present in the room and that was great, because sometimes we just don’t listen enough to lessons learnt in the past.
This session gave me one of those aha-moments: it the form of the Flash appendBytes() API function.
The appendBytes() function allows a Flash developer to take a byteArray out of a connected video resource and do something with it - such as feed it to a video for display. When I heard that Web developers want that functionality for JavaScript and the video element, too, I instinctively rejected the idea wondering why on earth would a Web developer want to touch encoded video bytes - why not leave that to the browser.
But as it turns out, this is actually a really powerful enabler of functionality. For example, you can use it to:
display mid-roll video ads as part of the same video element,
sequence playlists of videos into the same video element,
implement DVR functionality (high-speed seeking),
do mash-ups,
do video editing,
adaptive streaming.
This totally blew my mind and I am now completely supportive of having such a function in HTML5. Together with media fragment URIs you could even leave all the header download management for resources to the Web browser and just request time ranges from a video through an appendBytes() function. This would be easier on the Web developer than having to deal with byte ranges and making sure that appropriate decoding pipelines are set up.
Philip Jagenstedt (Opera) and myself moderated this session. We focused on the HTML5 track element and the WebVTT file format. Many issues were identified that will still require work.
One particular topic was to find a standard means of rendering the UI for caption, subtitle, und description selection. For example, what icons should be used to indicate that subtitles or captions are available. While this is not part of the HTML5 specification, it’s still important to get this right across browsers since otherwise users will get confused with diverging interfaces.
Chaptering was discussed and a particular need to allow URLs to directly point at chapters was expressed. I suggested the use of named Media Fragment URLs.
The use of WebVTT for descriptions for the blind was also discussed. A suggestion was made to use the voice tag to allow for “styling” (i.e. selection) of the screen reader voice.
Finally, multitrack audio or video resources were also discussed and the @mediagroup attribute was explained. A question about how to identify the language used in different alternative dubs was asked. This is an issue because @srclang is not on audio or video, only on text, so it’s a missing feature for the multitrack API.
Beyond this session, there was also a breakout session on WebVTT and the track element. As a consequence, a number of bugs were registered in the W3C bug tracker.
This session was moderated by John Luther and John Koleszar, both of the WebM Project. They started off with a presentation on current work on WebM, which includes quality testing and improvements, and encoder speed improvement. Then they moved on to questions about how to involve the community more.
The community criticised that communication of what is happening around WebM is very scarce. More sharing of information was requested, including a move to using open Google+ hangouts instead of Google internal video conferences. More use of the public bug tracker can also help include the community better.
Another pain point of the community was that code is introduced and removed without much feedback. It was requested to introduce a peer review process. Also it was requested that example code snippets are published when new features are announced so others can replicate the claims.
This all indicates to me that the WebM project is increasingly more open, but that there is still a lot to learn.
This session was moderated by Frank Galligan and Aaron Colwell (Google), and Mark Watson (Netflix).
Mark started off by giving us an introduction to MPEG DASH, the MPEG file format for HTTP adaptive streaming. MPEG has just finalized the format and he was able to show us some examples. DASH is XML-based and thus rather verbose. It is covering all eventualities of what parameters could be switched during transmissions, which makes it very broad. These include trick modes e.g. for fast forwarding, 3D, multi-view and multitrack content.
MPEG have defined profiles - one for live streaming which requires chunking of the files on the server, and one for on-demand which requires keyframe alignment of the files. There are clear specifications for how to do these with MPEG. Such profiles would need to be created for WebM and Ogg Theora, too, to make DASH universally applicable.
Further, the Web case needs a more restrictive adaptation approach, since the video element’s API is already accounting for some of the features that DASH provides for desktop applications. So, a Web-specific profile of DASH would be required.
Then Aaron introduced us to the MediaSource API and in particular the webkitSourceAppend() extension that he has been experimenting with. It is essentially an implementation of the appendBytes() function of Flash, which the Web developers had been asking for just a few sessions earlier. This was likely the biggest announcement of OVC, alas a quiet and technically-focused one.
Aaron explained that he had been trying to find a way to implement HTTP adaptive streaming into WebKit in a way in which it could be standardised. While doing so, he also came across other requirements around such chunked video handling, in particular around dynamic ad insertion, live streaming, DVR functionality (fast forward), constraint video editing, and mashups. While trying to sort out all these requirements, it became clear that it would be very difficult to implement strategies for stream switching, buffering and delivery of video chunks into the browser when so many different and likely contradictory requirements exist. Also, once an approach is implemented and specified for the browser, it becomes very difficult to innovate on it.
Instead, the easiest way to solve it right now and learn about what would be necessary to implement into the browser would be to actually allow Web developers to queue up a chunk of encoded video into a video element for decoding and display. Thus, the webkitSourceAppend() function was born (specification).
The proposed extension to the HTMLMediaElement is as follows:
partial interface HTMLMediaElement { // URL passed to src attribute to enable the media source logic. readonly attribute [URL] DOMString webkitMediaSourceURL; bool webkitSourceAppend(in Uint8Array data); // end of stream status codes. const unsigned short EOS_NO_ERROR = 0; const unsigned short EOS_NETWORK_ERR = 1; const unsigned short EOS_DECODE_ERR = 2; void webkitSourceEndOfStream(in unsigned short status); // states const unsigned short SOURCE_CLOSED = 0; const unsigned short SOURCE_OPEN = 1; const unsigned short SOURCE_ENDED = 2; readonly attribute unsigned short webkitSourceState;};
The code is already checked into WebKit, but commented out behind a command-line compiler flag.
Frank then stepped forward to show how webkitSourceAppend() can be used to implement HTTP adaptive streaming. His example uses WebM - there are no examples with MPEG or Ogg yet.
The chunks that Frank’s demo used were 150 video frames long (6.25s) and 5s long audio. Stream switching only switched video, since audio data is much lower bandwidth and more important to retain at high quality. Switching was done on multiplexed files.
Every chunk requires an XHR range request - this could be optimised if the connections were kept open per adaptation. Seeking works, too, but since decoding requires download of a whole chunk, seeking latency is determined by the time it takes to download and decode that chunk.
Similar to DASH, when using this approach for live streaming, the server has to produce one file per chunk, since byte range requests are not possible on a continuously growing file.
Frank did not use DASH as the manifest format for his HTTP adaptive streaming demo, but instead used a hacked-up custom XML format. It would be possible to use JSON or any other format, too.
After this session, I was actually completely blown away by the possibilities that such a simple API extension allows. If I wasn’t sold on the idea of a appendBytes() function in the earlier session, this one completely changed my mind. While I still believe we need to standardise a HTTP adaptive streaming file format that all browsers will support for all codecs, and I still believe that a native implementation for support of such a file format is necessary, I also believe that this approach of webkitSourceAppend() is what HTML needs - and maybe it needs it faster than native HTTP adaptive streaming support.
This session was moderated by Zachary Ozer and Pablo Schklowsky (JWPlayer). Their motivation for the topic was, in fact, also HTTP adaptive streaming. Once you leave the decisions about when to do stream switching to JavaScript (through a function such a wekitSourceAppend()), you have to expose stream metrics to the JS developer so they can make informed decisions. The other use cases is, of course, monitoring of the quality of video delivery for reporting to the provider, who may then decide to change their delivery environment.
The discussion found that we really care about metrics on three different levels:
measuring the network performance (bandwidth)
measuring the decoding pipeline performance
measuring the display quality
In the end, it seemed that work previously done by Steve Lacey on a proposal for video metrics was generally acceptable, except for the playbackJitter metric, which may be too aggregate to mean much.
I didn’t actually attend this session held by Anant Narayanan (Mozilla), but from what I heard, the discussion focused on how to manage permission of access to video camera, microphone and screen, e.g. when multiple applications (tabs) want access or when the same site wants access in a different session. This may apply to real-time communication with screen sharing, but also to photo sharing, video upload, or canvas access to devices e.g. for time lapse photography.
This was another session that I wasn’t able to attend, but I believe the creation of good open source video editing software and similar video creation software is really crucial to giving video a broader user appeal.
Jeff Fortin (PiTiVi) moderated this session and I was fascinated to later see his analysis of the lifecycle of open source video editors. It is shocking to see how many people/projects have tried to create an open source video editor and how many have stopped their project. It is likely that the creation of a video editor is such a complex challenge that it requires a larger and more committed open source project - single people will just run out of steam too quickly. This may be comparable to the creation of a Web browser (see the size of the Mozilla project) or a text processing system (see the size of the OpenOffice project).
Jeff also mentioned the need to create open video editor standards around playlist file formats etc. Possibly the Open Video Alliance could help. In any case, something has to be done in this space - maybe this would be a good topic to focus next year’s OVC on?
Monday’s Breakout Groups
The conference ended officially on Sunday night, but we had a third day of discussions / hackday at the wonderful New York Lawschool venue. We had collected issues of interest during the two previous days and organised the breakout groups on the morning (Schedule).
In the Content Protection/DRM session, Mark Watson from Netflix explained how their API works and that they believe that all we need in browsers is a secure way to exchange keys and an indicator of protection scheme is used - the actual protection scheme would not be implemented by the browser, but be provided by the underlying system (media framework/operating system). I think that until somebody actually implements something in a browser fork and shows how this can be done, we won’t have much progress. In my understanding, we may also need to disable part of the video API for encrypted content, because otherwise you can always e.g. grab frames from the video element into canvas and save them from there.
In the Playlists and Gapless Playback session, there was massive brainstorming about what new cool things can be done with the video element in browsers if playback between snippets can be made seamless. Further discussions were about a standard playlist file formats (such as XSPF, MRSS or M3U), media fragment URIs in playlists for mashups, and the need to expose track metadata for HTML5 media elements.
What more can I say? It was an amazing three days and the complexity of problems that we’re dealing with is a tribute to how far HTML5 and open video has already come and exciting news for the kind of applications that will be possible (both professional and community) once we’ve solved the problems of today. It will be exciting to see what progress we will have made by next year’s conference.
Thanks go to Google for sponsoring my trip to OVC.
The group has been created to work on many aspects of video text tracks of which captioning and the WebVTT format are key parts.
The main reason behind creating this group is to create a forum at the W3C for working on WebVTT to allow all browsers to support this format and be involved in its development.
We’ve not gone the full way to creating a Working Group, although that was the initial intention. We had objections from W3C members for going down that path, so are using the CG path for now.
This is actually a good thing because CGs are open for anyone to join, while WGs are only open to W3C members. The key difference is that specs coming out of WGs can become RECs (“standards”), while CG’s specs cannot.
If we eventually see a need to move WebVTT to a REC, that move will be straight forward, since there is a clear path for work to transition from a CG to a WG.
Curious about any new requirements that the TV community may have for HTML5 video, I attended the W3C Web and TV Workshop in Hollywood last week. It’s already the third of its kind and was also the largest to date showing an increasing interest of the TV community to converge with the Web community.
The Workshop Aim
I went into the Workshop not quite knowing what to expect. My previous contact with members of this community was restricted to email exchanges on the W3C Web and TV Interest Group (IG) mailing list. I knew there was some interest in video accessibility (well: particularly captions) and little knowledge of existing HTML5 specifications around text tracks and why the browsers were going with WebVTT. So I had decided to attend the workshop to get a better understanding of the community, it’s background, needs, and issues, and to hopefully teach some of the ways of HTML5. For that reason I had also submitted a WebVTT presentation/demo.
As it turned out, the workshop had as its key target the facilitation of communication between the TV and the HTML5 community. The aim was to identify features that need to be added to the HTML5 video element to satisfy the needs of the TV community. I obviously came to the right workshop.
The process that is being used by the W3C in the Interest Group is to have TV community members express their needs, then have HTML5 experts express how these needs can be satisfied with existing HTML5 features, then make trial implementations and identify any shortcomings, then move forward to progress these through HTML5 or HTML.next. This workshop clearly focused on the first step: expressing needs.
Often times it was painful for me to watch presenters defending their requirements and trying to impress on the audience how important a certain feature is to them when that features actually already has a HTML5 specification, but just not yet a browser implementations. That there were so few HTML5 video experts present and that they were given very little space to directly reply to the expressed needs and actually explain what is already possible (or specified to be possible) was probably one of the biggest drawbacks of the workshop.
To be fair, detailed technical discussions were not possible in a room with 150 attendees with a panel sitting at the front discussing topics and taking questions. Solving a use case with existing HTML5 markup and identifying the gaps requires smaller break-out groups of a maximum of maybe 20 people and sufficient HTML5 knowledge in the room. Ultimately they require a single person to try to implement it using JavaScript alone, and, failing that, writing browser extensions. Only such code actually proves that a feature is missing.
Now, the video features of HTML5 are still continuing to change almost on a daily basis. Much development is, for example, happening around real-time communication features and around the track element as we speak. So, focusing on further requirements finding around HTML5 video for now is probably a good thing.
The TV Community Approach
Before I move on to some of the topics covered by the workshop, I have to express some concern about the behaviour that I observed with lots of the TV community folks. Many people tried pushing existing solutions from other spaces into the Web unchanged with a claim of not re-inventing the wheel and following paved cowpaths, which are some of the underlying design principles for HTML5. I can understand where such behaviour originates thinking that having solved the same problems elsewhere before, those solutions should apply here, too. But I would like to warn people of this approach.
If we blindly apply solutions that were not developed for HTML5 into HTML we will end up with suboptimal solutions that will hurt us further down the track. The principles of not re-inventing the wheel and following paved cowpaths were introduced for features that were already implemented by browsers or in de-facto standard use by JavaScript libraries. They were not created for new features in HTML. The video element is a completely new feature in HTML thus everything around it is new.
I would therefore like to see some more respect given to HTML5 and the complexities involved in finding the best possible technical solutions for the Web given that the video element does not stand alone in HTML5, but is part of a much larger picture of technical capabilities on the Web where many of the requested features for TV applications may already be solved by existing HTML markup that is not part of the video element.
Also, HTML5 is not just about the HTML markup, but also about CSS and JavaScript and HTTP. There are several layers of technology involved in creating a Web application: not only a separation of work between client and servers, but also between the Operating System, the media framework, the browser, browser plugins, and JavaScript has to be balanced. To get this balance right is a fine art that will take many discussion, many experiments and sometimes several design approaches. We need patience and calm to work through this, not a rushed adoption of existing solutions from other spaces.
Session 1 / Content Provider and Consumer Perspective:
The sessions participants postulate that we will see the creation of application stores for TV applications similar to how we have experienced this for mobile phones and tablets. People enjoy collecting apps like they collect badges. Right now, the app store domain is dominated by native apps and now Web apps. The reason is that we haven’t got a standard platform for setting up Web app stores with Web apps that work in all browsers on all operating systems. Thus, developers have to re-deploy their app for many environments.
While essentially an orthogonal need to HTML standardisation, this seems to be one of the key issues that keep Web apps back from making big market inroads and W3C may do well in setting up a new WG to define a standard Web app manifest format and JS APIs.
Session 2+3 / Multi-screen TV in the Home Network:
Several technologies of hybrid TV broadcast and set-top-box Web content delivery were being pointed out, including the European HbbTV and the Japanese Hybridcast, the latter of which gave an in-depth demo.
Web purists would probably say that it would be simpler to just deliver all content over the Web and not have to worry about any further technical challenges encountered by having to synchronize content received via two vastly different delivery mechanisms. I personally believe this development is one of business models: we don’t yet know exactly how to earn money from TV content delivered over the Internet, but we do know how to do so with TV content. So, hybrids allow the continuation of existing income streams while allowing the features to be augmented with those people enjoy from the Internet.
Should requirements that emerge from such a use case for HTML5 video be taken seriously? I think they absolutely should. What I see happening is that a new way of using the Web is starting to emerge. The new way is video-focused rather than text-focused. We receive our Web content by watching video programming online - video channels, not Web pages are the core content that we consume in the living room. Video channels are where we start our browsing experience from. Search may still be our first point of call, but it will be search for video content or a video-centric app rather than search for a Web site.
And it will be a matter of many interconnected devices in the house that contribute to the experience: the 5.1 stereos that are spread all over the house and should receive our video’s sound, the different screens in the different areas of our house between which we move around, and remote controls, laptops or tablets that function as remote controls and preview stations and are used to determine our viewing experience and provide a back-channel to the publishers.
We have barely begun to identify how such interconnected devices within a home fit within the server-client-based view of the Web world, and the new Web Sockets functionality. The Home Networking Task Force of the Web and TV IG is looking at the issues and analysing existing protocols and standards that solve this picture. But I have a gnawing feeling that the best solution will be something new that is more Web-specific and fits better with the technology layers of the Web.
Session 4 / Synchronized Metadata:
The TV environment offers many data services, some of which have been legally prescribed. This session analysed TV needs and how they can be satisfied with current HTML5.
Subtitles and closed captioning support are one of the key requirements that have been legally prescribed to allow for equal access of non-native speakers, and blind and vision-impaired users to TV content. After demonstration of some key features defined into the HTML5 track element and the WebVTT format, it was generally accepted that HTML5 is making big progress in this space, in particular that browsers are in the process of implementing support for the track element. A concern still exists for complete coverage of all the CEA-608/708 features in WebVTT.
Further concern was raised for support of audio descriptions and audio translations, in particular since no browser has as yet committed to implementing the HTML5’s media multitrack API with the @mediagroup attribute. In this context I am excited to see first JavaScript polyfills emerge (see captionator.js & mediagroup.js).
Another concern was that many captions are actually delivered as raster images (in particular DVD captions) and how that would work in the Web context. The proposal was to use WebVTT and encode the raster images as data-URIs included in timed cues, then render them by JavaScript as an overlay. This is something to explore further.
Demos were shown using WebVTT to synchronize ads with videos, to display related metadata from a user’s life log with videos, to display thumbnails along a video’s timeline, and to show the rendering of text descriptions through screen readers. General agreement by the panel was that WebVTT offers many opportunities and that this area will continue to need further development and that we will see new capabilities on the Web around metadata that were not previously possible on TV.
Session 5 / Content Format and Codecs: DASH and Codec standards
The introduction of HTTP adaptive streaming into HTML5 was one of the core issues that kept returning in the discussions. This panel focused on MPEG DASH, but also mentioned the need for programmatic implementation of adaptive streaming functionality.
The work around MPEG DASH would require specifications of how to use DASH with WebM and Ogg Theora, as well as a specification of a HTML5 profile for DASH, which would limit the functionality possible in DASH files to the ones needed in a HTML5 video element. One criticism of DASH was its verbosity. Another was its unclear patent position. Panel attendees with included Qualcomm, Apple and Microsoft made very clear that their position is pro a royalty-free use of DASH.
The work around a programmatic implementation for adaptive streaming would require at least a JavaScript API to measure the quality of service of a presented video element and a JavaScript API to feed the video element with chunks of (encrypted) video content on the fly. Interestingly enough, there are existing experiments both around Video metrics and MediaSource extensions, so we can expect some progress in this space, even if these are not yet a strong focus of the HTML WG.
I would personally support the creation of Community Group at the W3C around HTTP adaptive streaming and DASH. I think it would work towards alleviating the perceived patent issues around DASH and allow the right members of the community to participate in preparing a specification for HTML5 without requiring them to become W3C members.
Session 6 / Content Protection and DRM
A core concern of the TV community is around content protection. The requirements in this space seem, however, very confused.
The key assumption here is that Web browsers should support the decoding of DRM-protected content in the HTML5 video element because the video element provides a desirable JavaScript API, accessibility features (the track element), default controls, and the possibility to synchronize multiple media elements. However, at the same time, the video element is part of the core content of a Web page and thus allows direct access to the image content in a canvas etc, so some of its functionality is not desirable.
The picture is further confused by requests for authentication, authorization, encryption, obfuscation, same-origin, secure transmission, secure decryption key delivery, unique content identification and other “content protection” techniques without a clear understanding of what is already possible on the Web and what requirements to content publishers actually have for delivering their content on the Web. This is further complicated by the fact that there are many competing solutions for DRM systems in the market with no clear standard that all browsers could support.
A thorough analysis of the technologies and solutions available in this space as well as an analysis of the needs for HTML5 is required before it becomes clear what solution HTML5 browsers may need to support. There seemed to be agreement in the group, though, that browsers would not need to implement DRM solutions, but rather only hand through the functionality of the platform on which they are running (including the media frameworks and operating system functionalities). How this is supposed to work was, however, unclear.
Session 7 / Web & TV: Additional Device & User Requirements
This was a catch-all session for topics that had not been addressed in other sessions. Among the topics addressed in this group were:
Parental Guidance: how to deal with ratings in an internationally inconsistent ratings landscape, how to deliver the ratings with the content, and how to enforce the viewing restrictions
Emergency Notifications: how to replicate on the Web the emergency notification functionality of TV by providing text overlays to alert users
TV channels: how to detect what channels of programming are available to users
Overall, the workshop was a worthwhile experience. It seems there is a lot of work still ahead for making HTML5 video the best it can be on the Web.
This year I’m really excited to announce that the workshop will be an integral part of the Open Video Conference on 10-12 September 2011.
FOMS 2011 will take place as the Open Media Developers track at OVC and I would like to see as many if not more open media software developers attend as we had in last year’s FOMS.
Why should you go?
Well, firstly of course the people. As in previous years, we will have some of the key developers in open media software attend - not as celebrities, but to work with other key developers on hard problems and to make progress.
Then, secondly we believe we have some awesome sessions in preparation:
I’m actually not quite satisfied with just these sessions. I’d like to be more flexible on how we make the three days a success for everyone. And this implies that there will continue to be room to add more sessions, even while at the conference, and create breakout groups to address really hard issues all the way through the conference.
I insist on this flexibility because I have seen in past years that the most productive outcomes are created by two or three people breaking away from the group, going into a corner and hacking up some demos or solutions to hard problems and taking that momentum away after the workshop.
To allow this to happen, we will have a plenary on the first day during which we will identify who is actually present at the workshop, what they are working on, what sessions they are planning on a attending, and what other topics they are keen to learn about during the conference that may not yet be addressed by existing sessions.
We’ll repeat this exercise on the Monday after all the rest of the conference is finished and we get a quieter day to just focus on being productive.
But is it worth the effort?
As in the past years, whether the workshop is a success for you depends on you and you alone. You have the power to direct what sessions and breakout groups are being created, and you have the possibility to find others at the workshop that share an interest and drag them away for some productive brainstorming or coding.
I’m going to make sure we have an adequate number of rooms available to actually achieve such an environment. I am very happy to have the support of OVC for this and I am assured we have the best location with plenty of space.
Trip sponsorships
As in previous FOMSes, we have again made sure that travel and conference sponsorship is available to community software developers that would otherwise not be able to attend FOMS. We have several such sponsorships and I encourage you to email the FOMS committee or OVC about it. Mention what you’re working on and what you’re interested to take away from OVC and we can give you free entry, hotel and flight sponsorship.
People have been asking me lots of questions about WebVTT (Web Video Text Tracks) recently. Questions about its technical nature such as: are the features included in WebVTT sufficient for broadcast captions including positioning and colors? Questions about its standardisation level: when is the spec officially finished and when will it move from the WHATWG to the W3C? Questions about implementation: are any browsers supporting it yet and how can I make use of it now?
I’m going to answer all of these questions in this post to make it more efficient than answering tweets, emails, and skype and other phone conference requests. It’s about time I do a proper post about it.
Implementations
I’m starting with the last area, because it is the simplest to answer.
No, no browser has as yet shipped support for the
However, you do not have to despair, because there are now a couple of JavaScript polyfill libraries for either just the track element or for video players with track support. You can start using these while you are waiting for the browsers to implement native support for the element and the file format.
Here are some of the libraries that I’ve come across that will support SRT and/or WebVTT (do leave a comment if you come across more):
Captionator - a polyfill for track and SRT parsing (WebVTT in the works)
js_videosub - a polyfill for track and SRT parsing
I am actually most excited about the work of Ronny Mennerich from LeanbackPlayer on WebVTT, since he has been the first to really attack full support of cue settings and to discuss with Ian, me and the WHATWG about their meaning. His review notes with visual description of how settings are to be interpreted and his demo will be most useful to authors and other developers.
Standardisation
Before we dig into the technical progress that has been made recently, I want to answer the question of “maturity”.
The WebVTT specification is currently developed at the WHATWG. It is part of the HTML specification there. When development on it started (under its then name WebSRT), it was also part of the HTML5 specification of the W3C. However, there was a concern that HTML5 should be independent of the chosen captioning format and thus WebVTT currently only exists at the WHATWG.
In recent months - and particularly since browser vendors have indicated that they will indeed implement support for WebVTT as their implementation of the
Many of the new features are about making the WebVTT format more useful for authoring and data management. The introduction of comments, inline CSS settings and default cue settings will help authors reduce the amount of styling they have to provide. File-wide metadata will help with the exchange of management information in professional captioning scenarios and archives.
But even without these new features, WebVTT already has all the features necessary to support professional captioning requirements. I’ve prepared a draft mapping of CEA-608 captions to WebVTT to demonstrate these capabilities (CEA-608 is the TV captioning standard in the US).
So, overall, WebVTT is in a great state for you to start implementing support for it in caption creation applications and in video players. There’s no need to wait any longer - I don’t expect fundamental changes to be made, but only new features to be added.
New WebVTT Features
This takes us straight to looking at the recently introduced new features.
Simpler File Magic: Whereas previously the magic file identifier for a WebVTT file was a single line with “WEBVTT FILE”. This has now been changed to a single line with just “WEBVTT”.
Cue Bold Span: The element has been introduced into WebVTT, thus aligning it somewhat more with SRT and with HTML.
CSS Selectors: The spec already allowed to use the names of tags, the classes of tags, and the voice annotations of tags as CSS selectors for ::cue. ID selector matching is now also available, where the cue identifier is used.
text-decoration support: The spec now also supports the CSS text-decoration property for WebVTT cues, allowing functionality such as blinking text and bold.
Further to this, the email identifies the means in which WebVTT is extensible:
Header area: The WebVTT header area is defined through the “WEBVTT” magic file identifier as a start and two empty lines as an end. It is possible to add into this area file-wide information header information.
Cues: Cues are defined to start with an optional identifier, and then a start/end time specification with ”—>” separator. They end with two empty lines. Cues that contain a ”—>” separator but don’t parse as valid start/end time are currently skipped. Such “cues” can be used to contain inline command blocks.
Inline in cues: Finally, within cues, everything that is within a “tag”, i.e. between "", and does not parse as one of the defined start or end tags is ignored, so we can use these to hide text. Further, text between such start and end tags is visible even if the tags are ignored, so wen can introduce new markup tags in this way.
Given this background, the following V2 extensions have been discussed:
Metadata: Enter name-value pairs of metadata into the header area, e.g.
Inline Cue Settings: Default cue settings can come in a “cue” of their own, e.g.
WEBVTTDEFAULTS --> D:vertical A:end00:00.000 --> 00:02.000This is vertical and end-aligned.00:02.500 --> 00:05.000As is this.DEFAULTS --> A:start00:05.500 --> 00:07.000This is horizontal and start-aligned.
Inline CSS: Since CSS is used to format cue text, a means to do this directly in WebVTT without a need for a Web page and external style sheet is helpful and could be done in its own cue, e.g.
Comments: Both, comments within cues and complete cues commented out are possible, e.g.
WEBVTT COMMENT --> 00:02.000 --> 00:03.000 two; this is entirely commented out 00:06.000 --> 00:07.000 this part of the cue is visible <! this part isn't > <and neither is this>
Finally, I believe we still need to add the following features:
Language tags: I’d like to add a language tag that allows to mark up a subpart of cue text as being in a different language. We need this feature for mixed-language cues (in particular where a different font may be necessary for the inline foreign-language text). But more importantly we will need this feature for cues that contain text descriptions rather than captions, such that a speech synthesizer can pick the correct language model to speak the foreign-language text. It was discussed that this could be done with a xxx type of markup.
Roll-up captions: When we use timestamp objects and the future text is hidden, then is un-hidden upon reaching its time, we should allow the cue text to scroll up a line when the un-hidden text requires adding a new line. This is the typical way in which TV live captions have been displayed and so users are acquainted with this display style.
Inline navigation: For chapter tracks the primary use of cues are for navigation. In other formats - in particular in DAISY-books for blind users - there are hierarchical navigation possibilities within media resources. We can use timestamp objects to provide further markers for navigation within cues, but in order to make these available in a hierarchical fashion, we will need a grouping tag. It would be possible to introduce a
Default caption width: At the moment, the default display size of a caption cue is 100% of the video’s width (height for vertical directions), which can be overruled with the “S” cue setting. I think it should by default rather be the width (height) of the bounding box around all the text inside the cue.
Aside from these changes to WebVTT, there are also some things that can be improved on the . I personally support the introduction of the source element underneath the track element, because that allows us to provide different caption files for different devices through the @media media queries attribute and it allows support for more than just one default captioning format. This change needs to be made soon so we don’t run into trouble with the currently empty track element.
I further think a oncuelistchange event would be nice as well in cases where the number of tracks is somehow changed - in particular when coming from within a media file.
Other than this, I’m really very happy with the state that we have achieved this far.
In the last months, we’ve been working hard at the WHATWG and W3C to spec out new HTML markup and a JavaScript interface for dealing with audio or video content that has more than just one audio and video track.
This is particularly relevant when a Web page author wants to add a sign language track to a video or audio resource for deaf people, or an audio description track (i.e. a sound track in which a speaker explains the key things that can be seen on screen) for blind people. It is also relevant when a Web page author wants to publish a video with multiple audio tracks that are each a different language dub for the video and can be used for less common cases such as a director’s comment track, or making available different camera angles for an event.
Just to be clear: this is not a means to introduce video editing functionality into the Web browser. If you want to do edits, you’re better off with an application that will eventually render a new piece of content and includes fancy transitions etc. Similarly, this is not a means to introduce mixing functionality (as in what DJs do when they play with multiple audio recordings). You’re better off with an actual audio mixing or DJ application that will provide you all sorts of amazing effects and filters.
So, multi-track is squarely focused on synchronizing alternative or additional tracks to a single resource with a single timeline to which all tracks are slaved.
Two means of publishing such multi-track media content are possible:
Of the video file formats that Web browsers support, WebM is currently not defined to contain more than one audio or video track. However, since WebM is using the Matroska container format, which supports multi-track, it is possible to extend WebM for multi-track resources. I have seen multitrack Ogg, MP4 and Matroska files in the wild and most media players support their display.
The specification that has gone into HTML5 to support in-band multi-track looks as follows:
You will notice that every audio and video track gets an index to address them. You can enable and disable individual audio tracks (via the enabled attribute) and you can select a single video track for display (via the selectedIndex attribute). This means that one or more audio tracks can be active at the same time (e.g. main audio and audio description), but only one video track will be active at a time (e.g. main video or sign language).
Through the id, kind, label and language attributes you can find out more about what actual content is available in the individual tracks so as to activate/deactivate them correctly and display the right information about them.
kind identifies the type of content that the track exposes such as “description” (for audio description), “sign” (for sign language), “main” (for the default displayed track), “translation” (for a dubbed audio track), and “alternative” (for an alternative to the default track).
label provides a human readable string that describes the content of the track aiming to be used in a menu.
id provides a short machine-readable string that can be used to construct a media fragment URI for the track. The use case for this will be discussed later.
language provides a machine-readable language code to identify which language is spoken or signed in an audio or sign language video track.
Example 1:
The following uses a video file that has a main video track, a main audio track in English and French, and an audio description track in English and French. (It likely also has caption tracks, but we will ignore text tracks for now.) This code sample switches the French audio tracks on and all other audio tracks off.
The following uses a audio file that has a main audio track in English, no main video track, but sign language video tracks in ASL (American Sign Language), BSL (British Sign Language), and ASF (Australian Sign Language). This code sample switches the Australian sign language track on and all other video tracks off.
If you have more tracks in both examples that conflict with your intentions, you may need to further filter your activation / deactivation code using the kind attribute.
2. Synchronized resources
Sometimes the production process of media creates not a single resource with multiple contained tracks, but multiple resources that all share the same timeline. This is particularly useful for the Web, because it means the user can download only the required resources, typically saving a substantial amount of bandwidth.
For this situation, an attribute called @mediagroup can be added in markup to slave multiple media elements together. This is administrated in the JavaScript API through a MediaController object, which provides events and attributes for the combined multi-track object.
The new IDL interfaces for HTMLMediaElement are as follows:
You will notice that the MediaController replicates some of the states and events of the slave media elements. In general the approach is that the attributes represent the summary state from all the elements and the writable attributes when set are handed through to all the slave elements.
Importantly, if the individual media elements have @controls activated, then the displayed controls interact with the MediaController thus allowing synchronized playback and interaction with the combined multi-track object.
Example 3:
The following uses a video file that has a main video track, a main audio track in English. There is another video file with the ASL sign language for the video, and an audio file with the audio description in English. This code sample creates controls on the first file, which then also control the audio description and the sign language video, neither of which have controls. Since the audio description doesn’t have controls, it doesn’t get visually displayed. The sign language video will just sit next to the main video without controls.
We now accompany a main video with three sign language video tracks in ASL, BSL and ASF. We could just do this in JavaScript and replace the currentSrc of a second video element with the links to BSL and ASF as required, but then we need to run our own media controls to list the available tracks. So, instead, we create a video element for each one of the tracks and use CSS to remove the inactive ones from the page layout. The code sample activates the ASF track and deactivates the other sign language tracks.
In this final example we look at what to do when we have a in-band multi-track resource with multiple video tracks that should all be displayed on screen. This is not a simple problem to solve because a video element is only allowed to display a single video track at a time. Therefore for this problem you need to use both approaches: in-band and synchronized resources.
We take a in-band multitrack resource with a main video and audio track and three sign language tracks in ASL, BSL and ASF. The second resource will be made up from the URI of the first resource with a media fragment address of the sign language tracks. (If required, these can be discovered using the getID() function on the first resource.) The markup will look as follows:
Note that with multiple video elements you can always style them in the way that you want them displayed on screen. E.g. if you want a picture-in-picture display, you scale the second video down and absolutely position it on top of the first one in the appropriate location. You can even grab the second video into a canvas, chroma-key your sign language speaker on a green or blue screen and remove that background through some canvas processing before popping it on top of the video.
The world is all yours!
HOWEVER: There is one big caveat on all these specs - while they have all found entry into the HTML5 specification, it would be expecting a bit much to have browser support already. :-)
UPDATE 23 July 2014: I’ve just changed this to use the latest spec, which should also at least partially be implemented already.
Note: there is something weird going on with the wordpress plugins site, which still shows version 0.7 as the current one, but when you download it, it gets the latest version 0.12. If somebody knows how to fix this, that would be awesome. I think it also stops people from auto-updating this plugin, which is sad with this many improvements. (I think I fixed it by actually changing the version number in the external-videos.php file - how silly of me - and thanks to the Wordpress Forum person who pointed it out to me! Download 0.13 now.)
On Wednesday, I gave a talk at Google about WebVTT, the Web Video Text Track file format that is under development at the WHATWG for solving time-aligned text challenges for video.
I started by explaining all the features that WebVTT supports for captions and subtitles, mentioned how WebVTT would be used for text audio descriptions and navigation/chapters, and explained how it is included into HTML5 markup, such that the browser provides some default rendering for these purposes. I also mentioned the metadata approach that allows any timed content to be included into cues.
The talk slides include a demo of how the
The talk was recorded and has been made available as a Google Tech talk with captions and also a separate version with extended audio descriptions.
The slides of the talk are also available (best to choose the black theme).
At the recent Linux conference in Brisbane, Australia, I promised a free copy of my book to the person that could send me the best idea for an HTML5 video application. I later also tweeted about it.
While I didn’t get many emails, I am still impressed by the things people want to do. Amongst the posts were the following proposals:
Develop a simple video cutting tool to, say setting cut points and having a very simple backend taking the cut points and generating quick enough output. The cutting doesn’t need to retranscode.
Use HTML5 video, especially the tracking between video and text, to better present video from the NZ Parliament.
Making a small MMO game using WebGL, HTML5 audio and WebSockets. I also want to use the same code for desktop and web.
These are all awesome ideas and I found it really hard to decide whom to give the free book to. In the end, I decided to give it to Brian McKenna, who is working on the MMO game - simply because it it is really pushing the boundaries of several HTML5 technologies.
To everyone else: the book is actually not that expensive to buy from APRESS or Amazon and you can get the eBook version there, too.
Thanks to everyone who started really thinking about this and sent in a proposal!
Working in the WHAT WG and the W3C HTML WG, you sometimes forget that all the things that are being discussed so heatedly for standardization are actually leading to some really exciting new technologies that not many outside have really taken note of yet.
This week, during the Australian Linux Conference in Brisbane, I’ve been extremely lucky to be able to show off some awesome new features that browser vendors have implemented for the audio and video elements. The feedback that I got from people was uniformly plain surprise - nobody expected browser to have all these capabilities.
The examples that I showed off have mostly been the result of working on a book for almost 9 months of the past year and writing lots of examples of what can be achieved with existing implementations and specifications. They have been inspired by diverse demos that people made in the last years, so the book is linking to many more and many more amazing demos.
Incidentally, I promised to give a copy of the book away to the person with the best idea for a new Web application using HTML5 media. Since we ran out of time, please shoot me an email or a tweet (@silviapfeiffer) within the next 4 weeks and I will send another copy to the person with the best idea. The copy that I brought along was given to a student who wanted to use HTML5 video to display on surfaces of 3D moving objects.
I further gave a brief lightning talk about “HTML5 Media Accessibility Update”. I am expecting lots to happen on this topic during this year.
Finally, I gave a presentation today on “The Latest and Coolest in HTML5 Media” with a strong focus on video, but also touching on audio and media accessibility.
The talks were streamed live - congrats to Ryan Verner for getting this working with support from Ben Hutchings from DebConf and the rest of the video team. The videos will apparently be available from http://linuxconfau.blip.tv/ in the near future.
In the past week, I was invited to an IBM workshop on audio/text descriptions for video in Japan. Geoff Freed and Trisha O’Connell from WGBH, and Michael Evans from BBC research were the other invited experts to speak about the current state of video accessibility around the world and where things are going in TV/digital TV and the Web.
The two day workshop was very productive. The first day was spent with presentations which were open to the public. A large vision-impaired community attended to understand where technology is going. It was very humbling to be part of an English-spoken workshop in Japan, where much of the audience is blind, but speaks English much better than my average experience with English in Japan. I met many very impressive and passionate people that are creating audio descriptions, adapting NVDA for the Japanese market, advocating to Broadcasters and Government to create more audio descriptions, and perform fundamental research for better tools to create audio descriptions. My own presentation was on “HTML5 Video Descriptions”.
On the second day, we only met with the IBM researchers and focused discussions on two topics:
How to increase the amount of video descriptions
HTML5 specifications for video descriptions
The first topic included concerns about guidelines for description authoring by beginners, how to raise awareness, who to lobby, and what production tools are required. I personally was more interested in the second topic and we moved into a smaller breakout group to focus on these discussions.
HTML5 specifications for video descriptions Two topics were discussed related to video descriptions: text descriptions and audio descriptions. Text descriptions are descriptions authored as time-aligned text snippets and read out by a screen reader. Audio descriptions are audio recordings either of a human voice or even of a TTS (text-to-speech) synthesis - in either case, they are audio samples.
For a screen reader, the focus was actually largely on NVDA and people were very excited about the availability of this open source tool. There is a concern about how natural-sounding a screen reader can be made and IBM is doing much research there with some amazing results. In user experiment between WGBH and IBM they found that the more natural the voice sounds, the more people comprehend, but between a good screen reader and an actual human voice there is not much difference in the comprehension level. Broadcasters and other high-end producers are unlikely to accept TTS and will prefer the human voice, but for other materials - in particular for the large majority of content on the Web - TTS and screen readers can make a big difference.
An interesting lesson that I learnt was that video descriptions can be improved by 30% (i.e. 30% better comprehension) if we introduce extended descriptions, i.e. descriptions that can pause the main video to allow for a description be read for something that happens in the video, but where there is no obvious pause to read out the description. So, extended descriptions are one of the major challenges to get right.
We then looked at the path that we are currently progressing on in HTML5 with WebSRT, the TimedTrack API, the
For text descriptions we identified a need for the following:
extension marker on cues: often it is very clear to the author of a description cue that there is no time for the cue to be read out in parallel to the main audio and the video needs to be paused. The proposal is for introduction of an extension marker on the cue to pause the video until the screen reader is finished. So, a speech-complete event from the screen reader API needs to be dealt with. To make this reliable, it might make sense to put a max duration on the cue so the video doesn’t end up waiting endlessly in case the screen reader event isn’t fired. The duration would be calculated based on a typical word speaking rate.
importance marker on cues: the duration of all text cues being read out by screen readers depends on the speed set-up of the screen reader. So, even when a cue has been created for a given audio break in the video, it may or may not fit into this break. For most cues it is important that they are read out completely before moving on, but for some it’s not. So, an importance maker could be introduced that determines whether a video stops at the end of the cue to allow the screen reader to finish, or whether the screen reader is silenced at that time no matter how far it has gotten.
ducking during cues: making the main audio track quieter in relation to the video description for the duration of a cue such as to allow the comprehension of the video description cue is important for comprehension
voice hints: an instruction at the beginning of the text description file for what voice to choose such that it won’t collide with e.g. the narrator voice of a video - typically the choice will be for a female voice when the narrator is male and the other way around - this will help initialize the screen reader appropriately
speed hints: an indicator at the beginning of a text description toward what word rate was used as the baseline for the timing of the cue durations such that a screen reader can be initialized with this
synthesis directives: while not a priority, eventually it will make for better quality synchronized text if it is possible to include some of the typical markers that speech synthesizers use (see e.g. SSML or speech CSS), including markers for speaker change, for emphasis, for pitch change and other prosody. It was, in fact, suggested that the CSS3’s speech module may be sufficient in particular since Opera already implements it.
This means we need to consider extending WebSRT cues with an “extension” marker and an “importance” marker. WebSRT further needs header-type metadata to include a voice and a speed hint for screen readers. The screen reader further needs to work more closely with the browser and exchange speech-complete events and hints for ducking. And finally we may need to allow for CSS3 speech styles on subparts of WebSRT cues, though I believe this latter one is not of high immediate importance.
For audio descriptions we identified a need for:
external/in-band descriptions: allowing external or in-band description tracks to be synchronized with the main video. It would be assumed in this case that the timeline of the description track is identical to the main video.
extended external descriptions: since it’s impossible to create in-band extended descriptions without changing the timeline of the main video, we can only properly solve the issue of extended audio descriptions through external resources. One idea that we came up with is to use a WebSRT file with links to short audio recordings as external extended audio descriptions. These can then be synchronized with the video and pause the video at the correct time etc through JavaScript. This is probably a sufficient solution for now. It supports both, sighted and vision-impaired users and does not extend the timeline of the original video. As an optimization, we can also do this through a single “virtual” resource that is a concatenation of the individual audio cues and is addressed through the WebSRT file with byte ranges.
ducking: making the main audio track quieter in relation to the video description for the duration of a cue such as to allow the comprehension of the video description cue is important for comprehension also with audio files, though it may be more difficult to realize
separate loudness control: making it possible for the viewer to separately turn the loudness of an audio description up/down in comparison to the main audio
For audio descriptions, we saw the need for introduction of a multitrack video API and markup to synchronize external audio description tracks with the main video. Extended audio descriptions should be solved through JavaScript and hooking up through the TimedTrack API, so mostly rolling it by hand at this stage. We will see how that develops in future. Ducking and separate loudness controls are equally needed here, but we do need more experiments in this space.
Finally, we discussed general needs to locate accessibility content such as audio descriptions by vision-impaired user:
the need for accessible user menus to turn on/off accessibility content
the introduction of dedicated and standardized keyboard short-cuts to turn on and manipulate the volume of audio descriptions (and captions)
the introduction of user preferences for automatically activating accessibility content; these could even learn from current usage, such that if a user activates descriptions for a video on one Website, the preferences pick this up; different user profiles are already introduced by ISO in “Access for all” and used in websites such as teachersdomain
means to generally locate accessibility content on the web, such as fields in search engines and RSS feeds
more generally there was a request to have caption on/off and description on/off buttons be introduced into remote controls of machines, which will become prevalent with the increasing amount of modern TV/Internet integrated devices
Overall, the workshop was a great success and I am keen to see more experimentation in this space. I also hope that some of the great work that was shown to us at IBM with extended descriptions and text descriptions will become available - if only as screencasts - so we can all learn from it to make better standards and technology.
I wanted to give people an introduction into how to use these elements while at the same time stirring their imagination as to the design possibilities now that these elements are available natively in browsers. I re-used some of the demos that I have put together for the book that I am currently writing, added some of the cool stuff that others have done and finished off with an outlook towards what new features will probably arrive next.
“Slides” are now available, which are really just a Web page with some demos that work in modern browsers.
At this week’s FOMS in New York we had one over-arching topic that seemed to be of interest to every single participant: how to do adaptive bitrate streaming over HTTP for open codecs. On the first day, there was a general discussion about the advantages and disadvantages of adaptive HTTP streaming, while on the second day, we moved towards designing a solution for Ogg and WebM. While I didn’t attend all the discussions, I want to summarize the insights that I took out of the days in this blog post and the alternative implementation strategies that were came up with.
Use Cases for Adaptive HTTP Streaming
Streaming using RTP/RTSP has in the past been the main protocol to provide live video streams, either for broadcast or for real-time communication. It has been purpose-built for chunked video delivery and has features that many customers want, such as the ability to encrypt the stream, to tell players not to store the data, and to monitor the performance of the stream such that its bandwidth can be adapted. It has, however, also many disadvantages, not least that it goes over ports that normal firewalls block and thus is rather difficult to deploy, but also that it requires special server software, a client that speaks the protocol, and has a signalling overhead on the transport layer for adapting the stream.
RTP/RTSP has been invented to allow for high quality of service video consumption. In the last 10 years, however, it has become the norm to consume “canned” video (i.e. non-live video) over HTTP, making use of the byte-range request functionality of HTTP for seeking. While methods have been created to estimate the size of a pre-buffer before starting to play back in order to achieve continuous playback based on the bandwidth of your pipe at the beginning of downloading, not much can be done when one runs out of pre-buffer in the middle of playback or when the CPU on the machine doesn’t manage to catch up with decoding of the sheer amount of video data: your playback stops to go into re-buffering in the first case and starts to become choppy in the latter case.
An obvious approach to improving this situation is the scale the bandwidth of the video stream down, potentially even switch to a lower resolution video, right in the middle of playback. Apple’s HTTP live streaming, Microsoft’s Smooth Streaming, and Adobe’s Dynamic Streaming are all solutions in this space. Also, ISO/MPEG is working on DASH (Dynamic Adaptive Streaming over HTTP) is an effort to standardize the approach for MPEG media. No solution yets exist for the open formats within Ogg or WebM containers.
Some features of HTTP adaptive streaming are:
Enables adaptation of downloading to avoid continuing buffering when network or machine cannot cope.
Gapless switching between streams of different bitrate.
No special server software is required - any existing Web Server can be used to provide the streams.
The adaptation comes from the media player that actually knows what quality the user experiences rather than the network layer that knows nothing about the performance of the computer, and can only tell about the performance of the network.
Adaptation means that several versions of different bandwidth are made available on the server and the client switches between them based on knowledge it has about the video quality that the user experiences.
Bandwidth is not wasted by downloading video data that is not being consumed by the user, but rather content is pulled moments just before it is required, which works both for the live and canned content case and is particularly useful for long-form content.
Viability
In discussions at FOMS it was determined that mid-stream switching between different bitrate encoded audio files is possible. Just looking at the PCM domain, it requires stitching the waveform together at the switch-over point, but that is not a complex function. To be able to do that stitching with Vorbis-encoded files, there is no need for a overlap of data, because the encoded samples of the previous window in a different bitrate page can be used as input into the decoding of the current bitrate page, as long as the resulting PCM samples are stitched.
For video, mid-stream switching to a different bitrate encoded stream is also acceptable, as long as the switch-over point adheres to a keyframe, which can be independently decoded.
Thus, the preparation of the alternative bitstream videos requires temporal synchronisation of keyframes on video - the audio can deal with the switch-over at any point. A bit of intelligent encoding is thus necessary - requiring the encoding pipeline to provide regular keyframes at a certain rate would be sufficient. Then, the switch-over points are the keyframes.
Technical Realisation
With the solutions from Adobe, Microsoft and Apple, the technology has been created such there are special tools on the server that prepare the content for adaptive HTTP streaming and provide a manifest of the prepared content. Typically, the content is encoded in versions of different bitrates and the bandwidth versions are broken into chunks that can be decoded independently. These chunks are synchronised between the different bitrate versions such that there are defined switch-over points. The switch-over points as well as the file names of the different chunks are documented inside a manifest file. It is this manifest file that the player downloads instead of the resource at the beginning of streaming. This manifest file informs the player of the available resources and enables it to orchestrate the correct URL requests to the server as it progresses through the resource.
At FOMS, we took a step back from this approach and analysed what the general possibilities are for solving adaptive HTTP streaming. For example, it would be possible to not chunk the original media data, but instead perform range requests on the different bitrate versions of the resource. The following options were identified.
Chunking
With Chunking, the original bitrate versions are chunked into smaller full resources with defined switch-over points. This implies creation of a header on each one of the chunks and thus introduces overhead. Assuming we use 10sec chunks and 6kBytes per chunk, that results in 5kBit/sec extra overhead. After chunking the files this way, we provide a manifest file (similar to Apple’s m3u8 file, or the SMIL-based manifest file of Microsoft, or Adobe’s Flash Media Manifest file). The manifest file informs the client about the chunks and the switch-over points and the client requests those different resources at the switch-over points.
Disadvantages:
Header overhead on the pipe.
Switch-over delay for decoding the header.
Possible problem with TCP slowstart on new files.
A piece of software is necessary on server to prepare the chunked files.
A large amount of files to manage on the server.
The client has to hide the switching between full resources.
Advantages:
Works for live streams, where increasing amounts of chunks are written.
Works well with CDNs, because mid-stream switching to another server is easy.
Chunks can be encoded such that there is no overlap in the data necessary on switch-over.
May work well with Web sockets.
Follows the way in which proprietary solutions are doing it, so may be easy to adopt.
If the chunks are concatenated on the client, you get chained Ogg files (similar concept in WebM?), which are planned to be supported by Web browsers and are thus legal files.
Chained Chunks
Alternatively to creating the large number of files, one could also just create the chained files. Then, the switch-over is not between different files, but between different byte ranges. The headers still have to be read and parsed. And a manifest file still has to exist, but it now points to byte ranges rather than different resources.
Advantages over Chunking:
No TCP-slowstart problem.
No large number of files on the server.
Disadvantages over Chunking:
Mid-stream switching to other servers is not easily possible - CDNs won’t like it.
Doesn’t work with Web sockets as easily.
New approach that vendors will have to grapple with.
Virtual Chunks
Since in Chained Chunks we are already doing byte-range requests, it is a short step towards simply dropping the repeating headers and just downloading them once at the beginning for all possible bitrate files. Then, as we seek to different positions in “the” file, the byte range of the bitrate version that makes sense to retrieve at that stage would be requested. This could even be done with media fragment URIs, through addressing with time ranges is less accurate than explicit byte ranges.
In contrast to the previous two options, this basically requires keeping n different encoding pipelines alive - one for every bitrate version. Then, the byte ranges of the chunks will be interpreted by the appropriate pipeline. The manifest now points to keyframes as switch-over points.
Advantage over Chained Chunking:
No header overhead.
No continuous re-initialisation of decoding pipelines.
Disadvantages over Chained Chunking:
Multiple decoding pipelines need to be maintained and byte ranges managed for each.
Unchunked Byte Ranges
We can even consider going all the way and not preparing the alternative bitrate resources for switching, i.e. not making sure that the keyframes align. This will then require the player to do the switching itself, determine when the next keyframe comes up in its current stream then seek to that position in the next stream, always making sure to go back to the last keyframe before that position and discard all data until it arrives at the same offset.
Disadvantages:
There will be an overlap in the timeline for download, which has to be managed from the buffering and alignment POV.
Overlap poses a challenge of downloading more data than necessary at exactly the time where one doesn’t have bandwidth to spare.
Requires seeking.
Messy.
Advantages:
No special authoring of resources on the server is needed.
Requires a very simple manifest file only with a list of alternative bitrate files.
Final concerns
At FOMS we weren’t able to make a final decision on how to achieve adaptive HTTP streaming for open codecs. Most agreed that moving forward with the first case would be the right thing to do, but the sheer number of files that can create is daunting and it would be nice to avoid that for users.
Other goals are to make it work in stand-alone players, which means they will need to support loading the manifest file. And finally we want to enable experimentation in the browser through JavaScript implementation, which means there needs to be an interface to provide the quality of decoding to JavaScript. Fortunately, a proposal for such a statistics API already exists. The number of received frames, the number of dropped frames, and the size of the video are the most important statistics required.
Today I gave a talk at the Open Video Conference about the state of the specifications in HTML5 for media accessibility.
To be clear: at this exact moment, there is no actual specification text in the W3C version of HTML5 for media accessibility. There is, however, some text in the WHATWG version, providing a framework for text-based alternative content. Other alternative content still requires new specification text. Finally, there is no implementation in any browser yet for media accessibility, but we are getting closer. As browser vendors are moving towards implementing support for the WHATWG specifications of the , the TimedTrack JavaScript API, and the WebSRT format, video sites can also experiment with the provided specifications and contribute feedback to improve the specifications.
Attached are my slides from today’s talk. I went through some of the key requirements of accessibility users and showed how they are being met by the new specifications (in green) or could be met with some still-to-be-developed specifications (in blue). Note that the talk and slides focus on accessibility needs, but the developed technologies will be useful far beyond just accessibility needs and will also help satisfy other needs, such as the needs of internationalization (through subtitles), of exposing multitrack audio/video (through the JavaScript API), of providing timed metadata (through WebSRT), or even of supporting Karaoke (through WebSRT). In the tables on the last two pages I summarize the gaps in the specifications where we will be working on next and also show what is already possible with given specifications.
Over the last two days we had the Open Subtitles Summit here in New York. It was very exciting to feel the energy in the room to make a change to media accessibility - I am sure we will see much development over the next 12 months. We spoke much about HTML5 video and standards and had many discussions about subtitles, captions, and other accessibility information.
On Wednesday we had a discussion about metadata and I quickly realized that “your metadata is not my metadata”: everyone used the word for something different. So, I suggested to have a metadata discussion on Thursday where we would put a structure onto all of this, identify what kinds of metadata we have and whether and how it should be supported in HTML5 standards.
Our basic findings are very simple and widely accepted. There are three fundamentally different types of metadata:
Technical metadata about video: information about the format of the resource - things that can be determined automatically and are non-controversial, such as the width, height, framerate, audio sample rate etc. This information can be used to, e.g. decide if a video is appropriate for a certain device.
Semantic metadata about video: semantic information about the video resource - e.g. license, author, publication date, version, attribution, title, description. This information is good for search and identification.
Timed semantic metadata: semantic information that is associated with time intervals of the video, not with the full video - e.g. active speaker, location, date-time, objects.
As we talked about this further, however, we identified subclasses of these generic types that are very important to identify because they will be handled differently.
We found that semantic metadata can be separated into universal metadata and domain-specific metadata. Universal metadata is semantic metadata that can basically be applied to any content. There is very little of that and the W3C Media Annotations WG has done a pretty good job in identifying it. Domain-specific metadata is such metadata that only applies to some content, e.g. all the videos about sports have metadata such as game scores, players, or type of sport.
As for adding such metadata into media resources, we discussed that it makes sense to have the universal metadata explicitly spelled out and to have a generic means to associate name-value pairs with resource. Of course it will all be stored in databases, but there was also a requirement to have it encoded into the media resource - and in our discussion case: into external captions or subtitle files.
As for timed metadata - it is possible to separate this into metadata that is only relevant as part of a subtitle or caption file, because the metadata relates to a certain word or a word sequence, and into independent timed metadata that can be stored in, e.g. JSON or some similar format.
Since we are particularly interested in subtitles and captions, the timed metadata that is associated with words or word sequences is particularly important. The most natural metadata that is useful as part of subtitles is of course speaker segmentation. We also identified that hyperlinks to related content are just as important, since it can enable applications such as popcorn.js.
Potentially there is a use for metadata association with any sequence of words in a caption or subtitle, which could be satisfied with the use of a generic markup element for a sequence of words, such that microdata or RDFa may get associated. A request for such a generic means of associating metadata was made. However, the need for it still has to be confirmed with good use cases - the breakout group was out of time as we came to this point. So, leave your ideas for use cases in the requirements - they will help shape standards.
What I want to do here is to summarize what was introduced, together with the improvements that I and some others have proposed in follow-upemails, and list some of the media accessibility needs that we are not yet dealing with.
For those wanting to only selectively read some sections, here is a clickable table of contents of this rather long blog post:
The first and to everyone probably most surprising part is the new file format that is being proposed to contain out-of-band time-synchronized text for video. A new format was necessary after the analysis of all relevant existing formats determined that they were either insufficient or hard to use in a Web environment.
The new format is called WebSRT and is an extension to the existing SRT SubRip format. It is actually also the part of the new specification that I am personally most uncomfortable with. Not that WebSRT is a bad format. It’s just not sufficient yet to provide all the functionality that a good time-synchronized text format for Web media should. Let’s look at some examples.
WebSRT is composed of a sequence of timed text cues (that’s what we’ve decided to call the pieces of text that are active during a certain time interval). Because of its ancestry of SRT, the text cues can optionally be numbered through. The content of the text cues is currently allowed to contain three different types of text: plain text, minimal markup, and anything at all (also called “metadata”).
In its most simple form, a WebSRT file is just an ordinary old SRT file with optional cue numbers and only plain text in cues:
1 00:00:15.00 --> 00:00:17.95 At the left we can see... 2 00:00:18.16 --> 00:00:20.08 At the right we can see the... 3 00:00:20.11 --> 00:00:21.96 ...the head-snarlers
A bit of a more complex example results if we introduce minimal markup:
00:00:15.00 --> 00:00:17.95 A:start Auf der <i>linken</i> Seite sehen wir... 00:00:18.16 --> 00:00:20.08 A:end Auf der <b>rechten</b> Seite sehen wir die.... 00:00:20.11 --> 00:00:21.96 A:end <1>...die Enthaupter. 00:00:21.99 --> 00:00:24.36 A:start <2>Alles ist sicher. Vollkommen <b>sicher</b>.
and add to this a CSS to provide for some colors and special formatting:
Minimal markup accepts , , and a timestamp in <>, providing for italics, bold, and ruby markup as well as karaoke timestamps. Any further styling can be done using the CSS pseudo-elements ::cue and ::cue-part, which accept the features ‘color’, ‘text-shadow’, ‘text-outline’, ‘background’, ‘outline’, and ‘font’.
Note that positioning requires some special notes at the end of the start/end timestamps which can provide for vertical text, line position, text position, size and alignment cue setting. Here is an example with vertically rendered Chinese text, right-aligned at 98% of the video frame:
Finally, WebSRT files can be authored with abstract metadata inside cues, which practically means anything at all. Here’s an example with HTML content:
00:00:15.00 --> 00:00:17.95 A:start <img src="pic1.png"/>Auf der <i>linken</i> Seite sehen wir... 00:00:18.16 --> 00:00:20.08 A:end <img src="pic2.png"/>Auf der <b>rechten</b> Seite sehen wir die.... 00:00:20.11 --> 00:00:21.96 A:end <img src="pic3.png"/>...die <a href="http://members.chello.nl/j.kassenaar/elephantsdream/subtitles.html">Enthaupter</a>. 00:00:21.99 --> 00:00:24.36 A:start <img src="pic4.png"/>Alles ist <mark>sicher</mark>.<br/>Vollkommen <b>sicher</b>.
Here is another example with JSON in the cues:
00:00:00.00 --> 00:00:44.00 { slide: intro.png, title: "Really Achieving Your Childhood Dreams" by Randy Pausch, Carnegie Mellon University, Sept 18, 2007 } 00:00:44.00 --> 00:01:18.00 { slide: elephant.png, title: The elephant in the room... } 00:01:18.00 --> 00:02:05.00 { slide: denial.png, title: I'm not in denial... }
What I like about WebSRT:
it allows for all sorts of different content in the text cues - plain text is useful for texted audio descriptions, minimal markup is useful for subtitles, captions, karaoke and chapters, and “metadata” is useful for, well, any data.
it can be easily encapsulated into media resources and thus turned into in-band tracks by regarding each cue as a data packet with time stamps.
it is not verbose
Where I think WebSRT still needs improvements:
break with the SRT history: since WebSRT and SRT files are so different, WebSRT should get its own MIME type, e.g. text/websrt, and file extensions, e.g. .wsrt; this will free WebSRT for changes that wouldn’t be possible by trying to keep conformant with SRT
introduce some header fields into WebSRT: the format needs
file-wide name-value metadata, such as author, date, copyright, etc
language specification for the file as a hint for font selection and speech synthesis
a possibility for style sheet association in the file header
a means to identify which parser is required for the cues
a magic identifier and a version string of the format
allow innerHTML as an additional format in the cues with the CSS pseudo-elements applying to all HTML elements
allow full use of CSS instead of just the restricted features and also use it for positioning instead of the hard to understand positioning hints
on the minimum markup, provide a neutral structuring element such as <span @id @class @lang> to associate specific styles or specific languages with a subpart of the cue
Note that I undertook some experiments with an alternative format that is XML-based and called WMML to gain most of these insights and determine the advantages/disadvantages of a xml-based format. The foremost advantage is that there is no automatism with newlines and displayed new lines, which can make the source text file more readable. The foremost disadvantages are verbosity and that there needs to be a simple encoding step to remove all encapsulating header-type content from around the timed text cues before encoding it into a binary media resource.
Now that we have a timed text format, we need to be able to associate it with a media resource in HTML5. This is what the was introduced for. It associates the timestamps in the timed text cues with the timeline of the video resource. The browser is then expected to render these during the time interval in which the cues are expected to be active.
Here is an example for how to associate multiple subtitle tracks with a video:
In this case, the UA is expected to provide a text menu with a subtitle entry with these three tracks and their label as part of the video controls. Thus, the user can interactively activate one of the tracks.
Here is an example for multiple tracks of different kinds:
In this case, the UA is expected to provide a text menu with a list of track kinds with one entry each for subtitles, captions and descriptions through the controls. The chapter tracks are expected to provide some sort of visual subdivision on the timeline and the metadata tracks are not exposed visually, but are only available through the JavaScript API.
Here are several ideas for improving the
karaoke and lyrics are supported by WebSRT, but aren’t in the HTML5 spec as track kinds - they should be added and made visible like subtitles or captions.
This is where we take an extra step and move to a uniform handling of both in-band and out-of-band timed text tracks. Futher, a third type of timed text track has been introduced in the form of a MutableTimedTrack - i.e. one that can be authored and added through JavaScript alone.
The JavaScript API that is exposed for any of these track type is identical. A media element now has this additional IDL interface:
interface HTMLMediaElement : HTMLElement {... readonly attribute TimedTrack[] tracks; MutableTimedTrack addTrack(in DOMString label, in DOMString kind, in DOMString language);};
A media element thus manages a list of TimedTracks and provides for adding TimedTracks through addTrack().
The timed tracks are associated with a media resource in the following order:
The
Tracks created through the addTrack() method, in the order they were added, oldest first.
In-band timed text tracks, in the order defined by the media resource’s format specification.
The IDL interface of a TimedTrack is as follows:
interface TimedTrack { readonly attribute DOMString kind; readonly attribute DOMString label; readonly attribute DOMString language; readonly attribute unsigned short readyState; attribute unsigned short mode; readonly attribute TimedTrackCueList cues; readonly attribute TimedTrackCueList activeCues; readonly attribute Function onload; readonly attribute Function onerror; readonly attribute Function oncuechange;};
The first three capture the value of the @kind, @label and @srclang attributes and are provided by the addTrack() function for MutableTimedTracks and exposed from metadata in the binary resource for in-band tracks.
The readyState captures whether the data is available and is one of “not loaded”, “loading”, “loaded”, “failed to load”. Data is only availalbe in “loaded” state.
The mode attribute captures whether the data is activate to be displayed and is one of “disabled”, “hidden” and “showing”. In the “disabled” mode, the UA doesn’t have to download the resource, allowing for some bandwidth management.
The cues and activeCues attributes provide the list of parsed cues for the given track and the subpart thereof that is currently active.
The onload, onerror, and oncuechange functions are event handlers for the load, error and cuechange events of the TimedTrack.
Individual cues expose the following IDL interface:
The @track attribute links the cue to its TimedTrack.
The @id, @startTime, @endTime attributes expose a cue identifier and its associated time interval. The getCueAsSource() and getCueAsHTML() functions provide either an unparsed cue text content or a text content parsed into a HTML DOM subtree.
The @pauseOnExit attribute can be set to true/false and indicates whether at the end of the cue’s time interval the media playback should be paused and wait for user interaction to continue. This is particularly important as we are trying to support extended audio descriptions and extended captions.
The onenter and onexit functions are event handlers for the enter and exit events of the TimedTrackCue.
The @direction, @snapToLines, @linePosition, @textPosition, @size, @alignment and @voice attributes expose WebSRT positioning and semantic markup of the cue.
My only concerns with this part of the specification are:
The WebSRT-related attributes in the TimedTrackCue are in conflict with CSS attributes and really should not be introduced into HTML5, since they are WebSRT-specific. They will not exist in other types of in-band or out-of-band timed text tracks. As there is a mapping to do already, why not rely on already available CSS features.
There is no API to expose header-specific metadata from timed text tracks into JavaScript. This such as the copyright holder, the creation date and the usage rights of a timed text track would be useful to have available. I would propose to add a list of name-value metadata elements to the TimedTrack API.
In addition, I would propose to allow media fragment hyperlinks in a
The third part of the timed track framework deals with how to render the timed text cues in a Web page. The rendering rules are explained in the HTML5 rendering section.
I’ve extracted the following rough steps from the rendering algorithm:
All timed tracks of a media resource that are in “showing” mode are rendered together to avoid overlapping text from multiple tracks.
The timed tracks cues that are to be rendered are collected from the active timed tracks and ordered by the timed track order first and by their start time second. Where there are identical start times, the cues are ordered by their end time, earliest first, or by their creation order if all else is identical.
Each cue gets its own CSS box.
The text in the CSS boxes is positioned and formated by interpreting the positioning and formatting instructions of WebSRT that are provided on the cues.
An anonymous inline CSS box is created into which all the cue CSS boxes are wrapped.
The wrapping CSS box gets the dimensions of the video viewport. The cue CSS boxes are positioned so they don’t overlap. The text inside the cue CSS boxes inside the wrapping CSS box is wrapped at the edges if necessary.
To overcome security concerns with this kind of direct rendering of a CSS box into the Web page where text comes potentially from a different and malicious Web site, it is required to have the cues come from the same origin as the Web page.
To allow application of a restricted set of CSS properties to the timed text cues, a set of pseudo-selectors was introduced. This is necessary since all the CSS boxes are anonymous and cannot be addressed from the Web page. The introduced pseudo-selectors are ::cue to address a complete cue CSS box, and ::cue-part to address a subpart of a cue CSS box based on a set of identifiers provided by WebSRT.
I have several issues with this approach:
I believe that it is not a good idea to only restrict rendering to same-origin files. This will disallow the use of external captioning services (or even just a separate caption server of the same company) to link to for providing the captions to a video. Henri Sivonen proposed a means to overcome this by parsing every cue basically as its own HTML document (well, the body of a document) and then rendering these in iFrame-manner into the Web page. This would overcome the same-origin restriction. It would also allow to do away with the new ::cue CSS selectors, thus simplifying the solution.
In general I am concerned about how tightly the rendering is tied to WebSRT. Step 4 should not be in the HTML5 specification, but only apply to WebSRT. Every external format should provide its own mapping to CSS. As it is specified right now, other formats, such as e.g. 3GPP in MPEG-4 or Kate in Ogg, are required to map their format and positioning information to WebSRT instructions. These are then converted again using the WebSRT to CSS mapping rules. That seems overkill.
I also find step 6 very limiting, since only the video viewport is regarded as a potential rendering area - this is also the reason why there is no rendering for audio elements. Instead, it would make a lot more sense if a CSS box was provided by the HTML page - the default being the video viewport, but it could be changed to any area on screen. This would allow to render music lyrics under or above an audio element, or render captions below a video element to avoid any overlap at all.
SUMMARY AND FURTHER NEEDS
We’ve made huge progress on accessibility features for HTML5 media elements with the specifications that Ian proposed. I think we can move it to a flexible and feature-rich framework as the improvements that Henri, myself and others have proposed are included.
However, we are not solving any of the accessibility needs that relate to alternative audio-visual tracks and resources. In particular there is no solution yet to deal with multi-track audio or video files that have e.g. sign language or audio description tracks in them - not to speak of the issues that can be introduced through dealing with separate media resources from several sites that need to be played back in sync. This latter may be a challenge for future versions of HTML5, since needs for such synchoronisation of multiple resources have to be explored further.
In a first instance, we will require an API to expose in-band tracks, a means to control their activation interactively in a UI, and a description of how they should be rendered. E.g. should a sign language track be rendered as pciture-in-picture? Clear audio and Sign translation are the two key accessibility needs that can be satisfied with such a multi-track solution.
Finally, another key requirement area for media accessibility is described in a section called “Content Navigation by Content Structure”. This describes the need for vision-impaired users to be able to navigate through a media resource based on semantic markup - think of it as similar to a navigation through a book by book chapters and paragraphs. The introduction of chapter markers goes some way towards satisfying this need, but chapter markers tend to address only big time intervals in a video and don’t let you navigate on a different level to subchapters and paragraphs. It is possible to provide that navigation through providing several chapter tracks at different resolution levels, but then they are not linked together and navigation cannot easily swap between resolution levels.
An alternative might be to include different resolution levels inside a single chapter track and somehow control the UI to manage them as different resolutions. This would only require an additional attribute on text cues and could be useful to other types of text tracks, too. For example, captions could be navigated based on scenes, shots, coversations, or individual captions. Some experimentation will be required here before we can introduce a sensible extension to the given media accessibility framework.
For 2 months now, I have been quietly working along on a new Mozilla contract that I received to continue working on HTML5 media accessibility. Thanks Mozilla!
Lots has been happening - the W3C HTML5 accessibility task force published a requirements document, the Media Text Associations proposal made it into the HTML5 draft as a , and there are discussions about the advantages and disadvantages of the new WebSRT caption format that Ian Hickson created in the WHATWG HTML5 draft.
The first three now already have first drafts in the HTML5 specification, though the details still need to be improved and an external text track file format agreed on. The last has had a major push ahead with the Media Fragments WG publishing a Last Call Working Draft. So, on the specification side of things, major progress has been made. On the implementation - even on the example implementation - side of things, we still fall down badly. This is where my focus will lie in the next few months.
After two years of effort, the W3C Media Fragment WG has now created a Last Call Working Draft document. This means that the working group is fairly confident that they have addressed all the required issues for media fragment URIs and their implementation on HTTP and is asking for outside experts and groups for input. This is the time for you to get active and proof-read the specification thoroughly and feed back all the concerns that you have and all the things you do not understand!
The media fragment (MF) URI specification specifies two types of MF URIs: those created with a URI fragment (”#”), e.g. video.ogv#t=10,20 and those with a URI query (”?”), e.g. video.ogv?t=10,20. There is a fundamental difference between the two that needs to be appreciated: with a URI fragment you can specify a subpart of a resource, e.g. a subpart of a video, while with a URI query you will refer to a different resource, i.e. a “new” video. This is an important difference to understand for media fragments, because only some things that we want to achieve with media fragments can be achieved with ”#”, while others can only be achieved by transforming the resource into a different new bitstream.
This all sounds very abstract, so let me give you an example. Say you want to retrieve a video without its audio track. Say you’d rather not download the audio track data, since you want to save on bandwidth. So, you are only interested to get the video data. The URI that you may want to use is video.ogv#track=video. This means that you don’t want to change the video resource, but you only want to see the video. The user agent (UA) has two options to resolve such a URI: it can either map that request to byte ranges and just retrieve those - or it can download the full resource and ignore the data it has not been requested to display.
Since we do not want the extra bytes of the audio track to be retrieved, we would hope the UA can do the byte range requests. However, most Web video formats will interleave the different tracks of a media resource in time such that a video track will results in a gazillion of smaller byte ranges. This makes it impractical to retrieve just the video through a ”#” media fragment. Thus, if we really want this functionality, we have to make the server more intelligent and allow creation of a new resource from the existing one which doesn’t contain the audio. Then, the server, upon receiving a request such as video.ogv#track=video can redirect that to video.ogv?track=video and actually serve a new resource that satisfies the needs.
This is in fact exactly what was implemented in a recently published Firefox Plugin written by Jakub Sendor - also described in his presentation “Media Fragment Firefox plugin”.
Media Fragment URIs are defined for four dimensions:
temporal fragments
spatial fragments
track fragments
named fragments
The temporal dimension, while not accompanied with another dimension, can be easily mapped to byte ranges, since all Web media formats interleave their tracks in time and thus create the simple relationship between time and bytes.
The spatial dimension is a very complicated beast. If you address a rectangular image region out of a video, you might want just the bytes related to that image region. That’s almost impossible since pixels are encoded both aggregated across the frame and across time. Also, actually removing the context, i.e. the image data outside the region of interest may not be what you want - you may only want to focus in on the region of interest. Thus, the proposal for what to do in the spatial dimension is to simply retrieve all the data and have the UA deal with the display of the focused region, e.g. putting a dark overlay over the regions outside the region of interest.
The track dimension is similarly complicated and here it was decided that a redirect to a URI query would be in order in the demo Firefox plugin. Since this requires an intelligent server - which is available through the Ninsuna demo server that was implemented by Davy Van Deursen, another member of the MF WG - the Firefox plugin makes use of that. If the UA doesn’t have such an intelligent server available, it may again be most useful to only blend out the non-requested data on the UA similar to the spatial dimension.
The named dimension is still a largely undefined beast. It is clear that addressing a named dimension cannot be done together with the other dimensions, since a named dimension can represent any of the other dimensions above, and even a combination of them. Thus, resolving a named dimension requires an understanding of either the UA or the server what the name maps to. If, for example, a track has a name in a media resource and that name is stored in the media header and the UA already has a copy of all the media headers, it can resolve the name to the track that is being requested and take adequate action.
But enough explaining - I have made a screencast of the Firefox plugin in action for all these dimensions, which explains things a lot more concisely than word will ever be able to - enjoy:
I’m pretty proud of this, which is why I’m dedicating a short blog post to it: today, John and I released my first WordPress plugin as open source to the WordPress plugins site.
It’s got the boring name “External Videos” and builds a bridge between your WordPress instance and videos of channels on a video hosting site - currently supported are YouTube, Vimeo, and DotSub.
It does this by using a brand-new feature to be introduced in WordPress 3: custom post types.
Check out the screenshots on the plugins page to see more - I’m unfortunately not yet running this Website with WordPress 3, so am not yet using this plugin’s features.
In the admin interface of WordPress, you enter the video channels that you want to pull videos from. Then it goes and pulls the videos with their metadata from these sites and creates video posts for them. That pulling is done once a day to update with new posts. The videos can be looked at in the admin interface under a separate video post section. They can be linked to WordPress posts and pages where the video may be discussed in context.
The video posts can be exposed on the WordPress site through a gallery, which is created by a short code, that can be added to any WordPress page. The gallery of thumbnails clicks through to an overlay with each video and its metadata as well as a link to the related WordPress post.
You can also add a widget to the side bar of the WordPress site with links to the most recent videos.
There are many more features that I want to develop for this plugin. I’d of course like to move it to HTML5 video instead of Adobe Flash. But for now I am happy with it.
I’d like to say thank you to John Ferlito, who helped with some of the coding, to Jeff Waugh for suggesting that it would best be developed using the new post types feature, and to Senator Kate Lundy and Pia Waugh at her office, who funded a part of the development. I am hoping they will find it useful to give their awesome collection of videos better exposure.
Google have today announced the open sourcing of VP8 and the creation of a new media format WebM.
Technical Challenges
As I predicted earlier, Google had to match VP8 with an audio codec and a container format - their choice was a subpart of the Matroska format and the Vorbis codec. To complete the technical toolset, Google have:
developed ffmpeg patches, so an open source encoding tool for WebM will be available
Google haven’t forgotten the mobile space either - a bunch of Hardware providers are listed as supporters on the WebM site and it can be expected that developments have started.
The speed of development of software and hardware around WebM is amazing. Google have done an amazing job at making sure the technology matures quickly - both through their own developments and by getting a substantial number of partners included. That’s just the advantage of being Google rather than a Xiph, but still an amazing achievement.
Browsers
As was to be expected, Google managed to get all the browser vendors that are keen to support open video to also support WebM: Chrome, Firefox and Opera all have come out with special builds today that support WebM. Nice work!
What is more interesting, though, is that Microsoft actually announced that they will support WebM in future builds of IE9 - not out of the box, but on systems where the codec is already installed. Technically, that is be the same situation as it will be for Theora, but the difference in tone is amazing: in this blog post, any codec apart from H.264 was condemned and rejected, but the blog post about WebM is rather positive. It signals that Microsoft recognize the patent risk, but don’t want to be perceived of standing in the way of WebM’s uptake.
Apple have not yet made an announcement, but since it is not on the list of supporters and since all their devices exclusively support H.264 it stands to expect that they will not be keen to pick up WebM.
Publishers
What is also amazing is that Google have already achieved support for WebM by several content providers. The first of these is, naturally, YouTube, which is offering a subset of its collection also in the WebM format and they are continuing to transcode their whole collection. Google also has Brightcov, Ooyala, and Kaltura on their list of supporters, so content will emerge rapidly.
Uptake
So, where do we stand with respect to a open video format on the Web that could even become the baseline codec format for HTML5? It’s all about uptake - if a substantial enough ecosystem supports WebM, it has all chances of becoming a baseline codec format - and that would be a good thing for the Web.
And this is exactly where I have the most respect for Google. The main challenge in getting uptake is in getting the codec into the hands of all people on the Internet. This, in particular, includes people working on Windows with IE, which is still the largest browser from a market share point of view. Since Google could not realistically expect Microsoft to implement WebM support into IE9 natively, they have found a much better partner that will be able to make it happen - and not just on Windows, but on many platforms.
Yes, I believe Adobe is the key to creating uptake for WebM - and this is admittedly something I have completely overlooked previously. Adobe has its Flash plugin installed on more than 90% of all browsers. Most of their users will upgrade to a new version very soon after it is released. And since Adobe Flash is still the de-facto standard in the market, it can roll out a new Flash plugin version that will bring WebM codec support to many many machines - in particular to Windows machines, which will in turn enable all IE9 users to use WebM.
Why would Adobe do this and thus cement its Flash plugin’s replacement for video use by HTML5 video? It does indeed sound ironic that the current market leader in online video technology will be the key to creating an open alternative. But it makes a lot of sense to Adobe if you think about it.
Adobe has itself no substantial standing in codec technology and has traditionally always had to license codecs. Adobe will be keen to move to a free codec of sufficient quality to replace H.264. Also, Adobe doesn’t earn anything from the Flash plugins themselves - their source of income are their authoring tools. All they will need to do to succeed in a HTML5 WebM video world is implement support for WebM and HTML5 video publishing in their tools. They will continue to be the best tools for authoring rich internet applications, even if these applications are now published in a different format.
Finally, in the current hostile space between Apple and Adobe related to the refusal of Apple to allow Flash onto its devices, this may be the most genius means of Adobe at getting back at them. Right now, it looks as though the only company that will be left standing on the H.264-only front and outside the open WebM community will be Apple. Maybe implementing support for Theora wouldn’t have been such a bad alternative for Apple. But now we are getting a new open video format and it will be of better quality and supported on hardware. This is exciting.
IP situation
I cannot, however, finish this blog post on a positive note alone. After reading the review of VP8 by a x.264 developer, it seems possible that VP8 is infringing on patents that are outside the patent collection that Google has built up in codecs. Maybe Google have calculated with the possibility of a patent suit and put money away for it, but Google certainly haven’t provided indemnification to everyone else out there. It is a tribute to Google’s achievement that given a perceived patent threat - which has been the main inhibitor of uptake of Theora - they have achieved such an uptake and industry support around VP8. Hopefully their patent analysis is sound and VP8 is indeed a safe choice.
In recent months, people in the W3C HTML5 Accessibility Task Force developed two proposals for introducing caption, subtitle, and more generally time-aligned text support into HTML5 audio and video.
These time-aligned text files can either come as external files that are associated with the timeline of the media resource, or they come as part of the media resource in a binary track.
For both cases we now have proposals to extend the HTML5 specification.
Firstly, let’s look at time-aligned text in external files. The change proposal introduces markup to associate such external files as a kind of “virtual track” with a media resource. Here is an example: <video src="video.ogv"> <track src="video_cc.ttml" type="application/ttaf+xml" language="en" role="caption"></track> <track src="video_tad.srt" type="text/srt" language="en" role="textaudesc"></track> <trackgroup role="subtitle"> <track src="video_sub_en.srt" type="text/srt; charset='Windows-1252'" language="en"></track> <track src="video_sub_de.srt" type="text/srt; charset='ISO-8859-1'" language="de"></track> <track src="video_sub_ja.srt" type="text/srt; charset='EUC-JP'" language="ja"></track> </trackgroup> </video> The video resource is “video.ogv”. Associated with it are five timed text resources.
The first one is written in TTML (which is the new name for DFXP), is a caption track and in English. TTML is particularly useful when you want to provide more than just an unformatted piece of text to the viewers. Hearing-impaired users appreciate any visual help they can be provided with to absorb the caption text more quickly. This includes colour coding of speakers, positioning of text close to the speaking person on screen, or even animated musical notes to signify music. Thus, a format like TTML that allows for formatting and positioning information is an appropriate format to specify captions.
All other timed text resources are provided in SRT format, which is a simpler format that TTML with only plain text in the text cues.
The second text track is a textual audio description track. A textual audio description is in fact targeted at the vision-impaired and contains text that is expected to be read out by a screen reader or routed to a braille device. Thus, as the video plays, a vision-impaired user receives additional information about the visual content of the scene through their screen reader or braille device. The SRT format is particularly useful for providing textual audio descriptions since it only provides plain text, which can easily be handed on to assistive technology. When authoring such textual audio descriptions, it is very important to pick time intervals in the original media resource where no other significant audio cue is provided, such that the vision-impaired user is able to listen to the screen reader during that time.
The last three text tracks are subtitle tracks. They are grouped into a trackgroup element, which is not strictly necessary, but enables the author to say that these tracks are supposed to be alternatives. Thus, a Web Browser can create a menu with all the available tracks and put the tracks in the trackgroup into a menu of their own where only one option is selectable (similar to how radiobuttons work). Incidentally, the trackgroup element also allows to avoid having to repeat the role attribute in all the containing tracks. It is expected that these menus will be added to the default media controls and will thus be visible if the media element has a controls attribute.
With the role, type and language attributes, it is easy for a Web Browser to understand what the different tracks have to offer. A Web Browser can even decide to offer new functionality that is helpful to certain user groups. For example, an addition to a Web Browser’s default settings could be to allow users to instruct a Web Browser to always turn on captions or subtitles if they are available in the user’s main language. Or to always turn on textual audio descriptions. In this way, a user can customise their default experience of a media resource over and on top of what a Web page author decides to expose.
Incidentally, the choice of “track” as a name for relating external text resources to a media element has a deeper meaning. It is easily possible in future to extend “track” elements to not just point to dependent text resources, but also to dependent audio or video resources. For example, an actual audio description that is a recording of a human voice rather than a rendered text description could be association in the same way. Right now, such an implementation is not envisaged by the Browser vendors, but it will be something to work towards in the future.
Now, with such functionality available, there is naturally a desire to be able to control activation or de-activation of text tracks through JavaScript, not just through user interaction. A Web Developer may for example want to override the default controls provided by a Web Browser and run their own JavaScript-based controls, thus requiring to create their own selection menu for the tracks.
This is actually also an issue more generally and applies to all track types, including such tracks that come inside an existing media resource. In the current specification such tracks are not exposed and can therefore not be activated.
This is where the second specification that the W3C Accessibility Task Force has worked towards comes in: the media multitrack JavaScript API.
This specification introduces a read-only JavaScript interface to the audio and video elements to allow Web Developers to find out about the tracks (including the virtual tracks) that a media resource offers. The only action that the interface currently provides is to enable or disable tracks. Here is an example use to turn on a french subtitle track: if (video.tracks[2].role == "subtitle" && video.tracks[2].language == "fr") video.tracks[2].enabled = true;
There is still a need to introduce a means to actually expose the text cues as they relate to the currentTime of the media resource. This has not yet been specified in the given proposals.
The text cues could be exposed in several ways. They could be exposed through introducing an event, i.e. every time a new text cue becomes active, a callback is called which is given the active text cue (if such a callback had been registered previously). Another option is to simply write the text cues into a specified div-element in the DOM and thus expose them directly in the Browser. A third idea could be to expose the text cues in an iframe-like element to avoid any cross-site security issues. And a fourth idea that we have discussed is to expose the text cues in an attribute of the track.
All of this obviously also relates to how to actually render the text cues and whether to render them in a shadow DOM so as to make the JavaScript reading separate from the rendering and address security and copyright issues. I’d be curious in opinions here on how it should be done.
Recently, I was asked to review the W3C Media Annotations specifications as they are about to go into Last Call (a state that comes before the request for implementations at the W3C).
The W3C Media Annotations group has defined a set of metadata that they believe is representative and common for media resources. The ontology consist of the following fields:
ma:identifier: a URI or string to identify a resource
ma:title: a string providing the title of the resource
ma:language: a language code describing the language used in the resource
ma:locator: the URI at which the resource can be accessed
ma:contributor: a URI or string identifying the contributor and the nature of the contribution
ma:creator: a URI or string identifying an author
ma:createDate: a date of creation or publication of the resource
ma:location: a string or geo code identifying where the resource has been shot/recorded
ma:description: a string describing the content of the resource
ma:keyword: a word or word combination providing a topic, keyword or tag representing the resource
ma:genre: a string providing the genre of the resource
ma:rating: rating value, including the rating scale
ma:relation: a URI and string identifying a related resource and the relationship
ma:collection: a URI or string providing the name of a collection to which the resource belongs
ma:copyright: a URI or string with the copyright statement.
ma:license: a string or URI with the usage license
ma:publisher: a string or URI with the publisher of the resource
ma:targetAudience: a URI and classification string providing the issuer of the classification and the classification value
ma:fragments: a list of string and URI values that identify media fragments and their type
ma:namedFragments: a list of string and URI values the provide names to media fragments
ma:frameSize: a width - height pair in pixels
ma:compression: a string providing the compression algorithm
ma:duration: a float to provide the resource duration in seconds
ma:format String: the mime type of the resource
ma:samplingrate: a float with the audio sampling rate
ma:framerate: a float with the video frame rate
ma:bitrate: a float providing the average bit rate in kbps
ma:numTracks: an int of the number of tracks
Note that some of these fields are not single values, but simple constructs of multiple values. Thus, they are actually more complex than name-value pairs that, e.g. are typically used in HTML meta headers or in Dublin Core. I regard this as an issue for implementations.
The fields were chosen as typical metadata being available about media resources. The media fragments fields are a bit dubious in this respect, but could be useful in future.
The metadata is determined either from within the resource itself or from a metadata collection about the resource. As such, the document maps several existing metadata and media resource formats to this interface, amongst them:
As they didn’t have a mapping table for Ogg content, I offered the following:
MAWG
Relation
Ogg properties
How to do the mapping
Datatype
Descriptive Properties (Core Set)
Identification
ma:identifier
exact
Name
Name field in skeleton header (new)
String
ma:title
exact
Title
TITLE field in vorbiscomment header
String
exact
Title
Title field in skeleton header (new)
String
related
Album
ALBUM title in vorbiscomment header
String
ma:language
exact
Language
Language field in skeleton header (new)
language code
ma:locator
exact
file URI from system
URI
Creation
ma:contributor
exact
Artist, Performer
ARTIST and PERFORMER vorbiscomment headers
Strings
ma:creator
related
Organization
ORGANIZATION field in vorbiscomment header
ma:createDate
exact
Date
DATE field in vorbiscomment header
ISO date format
ma:location
exact
Location
LOCATION field in vorbiscomment header
String
Content description
ma:description
exact
Description
DESCRIPTION field in vorbiscomment header
String
ma:keyword
N/A
ma:genre
exact
Genre
GENRE field in vorbiscomment header
String
ma:rating
N/A
Relational
ma:relation
related
Version, Tracknumber
VERSION (version of a title), TRACKNUMBER (CD track) fields in vorbiscomment header
Strings
ma:collection
related
Album
ALBUM field of vorbiscomment header
String
Rights
ma:copyright
exact
Copyright
COPYRIGHT field of vorbiscomment header
String
ma:license
exact
License
LICENSE field of vorbiscomment header
String
Distribution
ma:publisher
related
Organization
ORGNIZATION field of vorbiscomment header
String
ma:targetAudience
more specific
Role
Role field of Skeleton header (new)
String
Fragments
ma:fragments
N/A
ma:namedFragments
N/A
Technical Properties
ma:frameSize
exact
extract from binary header of video track
int, int (width x height)
ma:compression
exact
Content-type
Content-type field of Skeleton header
MIME type
ma:duration
exact
calculate as duration = last_sample_time - first_sample_time of OggIndex header of skeleton
Float (or rather: rational - rational)
ma:format
exact
Content-type
Content-type field of Skeleton header
MIME type
ma:samplingrate
exact
calculate as granulerate = granulerate_numerator / granulerate_denominator of Skeleton header
Rational (or rather int / int)
ma:framerate
exact
calculate as granulerate = granulerate_numerator / granulerate_denominator of Skeleton header
Rational (or rather int / int)
ma:bitrate
exact
calculate as bitrate = length_of_segment / duration from OggIndex headers of skeleton
Float
ma:numTracks
exact
Tracknumber
TRACKNUMBER field of vorbiscomment header (track number on album)
Int
You will notice that the table mentions 4 fields in skeleton with a “new” marker - they are actually proposed fields in skeleton - a bit of coding will be necessary to introduce them into software. The space for these fields already exists in message header fields, so it won’t require a change of the skeleton format.
In the second specification of the Media Annotations WG, the group offers a standard API to access (i.e. read) the defined fields. They also intend to create an API to write the fields, but I doubt that will be easy because of the vast amount of file types they intend to support.
There is basically a single function that allows the extraction of metadata: MAObject[] getProperty(in DOMString propertyName, in optional DOMString sourceFormat, in optional DOMString subtype, in optional DOMString language, in optional DOMString fragment );
I proposed it may be possible to include this into HTML5 as follows: interface HTMLMediaElement : HTMLElement { ... getter MAObject getProperty(in DOMString propertyName, in optional unsigned long trackIndex); ... }
This would either extract the property for a particular track in a media resource or for the complete resource if no track index is given. The only problem I see is that the returned object is different depending on the requested property - the MAObject is only a parent class for the returned object types. I am not sure it is therefore possible to specify this easily in HTML5.
Overall I thought the specification was a nice piece of work. I am not sure I agree with all the chosen fields, but that is always an issue with metadata. The most important fields are there and that’s what matters.
Today, I was invited to give a talk at my old workplace CSIRO about the HTML5 media elements and accessibility.
A lot of the things that have gone into Ogg and that are now being worked on in the W3C in different working groups - including the Media Fragments and HTML5 WGs - were also of concern in the Annodex project that I worked on while at CSIRO. So I was rather excited to be able to report back about the current status in HTML5 and where we’re at with accessibility features.
Check out the presentation here. It contains a good collection of links to exciting demos of what is possible with the new HTML5 media elements when combined with other HTML features.
I tried something now with this presentation: I wrote it in a tool called S5, which makes use only of HTML features for the presentation. It was quite a bit slower than I expected, e.g. reloading a page always included having to navigate to that page. Also, it’s not easily possible to do drawings, unless you are willing to code them all up in HTML. But otherwise I have found it very useful for, in particular, including all the used URLs and video element demos directly in the slides. I was inspired with using this tool by Chris Double’s slides from LCA about implementing HTML 5 video in Firefox.
—\n 189823\n\n17753616 bbb_youtube_h264_499kbit.mp4\n13898515 bbb_youtube_h264_499kbit.h264\n 3796188 bbb_youtube_h264_499kbit.aac\n--------\n 58913\n\nI hope you believe me now..”
parent: 0
id: 607
author: “DonDiego”
authorUrl: ""
date: “2010-02-25 09:31:12”
content: “@Louise: FLV and MP4 are general-purpose container formats that can contain audio, video, subtitles and metadata in a variety of flavors.”
parent: 0
id: 608
author: “Monty”
authorUrl: “http://xiph.org”
date: “2010-02-25 10:53:24”
content: “DonDiego, you troll this every chance you get. I’m getting tired of addressing it in one place, having the rebuttal entirely ignored, and then having you plaster it somewhere else, anywhere else that’s visible.\n\nOgg is different from your favorite container. We know. It does not need to be extended for every new codec. It’s a transport layer that does not include metadata (that’s for Skeleton). Mp4 and Nut make metadata part of a giant monolithic design. Whoop-de-do. The overhead depends on how it’s being used (for the high bitrate BBB above, it’s using a tiny page size tuned to low bitrate vids, an aspect of the encoder that produced it, not Ogg itself). Etc, etc. \n\nDoing something different than the way you and your group would do it is not ‘horribly flawed’ it is just… different.\n\nWe’re not dropping Ogg and breaking tens of millions of decoders to use mp4 or Nut just because a few folks are angry that their pet format came too late or because your country doesn’t have software patents. Where I live, patents exist. You’re free to do anything that you want with the codecs, of course. Go ahead and put them in MOV or Nut! As you loudly proclaim, you’re in a country that doesn’t have software patents, so you don’t have to care.\n\nOr, “for the love of all that is holy”, get over it. Last I checked you weren’t willing to use Theora either… so why exactly are you here…? Obvious troll is obvious.”
parent: 0
id: 609
author: “Chris Smart”
authorUrl: “http://blog.christophersmart.com”
date: “2010-02-25 11:12:47”
content: “@DonDiego\nPage 93 of the ISO Base File Format standard states that Apple, Matsushita and Telefonaktiebolaget LM Ericsson assert patents in relation to this format.\n\nHere’s the standard:\nhttp://standards.iso.org/ittf/PubliclyAvailableStandards/c051533_ISO_IEC_14496-12_2008.zip\n\n-c”
parent: 0
id: 610
author: “Monty”
authorUrl: “http://xiph.org”
date: “2010-02-25 11:39:57”
content: “Since I have to rebut this again lest it grow legs:\n\nFor the record, If I was redesigning the Ogg container today, I’d consider changing two things:\n\n1) The specific packet length encoding encoding tops out at an overhead efficiency of .5%. If you accept an efficiency hit on small packet sizes, you can improve large packet size efficiency. This is one of the things Diego is ranting about. We actually had an informal meeting about this at FOMS in 2008. We decided that breaking every Ogg decoder ever shipped was not worth a theoretical improvement of .3% (depending on usage).\n\n2) Ogg page checksums are whole-page and mandatory. Today I’d consider making them switchable, where they can either cover the whole page or just the page header. It would optionally reduce the computational overhead for streams where error detection is internal to the codec packet format, or for streams where the user encoding does not care about error detection. Again— not worth breaking the entire install base. \n\nAt FOMS we decided that if we were starting from scratch, the first was a good idea and we were split on the checksums. But we’re not starting from scratch, and compatibility/interop is paramount.\n\nThe third big thing Diego (and the mplayer community in general) hate is the intentional, conscious decision to allow a codec to define how to parse granule positions for that codec’s stream. Granpos parsing thus requires a call into the codec. \n\nThe practical consequence: When an Ogg file contains a stream for which a user doesn’t have the codec installed… they can’t decode the stream! gasp Wait… how is that different from any other system? \n\nWhat’s different is that the demuxer also can’t parse the timestamps on those pages that wouldn’t be decodable anyway. Also, see above, parsing a timestamp requires a call to the installed codec. The mplayer mux layer can’t cope with this design, and they won’t change the player. We’re supposed to change our format instead.\n\nFourth cited difference is that Ogg is transport only and stream metadata is in Skeleton (or some other layer sitting inside the low level Ogg transport stream) rather than part of a monolithic stream transport design. Practical difference? None really. Except that their mux/demux design can’t handle it, and they’re not interested in changing that either.\n\nI hope this clarifies the years of sustained anti-Ogg vitriol from the Mplayer and spin-off communities. Could Ogg be improved? Sure! Is that a reason to burn everything and start over? DonDiego seems to think so.”
parent: 0
id: 611
author: “Chris Smart”
authorUrl: “http://blog.christophersmart.com”
date: “2010-02-25 11:41:42”
content: “@DonDiego\n\nYour assertion that FLV supports a variety of is not quite true (depends on your definition of “variety” - having “two” could be considered “variety”).\n\nAccording to the spec (“http://www.adobe.com/devnet/flv/pdf/video_file_format_spec_v10.pdf\”), FLV only supports the following Audio formats:\nPCM\nMP3\nNollymoser\nG.711\nAAC\nSpeex\n\nLikewise, only a few video formats are supported, namely:\nVP6\nH.263\nH.264\n\nMost importantly, it does not support free video and audio formats such as Theora and Vorbis.\n\n-c”
parent: 0
id: 612
author: “Multimedia Mike”
authorUrl: “http://multimedia.cx/eggs/”
date: “2010-02-25 12:14:31”
content: “@Chris Smart: Technically, there’s nothing preventing FLV from supporting a much larger set of audio and video codecs. However, it’s generally only useful to encode codecs that the Adobe Flash Player natively supports since that’s the primary use case for FLV. Adding support for another codec is generally just a matter of deciding on a new unique ID for that codec.\n\nDeciding on a new unique ID for a codec is usually all that’s necessary for adding support for a new codec to a general-purpose container format. It’s why AVI is still such a catch-all format— just think of a new unique ID (32-bit FourCC) for your experimental codec.\n\nThe beef we have with Ogg is — as Monty eloquently describes in his comment — that Ogg increases the coupling between container and codec layers. This adds complexity that most multimedia systems don’t have to deal with.”
parent: 0
id: 613
author: “Louise”
authorUrl: ""
date: “2010-02-25 12:17:03”
content: “@Monty\n\nVery interesting read!!\n\nIt is scary how a container that is suppose to free us from the proprietary containers, can be so bad.\n\nI found this blog from a x264 developer\nhttp://x264dev.multimedia.cx/?p=292\n\nwhich had this to say about ogg:\n\n[quote]\nMKV is not the best designed container format out there (it”
parent: 0
id: 614
author: “Multimedia Mike”
authorUrl: “http://multimedia.cx/eggs/”
date: “2010-02-25 12:23:01”
content: “@Louise: “Do you think VP8 would be back wards compatible if it contains 3rd party patents, and they were removed?”\n\nBackwards compatible with what?”
parent: 0
id: 615
author: “Monty”
authorUrl: “http://xiph.org”
date: “2010-02-25 14:08:36”
content: ”> It is scary how a container that is suppose to free us from the \n> proprietary containers, can be so bad.\n\nIt isn’t. It is very different from one what set of especially pretentious wonks expects and they’ve been wanking about it for coming up on a decade. None of this makes an ounce of difference to users, and somehow other software groups don’t seem to have any trouble with Ogg. For such a fatally flawed system, it seems to work pretty well in practice :-P\n\nSuggestions like ‘They should have just used MKV’ doesn’t make sense. Ogg predates MKV by many years, and interleave is a fairly recent feature in MKV. \n\nThe format designed by the mplayer folks is named Nut. Despite many differences in the details, the system it resembles most closely… is Ogg. Subjective evaluation of course, but I always considered the resemblance uncanny. \n\nLast of all, suppose just out of old fashioned spite and frustration, Xiph says ‘No more Ogg for the container! We use Nut now!’ That… pretty much ends FOSS’s practical chances of having any relevance in web video or really any net multimedia for the forseeable future. …all to get that .3% and a design change under the blankets that no user could ever possibly care about. Sign me up!”
parent: 0
id: 616
author: “silvia”
authorUrl: “http://blog.gingertech.net/”
date: “2010-02-25 20:39:55”
content: “@DonDiego To be fair, in your file size example, you should provide the correct sums:\n\n== quote\n17307153 bbb_theora_486kbit.ogv\n15009926 bbb_theora_486kbit.theora\n2107404 bbb_theora_486kbit.vorbis\n”
parent: 0
id: 617
author: “Louise”
authorUrl: ""
date: “2010-02-25 21:20:28”
content: “@Monty\n\nWas NUT designed before MKV was released?”
parent: 0
id: 618
author: “DonDiego”
authorUrl: ""
date: “2010-02-25 22:39:45”
content: “@silvia: I am providing the correct sums! You are misreading my table. Let me reformat the table slightly and pad with zeroes for readability:\n\n 17307153 bbb_theora_486kbit.ogv (the complete file)\n- 15009926 bbb_theora_486kbit.theora (the video track)\n- 02107404 bbb_theora_486kbit.vorbis (the audio track)\n ========\n 00189823 (container overhead)\n\n 17753616 bbb_youtube_h264_499kbit.mp4 (the complete file)\n- 13898515 bbb_youtube_h264_499kbit.h264 (the video track)\n- 03796188 bbb_youtube_h264_499kbit.aac (the audio track)\n ========\n 00058913 (container overhead)\n\nSo in this application, Ogg has more than 300% the overhead of MP4. Ogg is known to produce large overhead, but I did not expect this order of magnitude. Now I believe Monty that it’s possible to reduce this, but the purpose of Greg’s comparison was to test this particular configuration without additional tweaks. Otherwise the H.264 and AAC encoding settings could be tweaked further as well…\n\nI wonder what you tested when you say that in your experience Ogg files come out smaller than MPEG files. The term “MPEG files” is about as broad as it gets in the multimedia world. Yes, the MPEG-TS container has very high overhead, but it is designed for streaming over lossy sattelite links. This special purpose warrants the overhead tradeoff.”
parent: 0
id: 619
author: “DonDiego”
authorUrl: ""
date: “2010-02-25 22:44:32”
content: “@louise: NUT was designed after Matroska already existed.”
parent: 0
id: 620
author: “Monty”
authorUrl: “http://www.xiph.org/”
date: “2010-02-26 08:16:54”
content: “Silvia: DonDiego was illustrating a broken-out subtraction. His numbers are correct, as is his claim; Ogg is introducing more overhead (1%). That’s almost certainly reduceable, but I’ve not looked at the page structure in Vorbose to be sure of that claim. .5%-.7% is the intended working range. It climbs if the muxer is splitting too many packets or the packets are just too small (not the case here).\n\n>So in this application, Ogg has more than 300% the overhead of MP4. \n>Ogg is known to produce large overhead, but I did not expect this \n>order of magnitude.\n\nYes, Ogg is using more overhead. Let’s assume that a better muxer gets me .7% overhead (yeah, even our own muxer is overly straightforward and doesn’t try anything fancy; it hasn’t been updated since 1998 or so. “Have to extend to container for every new codec” jeesh…)\n\nSo this is really a screaming fight over the difference between .7% and .3%? \n\nI don’t debate for a second that Nut’s packet length encoding is better, and that’s the lion’s share of the difference assuming the file is muxed properly. And if/when (long term view, ‘when’ is almost certainly correct) Ogg needs to be refreshed in some way that has to break spec anyway, the Nut packet encoding will be one of the first things added because at that point it’s a ‘why not?’. But until then there’s no sensible way to defend the havoc a container change would wreak and all for reducing a .7% bitstream overhead down to .3%. It would be optimising something completely insignificant at great practical cost.”
parent: 0
id: 621
author: “silvia”
authorUrl: “http://blog.gingertech.net/”
date: “2010-02-26 10:07:54”
content: “@monty, @DonDiego thanks for the clarifications”
parent: 0
id: 622
author: “DonDiego”
authorUrl: ""
date: “2010-02-26 11:43:00”
content: “@Monty: You are giving me far too much credit! “for the love of all that is holy and some that is not, don’t do that” is a quote from Mans in reply to somebody proposing to add ‘#define _GNU_SOURCE’ to FFmpeg. I have been looking for an opportunity to steal that phrase and take credit as being funny for a long time. SCNR ;-p\n\nSpeaking of memorable quotes I cannot help but point at the following classic out of your feather after trying and failing to get patches into MPlayer:\nhttp://lists.mplayerhq.hu/pipermail/mplayer-dev-eng/2007-November/054865.html\n\n======\nFine. I give up.\n\nThere are plenty of things about the design worth arguing about… but\nyou guys are more worried about the color of the mudflaps on this\ndumptruck. You’re rejecting considered decisions out of hand with\nvague, irrelevant dogma. I’ve seen two legitimate bugs brought up so\nfar in a mountain of “WAAAH! WE DON’T LIKE YOUR INDEEEEENT.”\n\nI have the only mplayer/mencoder on earth that can always dump WMV2\nand WMV3 without losing sync. I just needed it for me. I thought it\nwould be nice to submit it for all your users who have been asking for\nthis for years. But it just ceased being worth it.\n\nPatch retracted. You can all go fuck yourselves. Life is too short\nfor this asshattery.\n\nMonty\n=====\n\nWe remember you fondly. I and many others didn’t know what asshat meant before, but now it found a place in everybody’s active vocabulary. I’m not being ironic BTW, sometimes nothing warms the heart more than a good flame and few have generated more laughter than yours :-)\n\nThe ironic thing is that your fame brought you attention and the attention brought detailed reviews, which made patch acceptance harder.\n\nI also failed getting patches into Tremor. You rejected them for silly reasons, but, admittedly, I did not have the energy to flame it through…\n\nFor the record: I have no vested interest in NUT. Some of the comments above could be read to suggest that Ogg would be a good base when starting from a clean slate. This is wrong, Ogg is the weakest part of the Xiph stack. You know that, but there are people all around the internet proclaiming otherwise. This does not help your case, on the contrary, so I try to inject facts into the discussion. Admittedly, sometimes I do it with a little bit of flair of my own ;-)\n\nCheers, Diego”
parent: 0
id: 623
author: “Monty”
authorUrl: “http://www.xiph.org/”
date: “2010-02-26 12:06:52”
content: “@DonDiego\n\na) I was indeed bucking up against rampant asshattery.\n\nb) Not sure how any of that is even slightly relevant to this thread.\n\nYou’re bringing it up in some sort of attempt to shame or embarrass because you’ve lost on facts? For the record, I meant it when I said it then, and I don’t feel any differently now. And asshat is indeed a fabulous word.\n\n[FTR, you’ve had two patches rejected and several more accepted if the twelve hits from Xiph.Org Trac are a complete set.]\n\nMonty”
parent: 0
id: 624
author: “silvia”
authorUrl: “http://blog.gingertech.net/”
date: “2010-02-26 12:12:01”
content: “This blog is not for personal attacks, but only for discussing technical issues. Unfortunately, the discussion on these comments is developing in a way that I cannot support any longer. I have therefore decided to close comments.\n\nThank you everyone for your contributions.”
parent: 0
I am sure Google is thinking about it. But … what does “it” mean?
Freeing VP8 Simply open sourcing it and making it available under a free license doesn’t help. That just provides open source code for a codec where relevant patents are held by a commercial entity and any other entity using it would still need to be afraid of using that technology, even if it’s use is free.
So, Google has to make the patents that relate to VP8 available under an irrevocable, royalty-free license for the VP8 open source base, but also for any independent implementations of VP8. This at least guarantees to any commercial entity that Google will not pursue them over VP8 related patents.
Now, this doesn’t mean that there are no submarine or unknown patents that VP8 infringes on. So, Google needs to also undertake an intensive patent search on VP8 to be able to at least convince themselves that their technology is not infringing on anyone else’s. For others to gain that confidence, Google would then further have to indemnify anyone who is making use of VP8 for any potential patent infringement.
I believe - from what I have seen in the discussions at the W3C - it would only be that last step that will make companies such as Apple have the confidence to adopt a “free” codec.
An alternative to providing indemnification is the standardisation of VP8 through an accepted video standardisation body. That would probably need to be ISO/MPEG or SMPTE, because that’s where other video standards have emerged and there are a sufficient number of video codec patent holders involved that a royalty-free publication of the standard will hold a sufficient number of patent holders “under control”. However, such a standardisation process takes a long time. For HTML5, it may be too late.
Technology Challenges Also, let’s not forget that VP8 is just a video codec. A video codec alone does not encode a video. There is a need for an audio codec and a encapsulation format. In the interest of staying all open, Google would need to pick Vorbis as the audio codec to go with VP8. Then there would be the need to put Vorbis and VP8 in a container together - this could be Ogg or MPEG or QuickTime’s MOOV. So, apart from all the legal challenges, there are also technology challenges that need to be mastered.
It’s not simple to introduce a “free codec” and it will take time!
Google and Theora There is actually something that Google should do before they start on the path of making VP8 available “for free”: They should formulate a new license agreement with Xiph (and the world) over VP3 and Theora. Right now, the existing license that was provided by On2 Technologies to Theora (link is to an early version of On2’s open source license of VP3) was only for the codebase of VP3 and any modifications of it, but doesn’t in an obvious way apply to an independent re-implementations of VP3/Theora. The new agreement between Google and Xiph should be about the patents and not about the source code. (UPDATE: The actual agreement with Xiph apparently also covers re-implementations - see comments below.)
That would put Theora in a better position to be universally acceptable as a baseline codec for HTML5. It would allow, e.g. Apple to make their own implementation of Theora - which is probably what they would want for ipods and iphones. Since Firefox, Chrome, and Opera already support Ogg Theora in their browsers using the on2 licensed codebase, they must have decided that the risk of submarine patents is low. So, presumably, Apple can come to the same conclusion.
Free codecs roadmap I see this as the easiest path towards getting a universally acceptable free codec. Over time then, as VP8 develops into a free codec, it could become the successor of Theora on a path to higher quality video. And later still, when the Internet will handle large resolution video, we can move on to the BBC’s Dirac/VC2 codec. It’s where the future is. The present is more likely here and now in Theora.
ADDITION: Please note the comments from Monty from Xiph and from Dan, ex-On2, about the intent that VP3 was to be completely put into the hands of the community. Also, Monty notes that in order to implement VP3, you do not actually need any On2 patents. So, there is probably not a need for Google to refresh that commitment. Though it might be good to reconfirm that commitment.
ADDITION 10th April 2010: Today, it was announced that Google put their weight behind the Theorarm implementation by helping to make it BSD and thus enabling it to be merged with Theora trunk. They also confirm on their blog post that Theora is “really, honestly, genuinely, 100% free”. Even though this is not a legal statement, it is good that Google has confirmed this.
At the recent FOMS/LCA in Wellington, New Zealand, we talked a lot about how Ogg could support accessibility. Technically, this means support for multiple text tracks (subtitles/captions), multiple audio tracks (audio descriptions parallel to main audio track), and multiple video tracks (sign language video parallel to main video track).
Creating multitrack Ogg files The creation of multitrack Ogg files is already possible using one of the muxing applications, e.g. oggz-merge. For example, I have my own little collection of multitrack Ogg files at http://annodex.net/~silvia/itext/elephants_dream/multitrack/. But then you are stranded with files that no player will play back.
Multitrack Ogg in Players As Ogg is now being used in multiple Web browsers in the new HTML5 media formats, there are in particular requirements for accessibility support for the hard-of-hearing and vision-impaired. Either multitrack Ogg needs to become more of a common case, or the association of external media files that provide synchronised accessibility data (captions, audio descriptions, sign language) to the main media file needs to become a standard in HTML5.
As it turn out, both these approaches are being considered and worked on in the W3C. Accessibility data that are audio or video tracks will in the near future have to come out of the media resource itself, but captions and other text tracks will also be available from external associated elements.
The availability of internal accessibility tracks in Ogg is a new use case - something Ogg has been ready to do, but has not gone into common usage. MPEG files on the other hand have for a long time been used with internal accessibility tracks and thus frameworks and players are in place to decode such tracks and do something sensible with them. This is not so much the case for Ogg.
For example, a current VLC build installed on Windows will display captions, because Ogg Kate support is activated. A current VLC build on any other platform, however, has Ogg Kate support deactivated in the build, so captions won’t display. This will hopefully change soon, but we have to look also beyond players and into media frameworks - in particular those that are being used by the browser vendors to provide Ogg support.
Multitrack Ogg in Browsers Hopefully gstreamer (which is what Opera uses for Ogg support) and ffmpeg (which is what Chrome uses for Ogg support) will expose all available tracks to the browser so they can expose them to the user for turning on and off. Incidentally, a multitrack media JavaScript API is in development in the W3C HTML5 Accessibility Task Force for allowing such control.
The current version of Firefox uses liboggplay for Ogg support, but liboggplay’s multitrack support has been sketchy this far. So, Viktor Gal - the liboggplay maintainer - and I sat down at FOMS/LCA to discuss this and Viktor developed some patches to make the demo player in the liboggplay package, the glut-player, support the accessibility use cases.
I applied Viktor’s patch to my local copy of liboggplay and I am very excited to show you the screencast of glut-player playing back a video file with an audio description track and an English caption track all in sync:
Further developments There are still important questions open: for example, how will a player know that an audio description track is to be played together with the main audio track, but a dub track (e.g. a German dub for an English video) is to be played as an alternative. Such metadata for the tracks is something that Ogg is still missing, but that Ogg can be extended with fairly easily through the use of the Skeleton track. It is something the Xiph community is now working on.
Summary This is great progress towards accessibility support in Ogg and therefore in Web browsers. And there is more to come soon.
Recently, I was asked for some help on coding with an HTML5 video element and its events. In particular the question was: how do I display the time position that somebody seeked to in a video?
Here is a code snipped that shows how to use the seeked event:
<video onseeked="writeVideoTime(this.currentTime);" src="video.ogv" controls></video> <p>position:</p><div id="videotime"></div> <script type="text/javascript"> // get video element var video = document.getElementsByTagName("video")[0]; function writeVideoTime(t) { document.getElementById("videotime").innerHTML=t; } </script>
Other events that can be used in a similar way are:
loadstart: UA requests the media data from the server
progress: UA is fetching media data from the server
suspend: UA is on purpose idling on the server connection mid-fetching
abort: UA aborts fetching media data from the server
error: UA aborts fetching media because of a network error
emptied: UA runs out of network buffered media data (I think)
stalled: UA is waiting for media data from the server
play: playback has begun after play() method returns
pause: playback has been paused after pause() method returns
loadedmetadata: UA has received all its setup information for the media resource, duration and dimensions and is ready to play
loadeddata: UA can render the media data at the current playback position for the first time
waiting: playback has stopped because the next frame is not available yet
playing: playback has started
canplay: playback can resume, but at risk of buffer underrun
canplaythrough: playback can resume without estimated risk of buffer underrun
seeking: seeking attribute changed to true (may be too short to catch)
seeked: seeking attribute changed to false
timeupdate: current playback position changed enough to report on it
ended: playback stopped at media resource end; ended attribute is true
ratechange: defaultPlaybackRate or playbackRate attribute have just changed
durationchange: duration attribute has changed
volumechange:volume attribute or the muted attribute has changed
I have talked a lot about synchronising multiple tracks of audio and video content recently. The reason was mainly that I foresee a need for more than two parallel audio and video tracks, such as audio descriptions for the vision-impaired or dub tracks for internationalisation, as well as sign language tracks for the hard-of-hearing.
It is almost impossible to introduce a good scheme to deliver the right video composition to a target audience. Common people will prefer bare a/v, vision-impaired would probably prefer only audio plus audio descriptions (but will probably take the video), and the hard-of-hearing will prefer video plus captions and possibly a sign language track . While it is possible to dynamically create files that contain such tracks on a server and then deliver the right composition, implementation of such a server method has not been very successful in the last years and it would likely take many years to roll out such new infrastructure.
So, the only other option we have is to synchronise completely separate media resource together as they are selected by the audience.
I created a Ogg video with only a video track (10m53s750). Then I created an audio track that is the original English audio track (10m53s696). Then I used a Spanish dub track that I found through BlenderNation as an alternative audio track (10m58s337). Lastly, I created an audio description track in the original language (10m53s706). This creates a video track with three optional audio tracks.
I took away all native controls from these elements when using the HTML5 audio and video tag and ran my own stop/play and seeking approaches, which handled all media elements in one go.
I was mostly interested in the quality of this experience. Would the different media files stay mostly in sync? They are normally decoded in different threads, so how big would the drift be?
The resulting page is the basis for such experiments with synchronisation.
The page prints the current playback position in all of the media files at a constant interval of 500ms. Note that when you pause and then play again, I am re-synching the audio tracks with the video track, but not when you just let the files play through.
I have let the files play through on my rather busy Macbook and have achieved the following interesting drift over the course of about 9 minutes:
You will see that the video was the slowest, only doing roughly 540s, while the Spanish dub did 560s in the same time.
To fix such drifts, you can always include regular re-synchronisation points into the video playback. For example, you could set a timeout on the playback to re-sync every 500ms. Within such a short time, it is almost impossible to notice a drift. Don’t re-load the video, because it will lead to visual artifacts. But do use the video’s currentTime to re-set the others. (UPDATE: Actually, it depends on your situation, which track is the best choice as the main timeline. See also comments below.)
It is a workable way of associating random numbers of media tracks with videos, in particular in situations where the creation of merged files cannot easily be included in a workflow.
The report explains the Australian Government’s existing regulatory framework for accessibility to audio-visual content on TV, digital TV, DVDs, cinemas, and the Internet, and provides an overview about what it is planning to do over the next 3-5 years.
It is interesting to read that according to the Australian Bureau of Statistics about 2.67 million Australians - one in every eight people - have some form of hearing loss and 284,000 are completely or partially blind. Also, it is expected that these numbers will increase with an ageing population and obesity-linked diabetes are expected to continue to increase these numbers.
For obvious reasons, I was particularly interested in the Internet-related part of the report. It was the second-last section (number five), and to be honest, I was rather disappointed: only 3 pages of the 40 page long report concerned themselves with Internet content. Also, the main message was that “at this time the costs involved with providing captions for online content were deemed to represent an undue financial impost on a relatively new and developing service.”
Audio descriptions weren’t even touched with a stick and both were written off with “a lack of clear online caption production and delivery standard and requirements”. There is obviously a lot of truth to the statements of the report - the Internet audio-visual content industry is still fairly young compared to e.g. TV, and there are a multitude of standards rather than a single clear path.
However, I believe the report neglected to mention the new HTML5 video and audio elements and the opportunity they provide. Maybe HTML5 was excluded because it wasn’t expected to be relevant within the near future. I believe this is a big mistake and governments should pay more attention to what is happening with HTML5 audio and video and the opportunities they open for accessibility.
In the end, I made a submission because I wanted the Australian Government to wake up to the HTML5 efforts and I wanted to correct a mistake they made with claiming MPEG-2 was “not compatible with the delivery of closed audio descriptions”.
I believe a lot more can be done with accessibility for Internet content than just “monitor international developments” and industry partnership with disability representative groups. I therefore proposed to undertake trials in particular with textual audio descriptions to see if they could be produced in a similar manner to captions, which would make their cost come down enormously. Also I suggested actually aiming for WCAG 2.0 conformance within the next 5 years - which for audio-visual content means at minimum captions and audio descriptions.
You can read the report here and my 4 page long submission here.
We basically taught people how to create and publish Ogg Theora video in HTML5 Web pages and how to make them work across browsers, including much of the available tools and libraries. We’re hoping that some people will have learnt enough to include modules in CMSes such as Drupal, Joomla and Wordpress, which will easily support the publishing of Ogg Theora.
I have been asked to share the material that we used. It consists of:
Vimeo started last week with a HTML5 beta test. They use the H.264 codec, probably because much of their content is already in this format through the Flash player.
But what really surprised me was their claim that roughly 25% of their users will be able to make use of their HTML5 beta test. The statement is that 25% of their users use Safari, Chrome, or IE with Chrome Frame. I wondered how they got to that number and what that generally means to the amount of support of H.264 vs Ogg Theora on the HTML5-based Web.
According to Statcounter’s browser market share statistics, the percentage of browsers that support HTML5 video is roughly: 31.1%, as summed up from Firefox 3.5+ (22.57%), Chrome 3.0+ (5.21%), and Safari 4.0+ (3.32%) (Opera’s recent release is not represented yet).
Out of those 31.1%,
8.53% browsers support H.264
and
27.78% browsers support Ogg Theora.
Given these numbers, Vimeo must assume that roughly 16% of their users have Chrome Frame in IE installed. That would be quite a number, but it may well be that their audience is special.
So, how is Ogg Theora support doing in comparison, if we allow such browser plugins to be counted?
With an installation of XiphQT, Safari can be turned into a browser that supports Ogg Theora. The Chome Frame installation will also turn IE into a Ogg Theora supporting browser. These could get the browser support for Ogg Theora up to 45%. Compare this to a claimed 48% of MS Silverlight support.
But we can do even better for Ogg Theora. If we use the Java Cortado player as a fallback inside the video element, we can capture all those users that have Java installed, which could be as high as 90%, taking Ogg Theora support potentially up to 95%, almost up to the claimed 99% of Adobe Flash.
I’m sure all these numbers are disputable, but it’s an interesting experiment with statistics and tells us that right now, Ogg Theora has better browser support than H.264.
UPDATE: I was told this article sounds aggressive. By no means am I trying to be aggressive - I am stating the numbers as they are right now, because there is a lot of confusion in the market. People believe they reach less audience if they publish in Ogg Theora compared to H.264. I am trying to straighten this view.
You probably heard it already: Linux.conf.au is live streaming its video in a Microsoft proprietary format.
Fortunately, there is now a re-broadcast that you can get in an open format from http://stream.v2v.cc:8000/ . It comes from a server in Europe, but relies on transcoding here in New Zealand, so it may not be completely reliable.
Today, the down under open source / Linux conference linux.conf.au in Wellington started with the announcement that every talk and mini-conf will be live streamed to the Internet and later published online. That’s an awesome achievement!
However, minutes after the announcement, I was very disappointed to find out that the streams are actually provided in a proprietary format and through a proprietary streaming protocol: a Microsoft streaming service that provides Windows media streams.
Why stream an open source conference in a proprietary format with proprietary software? If we cannot use our own technologies for our own conferences, how will we get the rest of the world to use them?
I must say, I am personally embarrassed, because I was part of several audio/video teams of previous LCAs that have managed to record and stream content in open formats and with open media software. I would have helped get this going, but wasn’t aware of the situation.
I am also the main organiser of the FOMS Workshop (Foundations of Open Media Software) that ran the week before LCA and brought some of the core programmers in open media software into Wellington, most of which are also attending LCA. We have the brains here and should be able to get this going.
Fortunately, the published content will be made available in Ogg Theora/Vorbis. So, it’s only the publicly available stream that I am concerned about.
Speaking with the organisers, I can somewhat understand how this came to be. They took the “easy” way of delegating the video work to an external company. Even though this company is an expert in open source and networking, their media streaming customers are all using Flash or Windows media software, which are current de-facto standards and provide extra features such as DRM. It seems apart from linux.conf.au there were no requests on them for streaming Ogg Theora/Vorbis yet. Their existing infrastructure includes CDN distribution and CDN providers certainly typically don’t provide Ogg Theora/Vorbis support or Icecast streaming.
So, this is actually a problem founded in setting up streaming through a professional service rather than through the community. The way in which this was set up at other events was to get together a group of volunteers that provided streaming reflectors for free. In this way, a community-created CDN is built that can deal with the streams. That there are no professional CDN providers available yet that provide Icecast support is a sign that there is a gap in the market.
But phear not - a few of the FOMS folk got together to fix the situation.
It involved setting up Icecast streams for each room’s video stream. Since there is no access to the raw video stream, there is a need to transcode the video from proprietary codecs to the open Ogg Theora/Vorbis format.
To do this legally, a purchase of the codec libraries from Fluendo was necessary, which cost a whopping EURO 28 and covers all the necessary patent licenses. The glue to get the videos from mms to icecast streams is a GStreamer pipeline which I leave others to talk about.
Now, we have all the streams from the conference available as Ogg Theora/Video streams, we can also publish them in HTML5 video elements. Check out this Web page which has all the video streams together on a single page. Note that the connections may be a bit dodgy and some drop-outs may occur.
Further, let me recommend the Multimedia Miniconf at linux.conf.au, which will take place tomorrow, Tuesday 19th January. The Miniconf has decided to add a talk about “How to stream you conference with open codecs” to help educate any potential future conference organisers and point out the software that helps solve these issues.
UPDATE: I should have stated that I didn’t actually do any of the technical work: it was all done by Ralph Giles, Jan Gerber, and Jan Schmidt.
UPDATE (6th February 2010): YouTube have just reacted to my bug and it seems there are some gData links that are more up-to-date than others. You need to go with the “uploads” gData APIs rather than the search or user ones to get accurate data. Glad YouTube told me and it’s documented now!
I am an avid user of YouTube Insight, the metrics tool that YouTube provides freely to everyone who publishes videos through them. YouTube Insight provides graphs on video views, the countries they originate in, demographics of the viewership, how the videos are discovered, engagement metrics, and hotspot analysis. It is a great tool to analyse the success of your videos, determine when to upload the next one, find out what works and what doesn’t.
However, you cannot rely on the accuracy of the numbers that YouTube Insight displays. In fact, YouTube provides three different means to find out what the current views (and other statistics, but let’s focus on the views) are for your videos:
the view count displayed on the video’s watch page
the view count displayed in YouTube Insight
the view count given in the gData API feed
The shocking reality is: for all videos I have looked at that are less than about a month old and keep getting views, all three numbers are different.
Sometimes they are just off by one or two, which is tolerable and understandable, since the data must be served from a number of load balanced servers or even server clusters and it would be difficult to keep all of these clusters at identical numbers all of the time.
However, for more than 50% of the videos I have looked at, the numbers are off by a substantial amount.
I have undertaken an analysis with random videos, where I have collected the gData views and the watch page views. The Insight data tends to be between these two numbers, but I cannot generally reach that data, so I have left it out of this analysis.
Here are the stats for 36 randomly picked videos in the 9 view-count classes defined by TubeMogul and by how much they are off at the time that I looked at them:
Class
Video
watch page
gData API
age
diff
percentage
>1M
1
7,187,174
6,082,419
2 weeks
1,104,755
15.37%
>1M
2
3,196,690
3,080,415
3 weeks
116,275
3.63%
>1M
3
2,247,064
1,992,844
1 week
254,220
11.31%
>1M
4
1,054,278
1,040,591
1 month
13,687
1.30%
100K-500K
5
476,838
148,681
11 days
328,157
68.82%
100K-500K
6
356,561
294,309
2 weeks
62,252
17.46%
100K-500K
7
225,951
195,159
2 weeks
30,792
13.63%
100K-500K
8
113,521
62,241
1 week
51,280
45.17%
10K-100K
9
86,964
46
4 days
86,918
99.95%
10K-100K
10
52,922
43,548
3 weeks
9,374
17.71%
10K-100K
11
34,001
33,045
1 month
956
2.81%
10K-100K
12
15,704
13,653
2 weeks
2,051
13.06%
5K-10K
13
9,144
8,967
1 month
117
1.94%
5K-10K
14
7,265
5,409
1 month
1,856
25.55%
5K-10K
15
6,640
5,896
2 weeks
744
11.20%
5K-10K
16
5,092
3,518
6 days
1,574
30.91%
2.5K-5K
17
4,955
4,928
3 weeks
27
0.91%
2.5K-5K
18
4,341
4,044
4 days
297
6.84%
2.5K-5K
19
3,377
3,306
3 weeks
71
2.10%
2.5K-5K
20
2,734
2,714
1 month
20
0.73%
1K-2.5K
21
2,208
2,169
3 weeks
39
1.77%
1K-2.5K
22
1,851
1,747
2 weeks
104
5.62%
1K-2.5K
23
1,281
1,244
1 week
37
2.89%
1K-2.5K
24
1,034
984
2 weeks
50
4.84%
500-1K
25
999
844
6 days
155
15.52%
500-1K
26
891
790
6 days
101
11.34%
500-1K
27
861
600
3 days
17
30.31%
500-1K
28
645
482
4 days
163
25.27%
100-500
29
460
436
10 days
24
5.22%
100-500
30
291
285
4 days
6
2.06%
100-500
31
256
198
3 days
58
22.66%
100-500
32
196
175
11 days
21
10.71%
0-100
33
88
74
10 days
14
15.90%
0-100
34
64
49
12 days
15
23.44%
0-100
35
46
21
5 days
25
54.35%
0-100
36
31
25
3 days
4
19.35%
The videos were chosen such that they were no more than a month old, but older than a couple of days. For older videos than about a month, the increase had generally stopped and the metrics had caught up, unless where the views were still increasing rapidly, which is an unusual case.
Generally, it seems that the host page has the right views. In contrast, it seems the gData interface is updated only once every week. It further seems from looking at YouTube channels where I have access to Insight that Insight is updated about every 4 days and it receives corrected data for the days in which it hadn’t caught up.
Further, it seems that YouTube make no differentiation between channels of partners and general users’ channels - both can have a massive difference between the watch page and gData. Most videos differ by less than 20%, but some have exceptionally high differences above 50% and even up to 99.95%.
The difference is particularly pronounced for videos that show a steep increase in views - the first few days tend to have massive differences. Since these are the days that are particularly interesting to monitor for publishers, having the gData interface lag behind this much is shocking.
Further, videos with a low number of views, in particular less than 100, also show a particularly high percentage in difference - sometimes an increase in view count isn’t reported at all in the gData API for weeks. It seems that YouTube treats the long tail worse than the rest of YouTube. For every video in this class, the absolute difference will be small - obviously less than 100 views. With almost 30% of videos being such videos, it is somewhat understandable that YouTube are not making the effort to update their views regularly. OTOH, these views may be particularly important to their publishers.
It seems to me that YouTube need to change their approach to updating statistics across the watch pages, Insight and gData.
Firstly, it is important to have the watch page, Insight and gData in sync - otherwise what number would you use in a report? If the gData API for YouTube statistics lags behind the watch page and Insight by even 24 hours, it is useless in indicating trends and for using in reports and people have to go back to screenscraping to gain information on the actual views of their videos.
Secondly, it would be good to update the statistics daily during the first 3-4 weeks, or as long as the videos are gaining views heavily. This is the important time to track the success of videos and if neither Insight nor gData are up to date in this time, and can even be almost 100% off, the statistics are actually useless.
Lastly, one has to wonder how accurate the success calculations are for YouTube partners, who rely on YouTube reporting to gain payment for advertising. Since the analysis showed that the inaccuracies extend also into partner channels, one has to hope that the data that is eventually reported through Insight is actually accurate, even if intermittently there are large differences.
Finally, I must say that I was rather disappointed with the way in which this issue has so far been dealt with in the YouTube Forums. The issues about wrongly reported view counts has been reported first more than a year ago and since regularly by diverse people. Some of the reports were really unfriendly with their demands. Still, I would have expected a serious reply by a YouTube employee about why there are issues and how they are going to be fixed or whether they will be fixed at all. Instead, all I found was a more than 9 month old mention that YouTube seems to be aware of the issue and working on it - no news since.
Also, I found no other blog posts analysing this issue, so here we are. Please, YouTube, let us know what is going on with Insight, why are the numbers off by this much, and what are you doing to fix it?
NB: I just posted a bug on gData, since we were unable to find any concrete bugs relating to this issue there. I’m actually surprised about this, since so many people reported it in the YouTube Forums!
In the previous post I explained that there is a need to expose the tracks of a time-linear media resource to the user agent (UA). Here, I want to look in more detail at different possibilities of how to do so, their advantages and disadvantages.
Note: A lot of this has come out of discussions I had at the recent W3C TPAC and is still in flux, so I am writing this to start discussions and brainstorm.
Declarative Syntax vs JavaScript API
We can expose a media resource’s tracks either through a JavaScript function that can loop through the tracks and provide access to the tracks and their features, or we can do this through declarative syntax.
Using declarative syntax has the advantage of being available even if JavaScript is disabled in a UA. The markup can be parsed easily and default displays can be prepared without having to actually decode the media file(s).
OTOH, it has the disadvantage that it may not necessarily represent what is actually in the binary resource, but instead what the Web developer assumed was in the resource (or what he forgot to update). This may lead to a situation where a “404” may need to be given on a media track.
A further disadvantage is that when somebody copies the media element onto another Web page, together with all the track descriptions, and then the original media resource is changed (e.g. a subtitle track is added), this has not the desired effect, since the change does not propagate to the other Web page.
For these reasons, I thought that a JavaScript interface was preferable over declarative syntax.
However, recent discussions, in particular with some accessibility experts, have convinced me that declarative syntax is preferable, because it allows the creation of a menu for turning tracks on/off without having to even load the media file. Further, declarative syntax allows to treat multiple files and “native tracks” of a virtual media resource in an identical manner.
Extending Existing Declarative Syntax
The HTML5 media elements already have declarative syntax to specify multiple source media files for media elements. The element is typically used to list video in mpeg4 and ogg format for support in different browsers, but has also been envisaged for different screensize and bandwidth encodings.
The elements are generally meant to list different resources that contribute towards the media element. In that respect, let’s try using it for declaring a manifest of tracks of the virtual media resource on an example:
Note that this somewhat ignores my previously proposed special itext tag for handling text tracks. I am doing this here to experiment with a more integrative approach with the virtual media resource idea from the previous post. This may well be a better solution than a specific new text-related element. Most of the attributes of the itext element are, incidentally, covered.
You will also notice that some of the tracks are references to tracks inside binary media files using the Media Fragment URI specification while others link to full files. An example is video.ogv?track=auddesc[en]. So, this is a uniform means of exposing all the tracks that are part of a (virtual) media resource to the UA, no matter whether in-band or in external files. It actually relies on the UA or server being able to resolve these URLs.
”type” attribute
“media” and “type” are existing attributes of the element in HTML5 and meant to help the UA determine what to do with the referenced resource. The current spec states:
The “type” attribute gives the type of the media resource, to help the user agent determine if it can play this media resource before fetching it.
The word “play” might need to be replaced with “decode” to cover several different MIME types.
The “type” attribute was also extended with the possibility to add the “charset” MIME parameter of a linked text resource - this is particularly important for SRT files, which don’t handle charsets very well. It avoids having to add an additional attribute and is analogous to the “codecs” MIME parameter used by audio and video resources.
”media” attribute
Further, the spec states:
The “media” attribute gives the intended media type of the media resource, to help the user agent determine if this media resource is useful to the user before fetching it. Its value must be a valid media query.
The “mobile” and “desktop” values are hints that I’ve used for simplicity reasons. They could be improved by giving appropriate bandwidth limits and width/height values, etc. Other values could be different camera angles such as topview, frontview, backview. The media query aspect has to be looked into in more depth.
”lang” attribute
The above example further uses “lang” and “role” attributes:
The “lang” attribute is an existing global attribute of HTML5, which typically indicates the language of the data inside the element. Here, it is used to indicate the language of the referenced resource. This is possibly not quite the best name choice and should maybe be called “hreflang”, which is already used in multiple other elements to signify the language of the referenced resource.
”role” attribute
The “role” attribute is also an existing attribute in HTML5, included from ARIA. It currently doesn’t cover media resources, but could be extended. The suggestion here is to specify the roles of the different media tracks - the ones I have used here are:
“media”: a main media resource - typically contains audio and video and possibly more
“dub”: a audio track that provides an alternative dubbed language track
“auddesc”: a audio track that provides an additional audio description track
“caption”: a text track that provides captions
“sign”: a video-only track that provides an additional sign language video track
“tad”: a text track that provides textual audio descriptions to be read by a screen reader or a braille device
Further roles could be “music”, “speech”, “sfx” for audio tracks, “subtitle”, “lyrics”, “annotation”, “chapters”, “overlay” for text tracks, and “alternate” for a alternate main media resource, e.g. a different camera angle.
Track activation
The given attributes help the UA decide what to display.
It will firstly find out from the “type” attribute if it is capable of decoding the track.
Then, the UA will find out from the “media” query, “role”, and “lang” attributes whether a track is relevant to its user. This will require checking the capabilities of the device, network, and the user preferences.
Further, it could be possible for Web authors to influence whether a track is displayed or not through CSS parameters on the element: “display: none” or “visibility: hidden/visible”.
Examples for track activation that a UA would undertake using the example above:
Given a desktop computer with Firefox, German language preferences, captions and sign language activated, the UA will fetch the original video at video.ogv (for Firefox), the German caption track at video.ogv?track=caption[de], and the German sign language track at signvid_gsg.ogv (maybe also the German dubbed audio track at video.ogv?track=audio[de], which would then replace the original one).
Given a desktop computer with Safari, English language preferences and audio descriptions activated, the UA will fetch the original video at video.mp4 (for Safari) and the textual audio description at tad_en.srt to be displayed through the screen reader, since it cannot decode the Ogg audio description track at video.ogv?track=auddesc[en].
Also, all decodeable tracks could be exposed in a right-click menu and added on-demand.
Display styling
Default styling of these tracks could be:
video or alternate video in the video display area,
sign language probably as picture-in-picture (making it useless on a mobile and only of limited use on the desktop),
captions/subtitles/lyrics as overlays on the bottom of the video display area (or whatever the caption format prescribes),
textual audio descriptions as ARIA live regions hidden behind the video or off-screen.
Multiple audio tracks can always be played at the same time.
The Web author could also define the display area for a track through CSS styling and the UA would then render the data into that area at the rate that is required by the track.
How good is this approach?
The advantage of this new proposal is that it builds basically on existing HTML5 components with minimal additions to satisfy requirements for content selection and accessibility of media elements. It is a declarative approach to the multi-track media resource challenge.
However, it leaves most of the decision on what tracks are alternatives of/additions to each other and which tracks should be displayed to the UA. The UA makes an informed decision because it gets a lot of information through the attributes, but it still has to make decisions that may become rather complex. Maybe there needs to be a grouping level for alternative tracks and additional tracks - similar to what I did with the second itext proposal, or similar to the and elements of SMIL.
A further issue is one that is currently being discussed within the Media Fragments WG: how can you discover the track composition and the track naming/uses of a particular media resource? How, e.g., can a Web author on another Web site know how to address the tracks inside your binary media resource? A HTML specification like the above can help. But what if that doesn’t exist? And what if the file is being used offline?
Alternative Manifest descriptions
The need to manifest the track composition of a media resource is not a new one. Many other formats and applications had to deal with these challenges before - some have defined and published their format.
I am going to list a few of these formats here with examples. They could inspire a next version of the above proposal with grouping elements.
Microsoft ISM files (SMIL subpart)
With the release of IIS7, Microsoft introduced “Smooth Streaming”, which uses chunking on files on the server to deliver adaptive streaming to Silverlight clients over HTTP. To inform a smooth streaming client of the tracks available for a media resource, Microsoft defined ism files: IIS Smooth Streaming Server Manifest files.
This is a short example - a longer one can be found here:
HTML5 has been criticised for not having a timing model of the media resource in its new media elements. This article spells it out and builds a framework of how we should think about HTML5 media resources. Note: these are my thoughts and nothing offical from HTML5 - just conclusions I have drawn from the specs and from discussions I had.
What is a time-linear media resource?
In HTML5 and also in the Media Fragment URI specification we deal only with audio and video resources that represent a single timeline exclusively. Let’s call such Web resources a time-linear media resource.
The resource can potentially consist of any number of audio, video, text, image or other time-aligned data tracks. All these tracks adhere to a single timeline, which tends to be defined by the main audio or video track, while other tracks have been created to synchronise with these main tracks.
This model matches with the world view of video on YouTube and any other video hosting service. It also matches with video used on any video streaming service.
Background on the choice of “time-linear”
I’ve deliberately chosen the word “time-linear” because we are talking about a single, gap-free, linear timeline here and not multiple timelines that represent the single resource.
The word “linear” is, however, somewhat over-used, since the introduction of digital systems into the world of analog film introduced what is now known as “non-linear video editing”. This term originates from the fact that non-linear video editing systems don’t have to linearly spool through film material to get to a edit point, but can directly access any frame in the footage as easily as any other.
When talking about a time-linear media resource, we are referring to a digital resource and therefore direct access to any frame in the footage is possible. So, a time-linear media resource will still be usable within a non-linear editing process.
As a Web resource, a time-linear media resource is not addressed as a sequence of frames or samples, since these are encoding specific. Rather, the resource is handled abstractly as an object that has track and time dimensions - and possibly spatial dimensions where image or video tracks are concerned. The framerate encoding of the resource itself does not matter and could, in fact, be changed without changing the resource’s time, track and spatial dimensions and thus without changing the resource’s address.
Interactive Multimedia
The term “time-linear” is used to specify the difference between a media resource that follows a single timeline, in contrast to one that deals with multiple timelines, linked together based on conditions, events, user interactions, or other disruptions to make a fully interactive multi-media experience. Thus, media resources in HTML5 and Media Fragments do not qualify as interactive multimedia themselves because they are not regarded as a graph of interlinked media resources, but simply as a single time-linear resource.
In this respect, time-linear media resources are also different from the kind of interactive mult-media experiences that an Adobe Shockwave Flash, Silverlight, or a SMIL file can create. These can go far beyond what current typical video publishing and communication applications on the Web require and go far beyond what the HTML5 media elements were created for. If your application has a need for multiple timelines, it may be necessary to use SMIL, Silverlight, or Adobe Flash to create it.
Note that the fact that the HTML5 media elements are part of the Web, and therefore expose states and integrate with JavaScript, provides Web developers with a certain control over the playback order of a time-linear media resource. The simple functions pause(), play(), and the currentTime attribute allow JavaScript developers to control the current playback offset and whether to stop or start playback. Thus, it is possible to interrupt a playback and present, e.g. a overlay text with a hyperlink, or an additional media resource, or anything else a Web developer can imagine right in the middle of playing back a media resource.
In this way, time-linear media resources can contribute towards an interactive multi-media experience, created by a Web developer through a combination of multiple media resources, image resources, text resources and Web pages. The limitations of this approach are not yet clear at this stage - how far will such a constructed multi-media experience be able to take us and where does it become more complicated than an Adobe Flash, Silverlight, or SMIL experience. The answer to this question will, I believe, become clearer through the next few years of HTML5 usage and further extensions to HTML5 media may well be necessary then.
Proper handling of time-linear media resources in HTML5
At this stage, however, we have already determined several limitations of the existing HTML5 media elements that require resolution without changing the time-linear nature of the resource.
1. Expose structure
Above all, there is a need to expose the above painted structure of a time-linear media resource to the Web page. Right now, when the
We need a means to expose the available tracks inside a time-linear media resource and allow the UA some control over it - e.g. to choose whether to turn on/off a caption track, to choose which video track to display, or to choose which dubbed audio track to display.
I’ll discuss in another article different approaches on how to expose the structure. Suffice for now that we recognise the need to expose the tracks.
2. Separate the media resource concept from actual files
A HTML page is a sequence of HTML tags delivered over HTTP to a UA. A HTML page is a Web resource. It can be created dynamically and contain links to other Web resources such as images which complete its presentation.
We have to move to a similar “virtual” view of a media resource. Typically, a video is a single file with a video and an audio track. But also typically, caption and subtitle tracks for such a video file are stored in other files, possibly even on other servers. The caption or subtitle tracks are still in sync with the video file and therefore are actual tracks of that time-linear media resource. There is no reason to treat this differently to when the caption or subtitle track is inside the media file.
When we separate the media resource concept from actual files, we will find it easier to deal with time-linear media resources in HTML5.
3. Track activation and Display styling
A time-linear media resource, when regarded completely abstractly, can contain all sorts of alternative and additional tracks.
For example, the existing elements inside a video or audio element are currently mostly being used to link to alternative encodings of the main media resource - e.g. either in mpeg4 or ogg format. We can regard these as alternative tracks within the same (virtual) time-linear media resource.
Similarly, the elements have also been suggested to be used for alternate encodings, such as for mobile and Web. Again, these can be regarded as alternative tracks of the same time-linear media resource.
Another example are subtitle tracks for a main media resource, which are currently discussed to be referenced using the element. These are in principle alternative tracks amongst themselves, but additional to the main media resource. Also, some people are actually interested in displaying two subtitle tracks at the same time to learn translations.
Another example are sign language tracks, which are video tracks that can be regarded as an alternative to the audio tracks for hard-of-hearing users. They are then additional video tracks to the original video track and it is not clear how to display more than one video track. Typically, sign language tracks are displayed as picture-in-picture, but on the Web, where video is usually displayed in a small area, this may not be optimal.
As you can see, when deciding which tracks need to be displayed one needs to analyse the relationships between the tracks. Further, user preferences need to come into play when activating tracks. Finally, the user should be able to interactively activate tracks as well.
Once it is clear, what tracks need displaying, there is still the challenge of how to display them. It should be possible to provide default displays for typical track types, and allow Web authors to override these default display styles since they know what actual tracks their resource is dealing with.
While the default display seems to be typically an issue left to the UA to solve, the display overrides are typically dealt with on the Web through CSS approaches. How we solve this is for another time - right now we can just state the need for algorithms for track activiation and for default and override styling.
Hypermedia
To make media resources a prime citizens on the Web, we have to go beyond simply replicating digital media files. The Web is based on hyperlinks between Web resources, and that includes hyperlinking out of resources (e.g. from any word within a Web page) as well as hyperlinking into resources (e.g. fragment URIs into Web pages).
To turn video and audio into hypervideo and hyperaudio, we need to enable hyperlinking into and out of them.
Hyperlinking into media resources is fortunately already being addressed by the W3C Media Fragments working group, which also regards media resources in the same way as HTML5. The addressing schemes under consideration are the following:
temporal fragment URI addressing: address a time offset/region of a media resource
spatial fragment URI addressing: address a rectangular region of a media resource (where available)
track fragment URI addressing: address one or more tracks of a media resource
named fragment URI addressing: address a named region of a media resource
a combination of the above addressing schemes
With such addressing schemes available, there is still a need to hook up the addressing with the resource. For the temporal and the spatial dimension, resolving the addressing into actual byte ranges is relatively obvious across any media type. However, track addressing and named addressing need to be resolved. Track addressing will become easier when we solve the above stated requirement of exposing the track structure of a media resource. The name definition requires association of an id or name with temporal offsets, spatial areas, or tracks. The addressing scheme will be available soon - whether our media resources can support them is another challenge to solve.
Finally, hyperlinking out of media resources is something that is not generally supported at this stage. Certainly, some types of media resources - QuickTime, Flash, MPEG4, Ogg - support the definition of tracks that can contain HTML marked-up text and thus can also contain hyperlinks. But standardisation in this space has not really happened yet. It seems to be clear that hyperlinks out of media files will come from some type of textual track. But a standard format for such time-aligned text tracks doesn’t yet exist. This is a challenge to be addressed in the near future.
Summary
The Web has always tried to deal with new extensions in the simplest possible manner, providing support for the majority of current use cases and allowing for the few extraordinary use cases to be satisfied by use of JavaScript or embedding of external, more complex objects.
With the new media elements in HTML5, this is no different. So far, the most basic need has been satisfied: that of including simple video and audio files into Web pages. However, many basic requirements are not being satisfied yet: accessibility needs, codec choice, device-independence needs are just some of the core requirements that make it important to extend our view of
This post has created the concept of a “media resource”, where we keep the simplicity of a single timeline. At the same time, it has tried to classify the list of shortcomings of the current media elements in a way that will help us address these shortcomings in a Web-conformant means.
If we accept the need to expose the structure of a media resource, the need to separate the media resource concept from actual files, the need for an approach to track activation, and the need to deal with styling of displayed tracks, we can take the next steps and propose solutions for these.
Further, understanding the structure of a media resources allows us to start addressing the harder questions of how to associate events with a media resource, how to associate a navigable structure with a media resource, or how to turn media resources into hypermedia.
Last week’s TPAC (2009 W3C Technical Plenary / Advisory Committee) meetings were my second time at a TPAC and I found myself becoming highly involved with the progress on accessibility on the HTML5 video element. There were in particular two meetings of high relevanct: the Video Accessibility workshop and Friday’s HTML5 breakout group on the video element.
HTML5 Video Accessibility Workshop
The week started on Sunday with the “HTML5 Video Accessibility workshop” at Stanford University, organised by John Foliot and Dave Singer. They brought together a substantial number of people all representing a variety of interest groups. Everyone got their chance to present their viewpoint - check out the minutes of the meeting for a complete transcript.
The list of people and their discussion topics were as follows:
Accessibility Experts
Janina Sajka, chair of WAI Protocols and Formats: represented the vision-impaired community and expressed requirements for a deeply controllable access interface to audio-visual content, preferably in a structured manner similar to DAISY.
Sally Cain, RNIB, Member of W3C PF group: expressed a deep need for audio descriptions, which are often overlooked besides captions.
Ken Harrenstien, Google: has worked on captioning support for video.google and YouTube and shared his experiences, e.g. http://www.youtube.com/watch?v=QRS8MkLhQmM, and automated translation.
Victor Tsaran, Yahoo! Accessibility Manager: joined for a short time out of interest.
Practicioners
John Foliot, professor at Stanford Uni: showed a captioning service that he set up at Stanford University to enable lecturers to publish more accessible video - it uses humans for transcription, but automated tools to time-align, and provides a Web interface to the staff.
Matt May, Adobe: shared what Adobe learnt about accessibility in Flash - in particular that an instream-only approach to captions was a naive approach and that external captions are much more flexible, extensible, and can fit into current workflows.
Frank Olivier, Microsoft: attended to listen and learn.
Technologists
Pierre-Antoine Champin from Liris (France), who was not able to attend, sent a video about their research work on media accessibility using automatic and manual annotation.
Hironobu Takagi, IBM Labs Tokyo, general chair for W4A: demonstrated a text-based audio description system combined with a high-quality, almost human-sounding speech synthesizer.
Dick Bulterman, Researcher at CWI in Amsterdam, co-chair of SYMM (group at W3C doing SMIL): reported on 14 years of experience with multimedia presentations and SMIL (slides) and the need to make temporal and spatial synchronisation explicit to be able to do the complex things.
Cortado is a java applet that provides support for Ogg Theora/Vorbis to Web publishers. It’s particularly useful to publishers that want to use Ogg Theora/Vorbis in Browsers that do not yet support the HTML5 video element with Ogg.
Cortado was originally developed by Fluendo SA under a LGPL license and contains a re-implementation of Theora and Vorbis in Java (jheora and jcraft). After a few years of low maintenance, the Wikimedia Foundation took it in their hands to undust the code for their use in the Wikimedia Commons, where only unencumberd open video format are acceptable.
The new version is tagged 0.5.0 to indicate both the change in hosting and the significant new support for files from the new libtheora encoder implementation and Kate embedded subtitles.
In particular, 0.5.0 has:
Support for files encoded with Theora 1.1
Faster YUV to RGB conversion with better results
Basic support for embedded Ogg Kate streams
Seeking fixed for files with an Ogg Skeleton track
Maintained compatibility with the Microsoft VM
This is an awesome example of the power of open source and what a group of people can achieve. Congratulations to everyone at Xiph, Wikipedia, and anyone else who contributed to the release!
We are slowly approaching the stage where we want to make multi-track video of the following type available and accessible:
original video track
original audio track
dubbed audio tracks in n different languages
audio description track in n different langauges
sign language video tracks in n different sign langauges
caption tracks in n different langauges
multiple other time-aligned text tracks in different langauges
audio and video track from different camera angles
music and speech tracks can be separate
different quality tracks are available
accompanying images, e.g. slides for a presentation
One of the issues with such a sizeable number of tracks is how to display them. Some of them are alternatives, some of them additions. Sign language is typically presented in a PiP (picture-in-picture) approach. If we have a music and a speech (or singing) track, we may want to have control over removing certain tracks - e.g. to be able to do karaoke. Caption and subtitle tracks in the same language are probably alternatives, while in different languages they could be additions. It is not a trivial challenge to handle such complex files in an application.
At this point, I am only trying to solve a sub-challenge. As we talk about a particular track in a multi-track media file, we will want to identify it by name. Should there be a standard for naming the track, so that we can e.g. address them by a URL, e.g. with the intention of only delivering a subset of tracks from the larger file? We could introduce that for Ogg - but maybe there is an opportunity to do this across file formats?
To find some answers to these and related questions, I want to discuss two approaches.
The first approach is a simple numbering approach. In it, the audio, video, and annotation tracks are all ordered and then numbered through. This will result in the following sets of track names: video[0] … [n], audio[0] … [n], timed text[0] … [n], and possibly even timed images[0] … [n]. This approach is simple, easy to understand, and only requires ordering the tracks within their types. It allows addressing of a particular track - e.g. as required by the media fragment URI scheme for track addressing. However, it does not allow identification of alternatives, additions, or presentation styles.
Should alternatives, additions, and presentation styles be encoded in the name of track? Or should this information go into a meta description area of the multi-track video? Something like skeleton in Ogg? Or should it go a step further and be buried in an external information file such as an m3u file (or ROE for Ogg)?
I want to experiment here with the naming scheme and what we would need to specify to be able to decide which tracks to ignore and which to combine for a presentation. And I want to ask for your comments and advice.
This requires listing exactly what types of content tracks we may have to deal with.
In the video space, we have at minimum the following track types:
main video content - with alternative camera angles
subsidiary video content - with alternative camera angles
sign language videos - in alternative languages
Alternatives are defined by camera angle and language. Also, each track can be made available in a different quality. I’d also regard additional image content, such as slides in a presentation, into subsidiary video content. So, here we could use a scheme such as video_[main,side,sign]_language_angle.
In the audio space, we have at minimum the following track types:
main audio content - in alternative languages
background audio content - e.g.music, SFX, noise
foreground speech or singing content - in alternative languages
audio descriptions - in alternative languages
Alternatives are defined by language and content type. Again, each track can be made available in a different quality. Here we could use a scheme such as audio_type_language.
In the text space, we have at minimum the following track types:
subtitles - in different languages
captions - in different languages
textual audio descriptions - in different languages
other time-aligned text - in different languages
Alternatives are defined by language and content type - e.g. lyrics, captions and subtitles really compete for the same screen space. Here we could use a scheme such as text_type_language.
A generic track naming scheme It seems, the generic naming scheme of
<content_type>_<track_type>_ [_]
can cover all cases.
Are there further track types, further alternatives I have missed? What do you think?
_This talk focuses on the efforts engaged by W3C to improve the new HTML 5 media elements with mechanisms to allow people to access multimedia content, including audio and video. Such developments are also useful beyond accessibility needs and will lead to a general improvement of the usability of media, making media discoverable and generally a prime citizen on the Web.
Silvia will discuss what is currently technically possible with the HTML5 media elements, and what is still missing. She will describe a general framework of accessibility for HTML5 media elements and present her work for the Mozilla Corporation that includes captions, subtitles, textual audio annotations, timed metadata, and other time-aligned text with the HTML5 media elements. Silvia will also discuss work of the W3C Media Fragments group to further enhance video usability and accessibility by making it possible to directly address temporal offsets in video, as well as spatial areas and tracks._
On Wednesday evening I gave a 3 min presentation on video accessibility in HTML5 at the WebJam in Sydney. I used a video as my presentation means and explained things while playing it back. Here is the video, without my oral descriptions, but probably still useful to some. Note in particular how you can experience the issues of deaf (HoH), blind (VI) and foreign language users:
The feedback has encouraged me to develop a new specification that includes the concerns and makes it easier to associate out-of-band time-aligned text (i.e. subtitles stored in separate files to the video/audio file). A simple example of the new specification using srt files is this:
By default, the charset of the itext file is UTF-8, and the default format is text/srt (incidentally a mime type the still needs to be registered). Also by default the browser is expected to select for display the track that matches the set default language of the browser. This has been proven to work well in the previous experiments.
Check out the new itext specification, read on to get an introduction to what has changed, and leave me your feedback if you can!
The itextlist element You will have noticed that in comparison to the previous specification, this specification contains a grouping element called “itextlist”. This is necessary because we have to distinguish between alternative time-aligned text tracks and ones that can be additional, i.e. displayed at the same time. In the first specification this was done by inspecting each itext element’s category and grouping them together, but that resulted in much repetition and unreadable specifications.
Also, it was not clear which itext elements were to be displayed in the same region and which in different ones. Now, their styling can be controlled uniformly.
The final advantage is that association of callbacks for entering and leaving text segments as extracted from the itext elements can now be controlled from the itextlist element in a uniform manner.
This change also makes it simple for a parser to determine the structure of the menu that is created and included in the controls element of the audio or video element.
Incidentally, a patch for Firefox already exists that makes this part of the browser. It does not yet support this new itext specification, but here is a screenshot that Felipe Corr
The workshop will take place on 1st November at Stanford University - see details on the Workshop. If you read the announcement, you will see that this is about understanding all the issues around video (and audio) accessibility, understanding existing approaches, and trying to find solutions for HTML5 that all browser vendors will be able to support.
W3C membership is not required in order to participate in the gathering. However, you are required to contribute your knowledge actively and constructively to the Workshop. You must come prepared to present on one of the questions in this document to help inform the discussion and make progress on proposing solutions.
I am very excited about this workshop because I think it is high time to move things forward.
If I can get my travel sorted, I will present my results on the video accessibility work that I did for Mozilla. It will cover both: out-of-band accessibility data for video elements, as well as in-line accessibility data and how to expose a common API in the Web browser for them. I have recently experimented with encoding srt and lrc files in Ogg and displaying them in Firefox by using the patches that were contributed by OggK and Felipe into Firefox. More about this soon.
Just a brief note to let everyone know about a new wikipage I created for my Mozilla work about video accessibility, where I want to track the status and outcomes of my work. You can find it at https://wiki.mozilla.org/Accessibility/Video_a11y_Aug09. It lists the following sections: Test File Collection, Specifications, Demo implementations using JavaScript, Related open bugs in Mozilla, and Publications.
As part of my experiments in video accessibility I am also looking at the audio element. I have just finished a proof of concept for parsing Lyrics files for music in lrc format.
Looking at accessibility for video includes sign language. It is a most fascinating area to get into and an area that still leaves a lot to formalise and standardise. A lot has happened in recent years and a lot still needs to be done.
Sign languages are different languages to spoken languages: they emerged in parallel to spoken languages in communities whose boundaries may not overlap with the boundaries of spoken languages. However, most developed means to translate spoken language artifacts (i.e. letters) into sign language artifacts (i.e. signs). So, a typical signer will speak/write at least 3-4 “languages”: the spoken language of their hearing peers, lip reading of that spoken language, letter signs of the spoken language, and finally the native sign language of the community they live in.
Encoding sign language in the computer is a real challenge. Firstly, there is the problem of enumerating all available languages. Then there is the challenge to find an alphabet to represent all “characters” that can be used in sign across many (preferably all) sign languages. Then there is the need to encode these characters in a way that computers can deal with. And finally, there is the need to find a screen representation of the characters. In this blog post, I want to describe the status for all of these.
Currently, sign language can only be represented as a video track by recording sign speakers. Once a sign character list together with an encoding and representation means for them and a specification of the different sign languages is available, it is possible to encode sign sentences in computer-readable form. Further, programs can be written that can present sign sentences on screen, that translate between different sign languages, and between sign and spoken languages. Also, avatars can be programmed that actually present animated sign sentences.
Imagine a computer that instead of presenting letters in your spoken language uses sign language characters and has keys with signs on them instead of letters. To a sign speaker this would be a lot more natural, since for most sign is their mother tongue.
Listing all existing sign languages It was a challenge to create codes for all existing spoken languages - the current list of language codes has only been finalised in 1998.
Until the 1980s, scientists assumed that it is impossible to develop as rich a language with signs as with writing and speaking. Thus, the native languages of deaf people were often regarded as inferior to spoken languages. In many countries it was even prohibited to teach the language in schools for the deaf and instead they were taught to speak an oral language and read lips. In France this prohibition was only lifted in 1991! Only in about 1985 was it proven that sign languages are indeed as rich as spoken languages and deserve the right to be called a “language” and be treated as a fully capable means of communication.
So, there hasn’t actually been much time to map out a list of all sign languages. The best list I was able to find is in Wikipedia. It lists 28 N/S American, 38 European, 34 Asia-Pacific-AU/NZ, 30 African, and 13 Middle Eastern sign languages - in summary 143 sign languages. This list contains 177 sign languages.
Interestingly, there is also a new International Sign Language in development called Gestuno which is in use in international events (Olympics, conferences etc.) but has only a limited vocabulary.
While not complete, the current IANA subtag language registry now regards sign languages as valid derivatives of a country’s languages and therefore handles them identically to spoken languages. It’s also extensible such that any sign language not yet registered can still be specified.
Characters for sign languages The written word is very powerful for preserving and sharing information. For a very long time there has been no written representation of sign languages. This is not surprising considering that there are still indigenous spoken languages that have no written representation. Also, the written representation of the spoken language around the community of a sign language would have served the sign community sufficiently for most purposes - except for the accurate capture of their thoughts and sign communications. It would always be a foreign language.
To move sign languages into the 20th century, the invention of characters for signs was necessary.
The real challenge lies in capturing the proper signs deaf people use to communicate amongst themselves.
This is rather challenging, since sign languages uses the hands, head and body, with constantly changing movements and orientations for communication. Thus, while spoken language only has one dimension (sound) over time, sign languages have “three dimensions” and capturing this in characters is difficult. Many sign languages to this date don’t have a widely used written form, e.g. AUSLAN. Mostly in use nowadays are sequences of photos or videos - which of course cannot be computer processed easily.
Two main writing systems have been developed: the phonemic Stokoe notation and the iconic SignWriting.
Stokoe notation was created by William Stokoe for ASL in 1960, with Latin letters and numbers used for the shapes they have in fingerspelling, and iconic glyphs to transcribe the position, movement, and orientation of the hands. Adaptations were made to other sign languages to include further phonemes not found in ASL. Stokoe notation is written left-to-right on a page and can be typed with the proper font installed. It has a Unicode/ASCII mapping, but does not easily apply to other sign languages than ASL since it does not capture all possible signs. It has no representation for facial and body expressions and is therefore a relatively poor representation for sign.
SignWriting was created by Valerie Sutton in 1974, a dancer who had two years earlier developed DanceWriting and later developed MimeWriting, SportsWriting, and ScienceWriting. SignWriting is a writing system which uses visual symbols to represent the handshapes, movements, and facial expressions of sign languages. It is a generic sign alphabet with a list of symbols that can be used to write any sign language in the world.
SignWriting can be easily learnt by signers and is more popular now than Stokoe. Signers compose the symbols together in a spatial way to represent their signs. They then write the composed symbols from top to bottom on a page, similar to other iconic character sets. SignWriting currently supports 73 different sign languages, whose dictionaries and encyclopedias are captured in SignPuddle. This will eventually allow the creation of complete corpora for all sign languages.
Unicode encoding of SignWriting and visual representation Because of its unique challenges of having to cover the spatial combination of symbols as a new symbol rather than just the sequential combination of symbols, it took a while to get a Unicode representation of SignWriting.
A binary representation of SignWriting is defined in ISWA 2008. It is based on a representing 639 base symbols and their potential 6 fill and 16 rotation variants in 61,343 code points, that completely cover the subset of 35023 valid symbol codes. The spatial aspect of SignWriting are encoded in a 2-dimensional coordinate system. The dimensions go from -1919 through 1919 to place the top left corner of the symbol.
SignWriting base symbols are encoded in plane 4 of Unicode, which provides 65,536 code points, easily covering the defined 61,343 Binary SignWriting code points. Further special control and number characters are used to encode the spatial layout.
Visual Representation of SignWriting Valerie Sutton created over 35k individual PNG images for ISWA 2008, which have been reformatted for standard color & reduced file size, and renamed to the character code. They are a font used to represent the signs. The images can be accessed on Valerie’s server.
Closing After learning all this today, I have to say that Valerie Sutton has just turned into a new idol of mine. The achievements with SignWriting and the possibilities it will enable are massive.
Now I just have to figure out what to do when we hit on a sign language track that has been encoded in SignWriting and it represents captions. Maybe it is possible to display sign as overlay but on the left side of the video. This would be similar to some other languages that go from top to bottom rather than left to right.
It should now support ARIA and tab access to the menu, which I have simply put next to the video. I implemented the menu by learning from YUI. My Firefox 3.5.3 actually doesn’t tab through it, but then it also doesn’t tab through the YUI example, which I think is correct. Go figure.
Also, the textual audio descriptions are improved and should now work better with screenreaders.
As soon as some kind soul donates a sign language track for “Elephants Dream”, I will have a pretty complete set of video accessibility tracks for that video. This will certainly become the basis for more video a11y work!
In the W3C Media Fragment Working Group (MFWG) we have had long discussions about the use of the URI query (”?”) or the URI fragment (”#”) addressing approach for addressing directly into media fragments, and the diverse new HTTP headers required to serve such URI requests, considering such side conditions as the stripping-off of fragment parameters from a URI by Web browsers, or the existence of caching Web proxies.
As explained earlier, URI queries request (primary) resources, while URI fragments address secondary resources, which have a relationship to their primary resource. So, in the strictest sense of their specifications, to address segments in media resources without losing the context of the primary resource, we can only use URI fragments.
Browser-supported Media Fragment URIs
For this reason, URI fragments are also the way in which my last media fragment addressing demo has been implemented. For example, I would address
In an effort to give a demo of some of the W3C Media Fragment WG specification capabilities, I implemented a HTML5 page with a video element that reacts to fragment offset changes to the URL bar and the
If you simply load that Web page, you will see the video jump to an offset because it is referred to as “elephants_dream/elephant.ogv#t=20”.
If you change or add a temporal fragment in the URL bar, the video jumps to this time offset and overrules the video’s fragment addressing. (This only works in Firefox 3.6, see below - in older Firefoxes you actually have to reload the page for this to happen.) This functionality is similar to a time linking functionality that YouTube also provides.
When you hit the “play” button on the video and let it play a bit before hitting “pause” again - the second at which you hit “pause” is displayed in the page’s URL bar . In Firefox, this even leads to an addition to the browser’s history, so you can jump back to the previous pause position.
Three input boxes allow for experimentation with different functionality.
The first one contains a link to the current Web page with the media fragment for the current video playback position. This text is displayed for cut-and-paste purposes, e.g. to send it in an email to friends.
The second one is an entry box which accepts float values as time offsets. Once entered, the video will jump to the given time offset. The URL of the video and the page URL will be updated.
The third one is an entry box which accepts a video URL that replaces the . It is meant for experimentation with different temporal media fragment URLs as they get loaded into the
Javascript Hacks
You can look at the source code of the page - all the javascript in use is actually at the bottom of the page. Here are some of the juicy bits of what I’ve done:
Since Web browsers do not support the parsing and reaction to media fragment URIs, I implemented this in javascript. Once the video is loaded, i.e. the “loadedmetadata” event is called on the video, I parse the video’s @currentSrc attribute and jump to a time offset if given. I use the @currentSrc, because it will be the URL that the video element is using after having parsed the @src attribute and all the containing elements (if they exist). This function is also called when the video’s @src attribute is changed through javascript.
This is the only bit from the demo that the browsers should do natively. The remaining functionality hooks up the temporal addressing for the video with the browser’s URL bar.
To display a URL in the URL bar that people can cut and paste to send to their friends, I hooked up the video’s “pause” event with an update to the URL bar. If you are jumping around through javascript calls to video.currentTime, you will also have to make these changes to the URL bar.
Finally, I am capturing the window’s “hashchange” event, which is new in HTML5 and only implemented in Firefox 3.6. This means that if you change the temporal offset on the page’s URL, the browser will parse it and jump the video to the offset time.
Optimisation
Doing these kinds of jumps around on video can be very slow when the seeking is happening on the remote server. Firefox actually implements seeking over the network, which in the case of Ogg can require multiple jumps back and forth on the remote video file with byte range requests to locate the correct offset location.
To reduce as much as possible the effort that Firefox has to make with seeking, I referred to Mozilla’s very useful help page to speed up video. It is recommended to deliver the X-Content-Duration HTTP header from your Web server. For Ogg media, this can be provided through the oggz-chop CGI. Since I didn’t want to install it on my Apache server, I hard coded X-Content-Duration in a .htaccess file in the directory that serves the media file. The .htaccess file looks as follows:
<Files "elephant.ogv"> Header set X-Content-Duration "653.791" </Files>
This should now help Firefox to avoid the extra seek necessary to determine the video’s duration and display the transport bar faster.
I also added the @autobuffer attribute to the
ToDos
This is only a first and very simple demo of media fragments and video. I have not made an effort to capture any errors or to parse a URL that is more complicated than simply containing “#t=”. Feel free to report any bugs to me in the comments or send me patches.
Also, I have not made an effort to use time ranges, which is part of the W3C Media Fragment spec. This should be simple to add, since it just requires to stop the video playback at the given end time.
Also, I have only implemented parsing of the most simple default time spec in seconds and fragments. None of the more complicated npt, smpte, or clock specifications have been implemented yet.
The possibilities for deeper access to video and for improved video accessibility with these URLs are vast. Just imagine hooking up the caption elements of e.g. an srt file with temporal hyperlinks and you can provide deep interaction between the video content and the captions. You could even drive this to the extreme and jump between single words if you mark up each with its time relationship. Happy experimenting!
UPDATE: I forgot to mention that it is really annoying that the video has to be re-loaded when the @src attribute is changed, even if only the hash changes. As support for media fragments is implemented in
Thanks go to Chris Double and Chris Pearce from Mozilla for their feedback and suggestions for improvement on an early version of this.
Say, you are watching Thomas’ live stream from above at http://localhost:8800 and you want to jump back by 2 min. Your player would grab the current streaming time, e.g. 2009-08-26T12:34:04Z and subtract the two minutes, giving 2009-08-26T12:32:04Z. Then the player would use this to tell your streaming server to jump back by two minutes using this URL: http://localhost:8800#t=clock:2009-08-26T12:32:04Z.
Or another example would be: you had a stream running all day from a conference and you want to go back to a particular session. You know that it was between 10am and 11am German time (UTC+2 right now). Then your URL would be as follows: http://conference:8800#t=clock:2009-08-26T10:00+02:00,2009-08-26T11:00+02:00
For many years now I have been progressing a deeper view of video on the Web than just as a binary blob. We need direct access to time offsets and sections of videos.
Such direct access can be achieved either by providing a javascript interface through which a video’s playback position can be controlled, or by using URLs that directly communicate with the Web server about controlling the playback position. I will explain the approaches that can be applied on the HTML5
Controlling a video’s playback with javascript
currentTime
Right now, you can use the video element’s “currentTime” property to read and set the current playback position of a video resource. This is very useful to directly jump between different sections in the video, such as exemplified in the BBC’s recent R&D TV demo. To jump to a time offset in a video, all you have to do in javascript is:
var video = document.getElementsByTagName("video")[0]; video.currentTime = starttimeoffset;
timeupdate
Further, if you want to stop playback at a certain time point, you can use another functionality of the HTML5
When the “timeupdate” event fires, which is supposed to happen at a min resolution of 250ms, you can catch the end of your desired interval fairly accurately.
setTimeout / setInterval
Alternatively to using the “timeupdate” event that is provided by the
The “setTimeout” function is used to call a function or evaluate an expression after a specified number of milliseconds. So, you’d have to call this straight after starting the playback at the given starttimeoffset.
If instead you wanted something to happen at a frequent rate in parallel to the video playback (such as check if you need to display a new ad or a new subtitle), you could use the javascript setInterval function:
The “setInterval” function is used to call a function or evaluate an expression at the specified intervall. So, in the given example, every 100ms it is tested whether a new subtitle needs to be displayed for the video current playback time.
Note that for subtitles it makes a lot more sense to use the existing “timeupdate” event of the video rather than creating a frequenty setInterval interrupt, since this will continue calling the function until clearInterval() is called or the window is closed. Also, the BBC found in experiments with Firefox that “timeupdate” is more accurate than polling the “currentTime” regularly.
Controlling a video’s playback through a URL
There are some existing example implementations that control a video’s playback time through a URL.
More recently, YouTube rolled out a URI scheme to directly jump to an offset in a YouTube video, e.g. http://www.youtube.com/watch?v=PjDw3azfZWI#t=31m09s. While most YouTube content is short form, and such direct access may not make much sense for a video of less than 2 min duration, some YouTube content is long enough to make this a very useful feature.
You may have noticed that the YouTube use of URIs for jumping to offsets is slightly different to the one used by Metavid. The YouTube video will be displayed as always, but the playback position in the video player changes based on the time offset. The Metavid video in contrast will not display a transport bar for the full video, but instead only present the requested part of the video with an appropriate localised keyframe.
Having realised the need for such URLs, the W3C created a Media Fragments working group.
Proposed Time schemes
For temporal addressing, it currently proposes the following schemes:
If there is no time scheme given, it defaults to “npt”, which stands for “normal playback time”. It is basically a time offset given in seconds, but can be provided in a few different formats.
If a “smpte” scheme is given, the time code is provided in the way in which DVRs display time codes, namely according to the SMPTE timecode standard.
Finally, a “clock” time scheme can be given. This is relevant in particular to live streaming applications, which would like to provide a URL under which a live video is provided, but also allow the user to jump back in time to previously streamed data.
Fragments and Queries
Further, the W3C Media Fragment Working Group is discussing the use of both URI addressing schemes for time offsets: fragments (”#”) and queries (”?”).
The important difference is that queries produce a new resource, while fragments provide a sub-resource.
This means that if you load a URI such as http://www.example.org/video.ogv?t=60,100 , the resulting resource is a video of duration 40s. Since relates to the full resource, it is possible to expect from the user agent (i.e. web browser) to display a timeline of 60-100 rather than 0-40 - after all, the browser could just get this out of the URL. However, it is essentially a new resource and could therefore just be regarded as a different video.
If instead you load a URI such as http://www.example.org/video.ogv#t=60,100, the user agent recognizes http://www.example.org/video.ogv as the resource and knows that it is supposed to display the 40s extract of that resource. Using no special server support, the browser could just implement this using the currentTime and timeUpdate javascript functionality.
An optimisation should, however, be made on this latter fragment delivery such that a user does not have to wait until the full beginning of the resource is downloaded before playback starts: Web servers should be expected to implement a server extension that can deal with such offsets and then deliver from the time offset rather than the beginning of the file.
How this is communicated to the server - what extra headers or http communication mechanisms should be used - is currently under discussion at the W3C Media Fragments working group.
In the last week, I have received many emails replying to my request for feedback on the video accessibility demo. Thanks very much to everyone who took the time.
Interestingly, I got very little feedback on the subtitles and textual audio annotation aspects of my demo, actually, even though that was the key aspect of my analysis. It’s my own fault, however, because I chose a good looking video player skin over an accessible one.
This is where I need to take a step back and explain about the status of HTML5 video and its general accessibility aspects. Some of this is a repetition of an email that I sent to the W3C WAI-XTECH mailing list.
Browser support of HTML5 video
The HTML5 video tag is still a rather new tag that has not been implemented in all browsers yet - and not all browsers support the Ogg Theora/Video codec that my demo uses. Only the latest Firefox 3.5 release will support my demo out of the box. For Chrome and Opera you will have to use the latest nightly build (which I am not even sure are publicly available). IE does not support it at all. For Safari/Webkit you will need the latest release and install the XiphQT quicktime component to provide support for the codec.
My recommendation is clearly to use Firefox 3.5 to try this demo.
Standardisation status of HTML5 video
The standardisation of the HTML5 video tag is still in process. Some of the attributes have not been validated through implementations, some of the use cases have not been turned into specifications, and most importantly to the topic of interest here, there have been very little experiments with accessibility around the HTML5 video tag.
Accessibility of video controls
Most of the comments that I received on my demo were concerned with the accessibility of the video controls.
In HTML5 video, there is a attribute called @controls. If it is available, the browser is expected to display default controls on top of the video. Here is what the current specification says:
“This user interface should include features to begin playback, pause playback, seek to an arbitrary position in the content (if the content supports arbitrary seeking), change the volume, and show the media content in manners more suitable to the user (e.g. full-screen video or in an independent resizable window).”
In Firefox 3.5, the controls attribute currently creates the following controls:
play/pause button (toggles between the two)
slider for current playback position and seeking (also displays how much of the video has currently been downloaded)
duration display
roll-over button for volume on/off and to display slider for volume
FAIK fullscreen is not currently implemented
Further, the HTML5 specification prescribes that if the @controls attribute is not available, “user agents may provide controls to affect playback of the media resource (e.g. play, pause, seeking, and volume controls), but such features should not interfere with the page’s normal rendering. For example, such features could be exposed in the media element’s context menu.”
In Firefox 3.5, this has been implemented with a right-click context menu, which contains:
play/pause toggle
mute/unmute toggle
show/hide controls toggle
When the controls are being displayed, there are keyboard shortcuts to control them:
space bar toggles between play and pause
left/right arrow winds video forward/back by 5 sec
CTRL+left/right arrow winds video forward/back by 60sec
HOME+left/right jumps to beginning/end of video
when focused on the volume button, up/down arrow increases/decreases volume
As for exposure of these controls to screen readers, Mozilla implemented this in June, see Marco Zehe’s blog post on it. It implies having to use focus mode for now, so if you haven’t been able to use keyboard for controlling the video element yet, that may be the reason.
New video accessibility work
My work is actually meant to take video accessibility a step further and explore how to deal with what I call time-aligned text files for video and audio. For the purposes of accessibility, I am mainly concerned with subtitles, captions, and audio descriptions that come in textual form and should be read out by a screen reader or made available to braille devices.
I am exploring both, time-aligned text that comes within a video file, but also those that are available as external Web resources and are just associated to the video through HTML. It is this latter use case that my demo explored.
To create a nice looking demo, I used a skin for the video player that was developed by somebody else. Now, I didn’t pay attention to whether that skin was actually accessible and this is the source of most of the problems that have been mentioned to me thus far.
A new, simpler demo I have now developed a new demo that uses the default player controls which should be accessible as described above. I hope that the extra button that I implemented for the menu with all the text tracks is now accessible through a screen reader, too.
It experiments with four different types of time-aligned text: subtitles, captions, chapters, and textual audio annotations.
It extends the video controls by a menu button for the time-aligned text tracks. This enables the user to switch between different languages for the different tracks.
The textual audio annotations are mapped into an aria-live activated div element, such that they are indeed read out by screen-readers; this div sits behind the video, invisible to everyone else.
The chapters are displayed as text on top of the video.
The subtitles and captions are displayed as overlays at the bottom of the video.
The display styles and positions are supposed to be default display mechanisms for these kinds of tracks, that could be overwritten by the stylesheet of a Web developer, who intends to place the text elsewhere on screen.
In order to “hear” the textual audio annotations work, you will need to install a screen reader such as JAWS, NVDA, or the firevox plugin on the Mac.
As far as I am aware, this is the first demo of HTML5 video accessibility that includes support for the vision-impaired, hearing-impaired, and also for foreign language speakers.
There have been initial discussions about this proposal, the results of which are captured in the wiki page. I expect a lot more heated discussion will happen on the WHATWG mailing list when I post it soon. I am well aware that probably most of the javascript API will need to be changed, and also some of the HTML.
Also please note that there are some bugs still left on the software, which should not inhibit the discussion at this stage. We will definitely develop a newer and better version.
I am particularly proud that I was able to make this work in the experimental builds of Opera and Chrome, as well as in Safari with XiphQT installed, and of course in Firefox 3.5.
It’s already old news, but I am really excited about having started a new part-time contract with Mozilla to continue pushing the HTML5 video and audio elements towards accessibility.
My aim is two-fold: firstly to improve the HTML5 audio and video tags with textual representations, and secondly to hook up the Ogg file format with these accessibility features through an Ogg-internal text codec.
The textual representation that I am after is closely based on the itext elements I have been proposing for a while. They are meant to be a simple way to associate external subtitle/caption files with the HTML5 video and audio tags. I am initially looking at srt and DFXP formats, because I think they are extremes of a spectrum of time-aligned text formats from simple to complex. I am preparing a specification and javascript demonstration of the itext feature and will then be looking for constructive criticism from accessibility, captioning, Web, video and any other expert who cares to provide input. My hope is to move the caption discussion forward on the WHATWG and ultimately achieve a cross-browser standard means for associating time-aligned text with media streams.
The Ogg-internal solution for subtitles - and more generally for time-aligned text - is then a logical next step towards solving accessibility. From the many discussions I have had on the topic of how best to associate subtitles with video I have learnt that there is a need for both: external text files with subtitles, as well as subtitles that are multiplexed with the media into a single binary fie. Here, I am particularly looking at the Kate codec as a means of multiplexing srt and DFXP into Ogg.
Eventually, the idea is to have a seamless interface in the Web Browser for dealing with subtitles, captions, karaoke, timed metadata, and similar time-aligned text. The user interaction should be identical no matter whether the text comes from within a binary media file or from a secondary Web resource. Once this seamless interface exists, hooking up accessibility tools such as screen readers or braille devices to the data should in theory be simple.
Now that Firefox 3.5 is released with native HTML5
This blog post collects the javascript libraries that I have found thus far and that are for different purposes, so you can pick the one most appropriate for you. Be aware that the list is probably already outdated when I post the article, so if you could help me keeping it up-to-date with comments, that would be great. :-)
Before I dig into the libraries, let me explain how fallback works with
Generally, if you’re using the HTML5
<video src="video.ogv" controls> Your browser does not support the HTML5 video element. </video>
To do more than just text, you could provide a video fallback option. There are basically two options: you can fall back to a Flash solution:
You can of course combine all the methods above to optimise the experience for your users, which is what has been done in this and this (Video For Everybody) example without the use of javascript. I actually like these approaches best and you may want to check them out before you consider using a javascript library.
But now, let’s look at the promised list of javascript libraries.
Firstly, let’s look at some libraries that let you support more than just one codec format. These allow you to provide video in the format most preferable by the given browser-mediaframework-OS combination. Note that you will need to encode and provide your videos in multiple formats for these to work.
mv_embed: this is probably the library that has been around the longest to provide &let;video> fallback mechanisms. It has evolved heaps over the last years and now supports Ogg Theora and Flash fallbacks.
html5flash: provides on top of the Ogg Theora and MPEG4 codec support also Flash support in the HTML5 video element through a chromeless Flash video player. It also exposes the
foxyvideo: provides a fallback flash player and a JavaScript library for HTML5 video controls that also includes a nearly identical ActionScript implementation.
Finally, let’s look at some libraries that are only focused around Ogg Theora support in browsers:
Celt’s javascript: a minimal javascript that checks for native Ogg Theora
stealthisfilm’s javascript: checks for native support, VLC, liboggplay, Totem, any other Ogg Theora player, and cortado as fallback.
Wikimedia’s javascript: checks for QuickTime, VLC, native, Totem, KMPlayer, Kaffeine and Mplayer support before falling back to Cortado support.
At the recent Open Video Conference, I was asked to chair a working group on HTML5 and the
The biggest topic around the
Unfortunately, the panel was cut short at the conference to only 30 min, so we ended up doing mostly demos of HTML5 video working in different browsers and doing cool things such as working with SVG.
The challenges that we identified and that are still ahead to solve are:
annotation support: closed captions, subtitles, time-aligned metadata, and their DOM exposure
track selection: how to select between alternate audio tracks, alternate annotation tracks, based on e.g. language, or accessibility requirements; what would the content negotiation protocol look like
how to support live streaming
how to support in-browser a/v capture
how to support live video communication (skype-style)
how to support video playlists
how to support basic video editing functionality
what would a decent media server for html5 video look like; what capabilities would it have
Here are the slides we made for the working group.
The W3C has published a third last call for the draft specification of DFXP, the Distribution Format Exchange Profile for the Timed Text Authoring Format - or short: for their new standard format for captions. Comments are due by the 30th June, so rush if you want to give any feedback. Here is what came to my mind as I was reading the 183 pages long document.
Please note: This review looks at DFXP from a Web view, i.e. how compatible is it with existing Web technologies, since my main use case will be on the Web, even if advocates will say that that’s not it’s main purpose, strangely enough, for a standard coming out of the W3C.
The state of affairs with caption formats
When it comes to caption and subtitles, there is no lack of formats. It seems, because it is an easy challenge to define a data format for something as simple as a piece of text and some timing information, every new project that wanted to deal with captions - or more generally timed text - created their own format. I am no exception to the rule. :-)
Thus, the current state of affairs wrt timed text is that there are many different textual file formats to store such data, there are also many different video container formats each with their own data format (or even formats) for embedding timed text into them, and there is a lot of software that will deal with many input, output and encapsulation formats.
The problem with this situation is that the formats are all different in their complexity. The simple “piece of text and timing information” problem can be turned into as complex a problem as you desire. By adding layout information, styling information, animation functionality, metadata about the video and about the content, and possibly hyperlinks, we have ended up in a large mess of incompatible formats.
The aim of W3C Timed Text
The W3C Timed Text working group was chartered in January 2003 to attack this issue. It was supposed to become the super-format of all possible functionalities for timed text formats and therefore a perfect interchange format between applications (see requirements document). Its focus was for use on the Web and with SMIL and to make use of existing W3C technologies where possible
However, the history of captioning is TV and the scope of Timed Text is beyond mere use on the Web, so while W3C Timed Text took a lot of inspiration from other Web standards, it has become a stand-alone standard that does not rely on, e.g. the availability of a CSS engine, and it has no in-built hyperlinking functionality (see what requirements it fulfills).
<tt xml:lang="" xmlns="http://www.w3.org/2006/10/ttaf1"> <head> <metadata xmlns:ttm="http://www.w3.org/2006/10/ttaf1#metadata"> <ttm:title>Timed Text DFXP Example</ttm:title> <ttm:copyright>The Authors (c) 2006</ttm:copyright> </metadata> <styling xmlns:tts="http://www.w3.org/2006/10/ttaf1#styling"> <!-- s1 specifies default color, font, and text alignment --> <style xml:id="s1" tts:color="white" tts:fontFamily="proportionalSansSerif" tts:fontSize="22px" tts:textAlign="center" /> <!-- alternative using yellow text but otherwise the same as style s1 --> <style xml:id="s2" style="s1" tts:color="yellow"/> <!-- a style based on s1 but justified to the right --> <style xml:id="s1Right" style="s1" tts:textAlign="end" /> <!-- a style based on s2 but justified to the left --> <style xml:id="s2Left" style="s2" tts:textAlign="start" /> </styling> <layout xmlns:tts="http://www.w3.org/2006/10/ttaf1#styling"> <region xml:id="subtitleArea" style="s1" tts:extent="560px 62px" tts:padding="5px 3px" tts:backgroundColor="black" tts:displayAlign="after" /> </layout> </head> <body region="subtitleArea"> <div> <p xml:id="subtitle1" begin="0.76s" end="3.45s"> It seems a paradox, does it not, </p> <p xml:id="subtitle2" begin="5.0s" end="10.0s"> that the image formed on<br/> the Retina should be inverted? </p> <p xml:id="subtitle3" begin="10.0s" end="16.0s" style="s2"> It is puzzling, why is it<br/> we do not see things upside-down? </p> <p xml:id="subtitle4" begin="17.2s" end="23.0s"> You have never heard the Theory,<br/> then, that the Brain also is inverted? </p> <p xml:id="subtitle5" begin="23.0s" end="27.0s" style="s2"> No indeed! What a beautiful fact! </p> <p xml:id="subtitle6a" begin="28.0s" end="34.6s" style="s2Left"> But how is it proved? </p> <p xml:id="subtitle6b" begin="28.0s" end="34.6s" style="s1Right"> Thus: what we call </p> <p xml:id="subtitle7" begin="34.6s" end="45.0s" style="s1Right"> the vertex of the Brain<br/> is really its base </p> <p xml:id="subtitle8" begin="45.0s" end="52.0s" style="s1Right"> and what we call its base<br/> is really its vertex, </p> <p xml:id="subtitle9a" begin="53.5s" end="58.7s"> it is simply a question of nomenclature. </p> <p xml:id="subtitle9b" begin="53.5s" end="58.7s" style="s2"> How truly delightful! </p> </div> </body></tt>
I’m going to look at each of the different functionalities separately and discuss their strengths and weaknesses.
Content
Let’s begin with the body of the DFXP document and what elements are defined for this area.
Firstly, comes with optional begin, end, and dur attributes. As is the case for all time specifications in DFXP, there are both “end” and “dur” attributes. Why this over-specification? There is not even an explanation which of the two has higher priority when in conflict. This is plainly asking for trouble - why not simplify the spec?
The “region” and “style” attributes refer to a previously defined region and styles that are applied to the body. “id” and “lang” attributes allow to associate a name and a language with the body.
The “timeContainer” attribute enables the author to specify whether the elements in the body are all to be regarded as temporally parallel or in sequence, the default being parallel. This means that all text elements specified inside the body can render over the top of each other - a situation that is solved by giving them specific start and end times.
tags. The div element functions as a logical container and a temporal structuring element for a sequence of textual content units. div elements like body elements are allowed a “start”, “end” and “dur” attribute and generally everything that the body element also has, except that their children can be more div or p. Again, the children of the div element are all regarded as being temporally parallel.
The p element is basically the inner-most element that contains the actual text, including new-lines (br) and spans to associate further styling, metadata, or animations. The children of the p or span element are also all regarded as being temporally parallel, unless otherwise specified.
The structuring of text into div, p, and span elements seems to make sense and provide sufficient (if not even excessive) flexibility for any required timed text needs.
Layout
Once the text is specified and structured, the next question is where it should be positioned.
The extent attribute of the root element specifies the width and height of the root container, if not specified by the external authoring context.
Inside the root container, regions are defined through explicit elements. The origin of placement for a region is the top left corner. Regions can define their “origin” offset, their “width” and “height”, the alignment of text within them through the “textAlign” and “displayAlign” styles, and whether text that “overflows” a region should be visible or hidden.
The way in which DFXP defines regions and placement of text within regions is very different to the way in which HTML and CSS work. By default, elements in HTML flow one after another in the same order as they appear in the source. CSS attributes applied to the elements can control their positioning through giving coordinates, or relative placements in relation to other elements. In DFXP elements are placed inside regions that are styled, making it incompatible with HTML.
Styling
The styling attributes available for DFXP are limited, but sufficient for timed text purposes. The way in which style associations to elements are resolved is quite diverse. Styles can be associated with regions, with individual elements, individually and as a group, through layouts and through parent elements. Compared to CSS, it feels complicated and potentially full of contradictions.
Animation
Further to styling, DFXP defines animations, which are discrete changes to some style parameter value that applies over some time interval. This is relevant for example to implement karaoke style colouring of text over time.
Metadata
The element serves as a generic container for grouping metadata information. It can be associated virtually with any element - which seems somewhat over-flexible, but provides for interesting meta data information such as meta data for styles or for a .
In addition, metadata is actually limited to a set number of elements: title, desc, copyright, agent, name, and actor. These are strange fields - in particular if you compare them to the flexibility of HTML meta data, which consists of free-form name-value pairs, bringing us domain-specific schemes such as the Dublin Core. This is not easily possible here, but instead one has to define extensions to allow for such flexible meta data.
Other features
DFXP provides other features such as information that describes the related video file, e.g. frameRate, subFrameRate, frameRateMultiplier, pixelAspectRatio, smpteMode, timeBase, and tickRate. Such information will help at the point in time when DFXP is supposed to be multiplexed into a binary media file together with audio and video tracks. These attributes can provide information required for the multiplexing process. I am not sure that justifies their existence though.
Other, minor features are available too. Check out the full specification to get a complete picture.
Examples
Part of the publication of this draft is also a test suite. Several of the defined features are still not represented in the test suite, which to me raises the question if they are really required. It might do wonders to the draft size to remove them.
Summary
DFXP is a standard for timed text that is firmly grounded in past captioning specifications, but written in XML, and borrowing ideas from Web technologies. It is unfortunately not re-using existing Web infrastructure to implement its more complex features: no use of CSS for styling and layout, no use of hyperlinks. Also, the use of namespaces seems excessive and won’t make it easy to author this format, in particular since the defined namespaces do not map into the defined profiles.
DFXP is, however, simple to transcode to something that a Web Browser can deal with through its existing engines, because it has borrowed from other Web standards. It is thus easier to work with on the Web than most other formats. It should be relatively easy to map to HTML, CSS and javascript, as already started in the test suite with the HTML5 video element.
DFXP is witten in such a way that it is possible to put together a new profile with extensions that are more appropriate for specific needs, e.g. that fit better into existing Web infrastructure. Currently, DFXP has three defined profiles: one focused on transformation, one focused on presentation, and one that contains everything.
I think it’s time for a html5 profile of DFXP that at minimum extends DFXP with hyperlinks, making it a real timed text Web format.
In the year 2000, while working at CSIRO as a research scientist, I had the idea that video (and audio) should be hyperlinked content on the Web just like any Web page. Conrad Parker and I developed the vision of a “Continuous Media Web” and called the technology that was necessary to develop “Annodex” for “annotated and indexed media”.
Not many people now know that this was really the beginning of Ogg on the Web. Until then, Ogg Vorbis and the emerging Ogg Theora were only targeted at desktop applications in competition to MP3 and MPEG-2.
Within a few years, we developed the specifications for a markup language for video called CMML that would provide the annotations, anchor points, and hyperlinks for video to make it possible to search and index video, hyperlink into video section, and hyperlink out of video sections.
We further developed the specification of temporal URIs to actually address to temporal offsets or segments in video.
And finally, we developed extensions to the Xiph Ogg framework to allow it to carry CMML, and more generally multi-track codecs. The resulting files were originally called “Annodex files”, but through increasing collaboration with Xiph, the specifications were simplified and included natively into Ogg and are now known as “Ogg Skeleton”.
Apart from specifications, we also developed lots of software to make the vision actually come true. Conrad, in particular, developed many libraries that helped develop software on top of the raw Xiph codecs, which include liboggz and libfishsound. Libraries were developed to deal with CMML and with embedding CMML into Ogg. Apache modules were developed to deal with segmenting sections from Ogg files and deliver them as a reply to a temporal URI request. And finally we actually developed a Firefox extension that would allow us to display the Ogg Theora/Vorbis videos inside a Web Browser.
Over time, a lot more sofware was developed, amongst them: php, perl and python bindings for Annodex, DirectShow filters to have Ogg Theora/Vorbis support on Windows, an ActiveX control for Windows, an authoring tool for CMML on Windows, Ogg format validation software, mobile phone support for Ogg Theora/Vorbis, and a video wiki for CMML and Ogg Theora called cmmlwiki. Several students and Annodex team members at CSIRO helped develop these, including Andre Pang (who now works for Pixar), Zen Kavanagh (who now works for Microsoft), and Colin Ward (who now works for Symbian). Most of the software was released as open source software by CSIRO and is available now either in the Annodex repository or the Xiphrepositories.
Annodex technology became increasingly part of Xiph technology as team members also became increasingly part of the Xiph community, such as by now it’s rather difficult to separate out the Annodex people from the Xiph people.
Over time, other projects picked up on the Annodex technology. The first were in fact ethnographic researchers, who wanted their audio-visual ethnographic recordings usable in deeply. Also, other multimedia scientists experimented with Annodex. The first actual content site to publish a large collection of Ogg Theora video with annotations was OpenRoadTrip by Scott Shawcroft and Brandon Hines in 2006. Soon after, Michael Dale and Aphid from Metavid started really using the Annodex set of technologies and contributing to harden the technology. Michael was also a big advocate for helping Wikimedia and Archive.org move to using Ogg Theora.
By 2006, the team at CSIRO decided that it was necessary to develop a simple, cross-platform Ogg decoding and playback library that would allow easy development of applications that need deep control of Ogg audio and video content. Shane Stephens was the key developer of that. By the time that Chris Double from Firefox picked up liboggplay to include Ogg support into Firefox natively, CSIRO had stopped working on Annodex, Shane had left the project to work for Google on Wave, and we eventually found Viktor Gal as the new maintainer for liboggplay. We also found Cristian Adam as the new maintainer for the DirectShow filters (oggcodecs).
Now that the basic Ogg Theora/Vorbis support for the HTML5
I spent this week at the Open Video Conference in New York and was amazed about the 800 and more people that understand the value of open video and the need for open video technologies to allow free innovation and sharing. I can feel that the ball has got rolling - the vision developed almost 10 years ago is starting to take shape. Sometimes, in very very rare moments, you can feel that history has just been made. The Open Video Conference was exactly one such point in time. Things have changed. Forever. For the better. I am stunned.
On Jun 13th 2009 Chris DiBona of Google claimed on the WhatWG mailing list:
“If [youtube] were to switch to theora and maintain even a semblance of the current youtube quality it would take up most available bandwidth across the Internet.”
Everyone who has ever encoded a Ogg Theora/Vorbis file and in parallel encoded one with another codec will have to immediately protest. It is sad that even the best people fall for FUD spread by the un-enlightened or the ones who have their own agenda.
Fortunately, Gregory Maxwell from Wikipedia came to the rescue and did an actual “YouTube / Ogg/Theora comparison”. It’s a good read and a comparison on one video. He has put his instructions there, so anyone can repeat it for themselves. You will have to start with a pretty good quality video though to see such differences.
I’ve always thought that the most compelling reason to go with HTML5 Ogg video over Flash are the cool things it enables you to do with video within the webpage.
I’ve previously collected the following videos and demos:
First there was a demo of a potential javascript interface to playing Ogg video inside the Web browser, which was developed by CSIRO. The library in use later became the library that Mozilla used in Firefox 3.5:
Then there were Michael Dale’s demos of Metavidwiki with its direct search, access and reuse of video segments, even a little web-based video editor:
Then there was Chris Double’s video SVG demo with cool moving, resizing and reshaping of video:
and Chris kept them coming:
Then Chris Blizzard also made a cool demo for showing synchronised video and graph updates as well as a motion detector:
And now we have Firefox Director Mike Belitzer show off the latest and coolest to TechCrunch, the dynamic content injection bit of which you can try out yourself here:
Yesterday, somebody mentioned that the HTML5 video tag with Ogg Theora/Vorbis can be played back in Safari if you have XiphQT installed (btw: the 0.1.9 release of XiphQT is upcoming). So, today I thought I should give it a quick test. It indeed works straight through the QuickTime framework, so the player looks like a QuickTime player. So, by now, Firefox 3.5, Chrome, Safari with XiphQT, and experimental builds of Opera support Ogg Theora/Vorbis inside the HTML5 video tag. Now we just need somebody to write some ActiveX controls for the Xiph DirectShow Filters and it might even work in IE.
While doing my testing, I needed to go to some sites that actually use Ogg Theora/Vorbis in HTML5 video tags. Here is a list that I came up with in no particular order:
Michael Dale just posted this to theora-dev. Go to one of the given URLs to install the Firefox plugin that lets you transcode video to Ogg using your Web browser.
Firefogg is developed by Jan Gerber and lives at http://www.firefogg.org/. There is a javascript API available so you can make use of Firefogg in your own Website project to allow people to upload any video and transcode it to Ogg on the fly.
Enjoy!
On Fri, Jun 5, 2009 at 7:08 AM, Michael Dale wrote: > I mentioned it in the #theora channel a few days ago but here it is with > a more permanent url: > > http://www.firefogg.org/make/advanced.html > & > http://www.firefogg.org/make/ > > These will be simple links you can send people so that they can encode > source footage to a local ogg video file with the latest and greatest > ogg encoders (presently thusnelda and vorbis). Updates to thusnelda and > possible other free codecs will be pushed out via firefogg updates ;) > > Pass along any feedback if things break or what not. > > I am also doing testing with “embed” these encoder interface. For those > familiar with jQuery: an example to rewrite all your file inputs with > firefogg enhanced inputs: $(“input:[type=‘file’]“).firefogg() … Feel > free to expeirment based on those examples. The form rewrite has mostly > only been tested in the mediaWiki context: > http://sandbox.kaltura.com/testwiki/index.php/Special:Upload > but with minor hacking should work elsewhere :) > > enjoy > —michael > > _______________________________________________ > theora mailing list > theora@xiph.org > http://lists.xiph.org/mailman/listinfo/theora >
This past week was amazing, not because of Google Wave, which everybody seems to be talking about now, and not because of Microsoft’s launch of the bing search engine, but amazing for the world of open video.
YouTube are experimenting with the HTML5 video tag. The demo only works in HTML5 video capable browsers, such as Firefox 3.5, Safari, Opera, and the new Chrome, which leads me straight to the next news.
More importantly even, recently committed code adds Ogg Theora/Vorbis support to Google Chrome 3’s video tag! This is based on using ffmpeg at this stage, which needs some further work to e.g. gain Ogg Kate support. But this is great news for open media!
And then the biggest news:Dailymotion, one of the largest social video networks, has re-encoded all their videos to Ogg Theora/Vorbis and have launched an openvideo platform. The blog post is slightly negative about video quality - probably because they used an older encoder. The Xiph community has already recommended use of recommends experimenting with the new Thusnelda encoder and the latest ffmpeg2theora release that supports it, since they provide higher compression ratios and better quality.
That latest ffmpeg2theora release is really awesome news by itself, but I’d also like to mention two other encoding tools that were released last week: the updated XiphQT QuickTime components, that now allow export to Ogg Theora/Vorbis directly from iMovie (I tested it and it’s awesome) and the new GStreamer command-line based python encoder gst2ogg which works mostly like ffmpeg2theora.
Overall a really exciting week for open media and HTML5 video! I think things are only going to heat up more in this space as more content publishers and more browsers will join the video tag implementations and the Ogg Theora/Vorbis support.
In January this year we had the third Foundations of Open Media software workshop for developers. The focus this year was on legal issues around codecs, Xiph and Web video (HTML5 video and video servers), authoring/editing software, and accessibility. Check out the complete set of areas of concern and community goals that we decided upon.
As every year, at the beginning of the workshop every participant provided a 5 min introduction about their field of speciality and the current challenges. These are video recorded and shared with the community.
The videos and accompanying slides have been available for about 2 months now, but I haven’t gotten around to blogging about it - apologies everyone! So, here are your star videos in reverse alphabetic order published using open source video software only:
I found it really difficult to summarize all the things that I find important about video technology in a modern distributed online world in a 10 min speech. Therefore, I’d like to extend on some of the key points that I was trying to make in this blog post.
Video provides presence
One of the biggest problems we have with the online world is that it mostly still evolves around text. To exchange information with others, to publish, to chat (email, irc or twitter) or do our work, we mostly still rely on the written word as a communication means. However, we all know how restrictive this is - everyone who has ever seen a flame war develop on a mailing list, a friendship break over a badly formulated email, a host of negative comments posted on a mis-formulated blog post, or a twitter storm explode over a misunderstanding knows that text is very hard to get right. Lacking any sort of personal expression supporting the expressed words (other than the occasional emoticon), sentences can be read or interpreted in the wrong way.
A phone call (or skype call) is better than text: how often have you exchanged 10 or even 20 emails with a friend to e.g. arrange to meet for a beer, when a simple phone call would have solved it within seconds. But even a phone call provides a reduced set of communication channels in comparison to a personal meeting: gesture, posture, mime and motion are there to enrich communication channels and help us understand the other better. Just think about the cognitive challenges in a phone conference in comparison to the ease of speaking to people when you see them.
With communication that uses video, we have a much higher communication “bandwidth” between people, i.e. a lot less has to be actually said in words so we can understand each other, because gesture, posture, mime and motion speak for us, too. While we cannot touch each other in a video communication, e.g. for shaking hands or kissing cheeks, video provides for all these other channels of communication providing a much higher perceived feeling of “presence” to the remote person or people. When my son speaks over skype with my family in Germany, and we cannot turn on the web cam because the bandwidth and latency are too poor, he loses interest very quickly in speaking to these “soul-less” voices.
The availability of bandwidth will make it possible for humans to communicate with each other at a more natural level, feeling more engaged and involved. This has implications not just on immediate communications, such as person-to-person calls or video conferences, but on any application that requires the interaction of people.
Video requirements are the block to create new applications
Bandwidth requirements for most online applications are pretty low. Consider for example a remote surgery where a surgical expert on one end operates on a patient at a remote location with surgical staff and operating equipment. The actual data that needs to be exchanged between the surgeon and the operating machines is fairly low - they are mostly command-control data that has to be delivered at high accuracy and low delay, but does not require high bandwidth. What turns such a remote surgery scenario into a challenge with existing networks are the requirements for multiple video channels - the surgeon needs to be visible to the staff and probably to the patient - in turn, the surgeon needs to see the staff, needs to see the patient from multiple angles to gain the full picture, needs to see the supporting documents such as X-rays, schedules, blood analysis etc, and of course he needs to see the video coming from the operating equipment possibly from within the patient that gives him feedback on the actual operation.
As you can see, it is video that creates the need for high bandwidth.
This is not restricted to medical applications. Almost all new remote applications that we create end up having a huge visual requirement with multiple video streams. This is natural, since almost all remote applications involve more than one person and each person has the capability to look into different directions. Thus, the presence of each person has to be replicated and the representation of the environment has to be replicated.
Even in a simple scenario such as a video conference, a single camera and microphone are very restrictive and do not provide the ability to every participant to interact with any of the other people present, but restrict them to the person/group that the camera is currently focused on. Back channels such as affirmative side chats or mimic exchanges of opinion are lost. Multiple video channels can make up for this.
In my experience from the many projects I have been somewhat involved with over the years that tried to develop new remote applications - teleteaching at Mannheim University or the CeNTIE project at CSIRO - video is the bandwidth-needy channel, but video is not the main purpose of the application. Rather, the needs for information for the involved people are what drives the setup of the data and communication channels for a particular application.
Immediately, applications in the following areas come to mind that will be enabled through broadband:
education: remote lectures, remote seminars, remote tutoring, remote access to research text/data
business: remote workplace, remote person-to-person collaboration with data sharing and visualisation, remote water-cooler conversations, remote team presence
entertainment: remote theatre/concert/opera visit, home cinema, high-quality video-on-demand
But ultimately, there is impact into all aspects of our lives: consider e.g. the new possibilities for citizen involvement in politics with remote video technology, or collaborative remote video editing in video production, or in sports for data collection. Simply ask yourself “what would I do differently if I had unlimited bandwidth?” and I’m sure you will come up with at least another 2 or 3 new applications in your field of expertise that have not been mentioned before.
Technical challenges
Video (with audio) is an inherently volatile data stream that is highly sensitive to specific kinds of networking issues.
End-to-end delays such as are typical with satellite-based connections destroy the feeling of presence and create at best awkward communications, at worst destructive feedback-loops in live operations. Unfortunately, there is a natural limit to the speed in which data can flow between two points. Given that the largest distance between two points on earth is approx 20,000 km and the speed of light is approx 300,000 km/s, a roundtrip must take at least 133ms. Considering that humans can detect a delay as small as 10ms in a remote communication and are really put off by a delay of 100ms, this is a technical challenge that we will find hard to overcome. It shows, however, that it is a technical requirement to minimize end-to-end dealys as much as possible.
Packet jitter is another challenge that video deals with badly. In networks, packets cannot easily be guaranteed to arrive at a certain required rate. For example, video needs to play back at a fixed picture rate (typically 25 frames per second) for humans to be able to view it as smooth motion. Whether video is transferred live or from a file, video packets are required to arrive at a certain rate such that the pictures can be decoded and displayed at the expected rate. The variance in delay of packets arriving because of network congestion is called packet jitter. If packet jitter is high, the video will either have to stop and buffer packets until enough video frames have arrived for it to display again, or it will have to drop packets and therefore video frames to keep in sync with a live stream. Typically the biggest problem of dropping packets is the drop-out of audio - while we can tolerate some drop-outs in video, audio drop-outs are unacceptable to maintain a conversation.
In most of the application scenarios, there is a varying need for video quality.
For example, a head shot of a person that is required for communication doesn’t need high-quality video - it is sufficient if the person can be seen and the communication can be held. The audio resolution can be telephone quality (i.e. 8kHz audio sampling rate) and the video can be highly compressed and at a smallish resolution (e.g. 320x240 px) giving standard skype quality video which requires about 400Kbps in bandwidth.
At the other end of the scale are e.g. medical and large-screen applications where a high sound quality is required e.g. to hear heart beats properly (i.e. 48-96kHz audio sampling rate) and the video can’t be compressed (much) so as not to introduce artifacts, which gives at a high HDTV resolution of e.g. 1920x1080px bandwidth requirements of 30Mbps compressed - uncompressed would be about triple that.
So, depending on the tolerance of the application to picture size, compression artifacts, and the number of parallel video streams required, bandwidth requirements for video can be relatively low or really high.
Further technical issues around video are that online video can be handled differently to analog video. The video can have all sorts of metadata associated with it - it can have hyperlinks to other content - it can be accompanied by advertising in more flexible ways - and it can be automatically personalised towards the needs of the individual viewers, just to name a few rich functions of online video. It is here where a lot of new ideas for monetisation will evolve.
Non-technical challenges
Apart from technical challenges, the use of video also creates issues in other dimensions.
People are worried about their behaviour as it is always potentially recorded and thus may not perform their duties with the same focus and concentration as is necessary.
People are worried about video connections always being potentially enabled and thus having potentially a remote listener/viewer that is unwanted.
On top of such privacy issues come issues in data security as increasingly data is distributed remotely.
We should also not forget that there are people that have varying requirements for their communication. A large challenge for such new applications will be to make them accessible. For example the automated creation of captions for remote video communication may well turn out to be a major challenge, but also an opportunity for later archiving and search.
When looking at the expected move of professional video content from TV to online, there are more issues about copyrighted content and usage rights - mostly this has to do with legacy content where online use was not considered in licensing agreements. This is a large inhibitor e.g. for Australia in creating a Hulu-like service.
In fact, monetisation is a huge issue, since video is not cheap: there is a cost in the development of applications, there is a cost in bandwidth, in storage, and a cost in content production that has to be covered somewhere. Simply expecting the user to pay for being online and then to pay again for each separate application, potentially subscribing to a multitude of services, may not be the best way to cope with the cost. Advertising will certainly play a big role in the monetisation mix and new forms of advertising will emerge, such as personalised permission-based advertising based on the information available about a person e.g. through their Google searches.
In this context, the measurement of the use of video in bandwidth, storage and as part of an application will be a big enabler towards figuring out how to pay for all the involved expenditure and what new monetisation models to come up with.
Further in the context of cost and monetisation it should be added that the use of open source software, in particular open source video technology such as open codecs can help bring down cost while at the same time create more interoperability. For example, if Skype used an open codec and open protocols rather than their proprietary technology, other applications could be built using the skype infrastructure and user base.
Approach to developing good new applications
These are just the challenges for video streams themselves. However, in new applications, video streams will just be a tool for creating an integral application, ultimately driven by the processes and data needs of the application. The creation of all the other parts of the application - the machinery, control panels, the data pools, the processes, the human interface, security and privacy measures etc - are what make up the product challenge. A product ultimately has to function in a way that makes it a usable tool in achieving a certain outcome. Unless the use of the product becomes natural and the distance disappears from the minds of the people involved, a remote application does not succeed.
The CeNTIE project, the approach towards the development of new remote applications was to assume no limits on available bandwidth. Then a challenge would be identified in an application area, e.g. in the medical space, and a prototype would be built with lots of input from the domain experts. Then the prototype would actually be deployed into a real working situation and tested. The feedback from the domain experts would be used to improve the application with further technology and improved processes. Ultimately, a usable setup would emerge, which was then ready to be turned into a product for commercialisation.
We have the capabilities here in Australia to develop world-class new applications on high-bandwidth networks. We need to support this further with bandwidth - hopefully the NBN will achieve this. But we also need to support this further with commercialisation support - unfortunately most of the applications that I saw being developed at the CSIRO never made it past the successful prototype. But this is fodder for another blog post at a different time.
Finally, I’d like to point out that we also have a large challenge in overcoming tradition. Most of us would be challenged to trust a doctor and his equipment for doing a surgical operation on our body from a remote location. There are issues of trust and culture involved that may take us a while to deal with and accept.
UPDATE (11/6/09): It seems that CISCO’s latest report, which predicts global IP traffic to increase 5-fold over the next 3 years, agrees with the analysis that most of this increase will be caused by video.
After posting only a month ago about the new Thusnelda release, there continues to be good news from the open codec front.
Monty posted last week about further improvements and this time there are actual statistics thanks to Greg Maxwell. Looking at the PSNR (peak signal-to-noise ratio) measure, the further improved Thusdnelda outstrips even the X.264 implementation of H.264.
Don’t get me wrong: PSNR is only one measure, it is an objective measure and the statistics were only calculated on one particular piece. Further analysis are needed, though these are very encouraging statistics.
This is important not just because it shows that open codecs can be as good in quality as proprietary ones. What is more important though is that Ogg Theora is royalty free and implementable in both proprietary and free software browsers.
H.264’s licensing terms, however, will really kick in in 2010, so that may well encourage more people to actually use Ogg Theora/Vorbis (or another open codec like Ogg Dirac/Vorbis) with the new HTML5 video element.
Those who know me well know that a few years ago (in fact, almost 10 years now) we developed the Annodex set of technologies at the CSIRO in a project called “Continuous Media Web”.
The idea was to make time-continuous data (read: audio and video) a integral part of the Web. It would be possible to search for media through standard search engines. It would be possible to link into and out of media as we link into and out of Web pages. It would be possible to mash up video from different Web servers into a single media stream just like we are able to mash up images, text and other Web resources from different Web servers.
As you are all aware, we have made huge steps towards this vision in the last 10 years. We now have what is called “universal search” - search engines like Google and Yahoo don’t return only links to HTML pages any longer, but return links to videos and images just as well.
But it doesn’t go far enough yet - even now we still cannot link into a long-form video to the right fragment that has the exact context of what we have been searching for.
In the Annodex project we implemented a working version of such a deep universal search engine in the year 2003 on top of the Panoptic search engine (a enterprise search engine developed by CSIRO, later spun out and now sold as Funnelback).
The basis for our implementation was the combination of specifications that we developed around Ogg:
An extension on Ogg that allows to create valid Ogg streams from subparts of Ogg streams - this is now part of Ogg as Skeleton.
A means of annotating Ogg streams with time-aligned text that could be interleaved with the Ogg media stream to produce streams that knew more about themselves - the format was called CMML for Continuous Media Markup Language.
And an extension to the URI addressing of Ogg streams using temporal URIs.
I am very proud that in the last 2 years, the development of a generic media fragment URI addressing approach has been taken up by the W3C and Conrad Parker and I are invited experts on the Working Group.
I am even more proud that the Working Group has just published a First Public Working Draft of a document called “Use cases and requirements for Media Fragments”. It contains a large collection of examples for situations in which users will want to make use of media fragments. It defines that the key dimensions of fragmentation that need to be specified are:
To explain some of the approaches that are being proposed in more detail, here are some examples of media fragment URIs that are proposed through this WD:
http://www.example.com/example.ogv#t=10s,20s - addresses the fragment of example.ogv that lies between the 10s and the 20s offset
http://www.example.com/example.ogv#track='audio' - addresses the track called “audio” in the example.ogv file
http://www.example.com/example.ogv#track='audio'&t=10s,20s - addresses the track called “audio” on the subpart between the 10s and 20s offset in the example.ogv file
http://www.example.com/example.ogv#xywh=pixel:160,120,320,240 - addresses the example.ogv file but with a video track cut to a region of the size 320x240px positioned at 160x120px offset
http://www.example.com/example.ogv#id='chapter-1' - addresses the named fragment called “chapter-1” which is specified through some mechanism, e.g. Kate or CMML in Ogg
Note that the latter example works only if the encapsulation format provides a means of specifying a name for a fragment. Such a means is e.g. available in QuickTime through chapter tracks, or in Flash through cuepoints.
We know from our experience with Ogg that temporal fragmentation can be realized. For track addressing it is possible to use the recently developed ROE specification. The id tags used there could be included into Skeleton and then be used to address tracks by name. What concerns spatial fragmentation on Ogg Theora - I don’t think it can be achieved for an arbitrary rectangular selection without transcoding.
The next tasks of the Working Group are in creating implementations for these specifications on diverse formats and thus finding out which processes work the best.
When Google bought YouTube in October 2006, I wrote a blog entry about how Google video is a hosting site and that with the purchase of YouTube, Google has the opportunity to turn the Google brand back to video search.
Well, today, that prediction has come true and Google video has stopped hosting videos for users. So, things are now clear: YouTube is a video publishing site and Google video is a search engine.
Hold on: not so fast.
According to ComScore’s most U.S. search engine Rankings for August 2008, YouTube is the second largest search engine on the Web, ahead of Yahoo. At Vquence, we explain to customers that many people now use YouTube search as their entry point into the Web. Video is their Web. And when it comes to video, it’s all about YouTube.
Because people search for videos on YouTube, most videos that get published will have a copy on YouTube. Thus, YouTube is the dominant place to find video - not Google video. Also, YouTube is turning more and more into a search engine like Google: just this week they published “featured search results”, making a YouTube search result page look almost identical to a Google search result page: there is some featured content on top of the actual search results and there are some paid-for ads on the right.
Since it has taken Google such a long time to move Google video from hosting service to search service, I wonder if it’s not too late for Google video already. It feels now just like an add-on to YouTube - a place you go when all other searches fail.
Yahoo video search was once the best video search around. Then came Truveo and blinkx and a whole bunch more. Now, nobody writes about them any more - everybody just goes to YouTube itself or to Google Universal Search to go and find a video.
It would be nice if Google video search stayed around - if only as a discovery tool for when Web video goes directly onto our TVs. But I doubt, Google will find a good way to monetize it. YouTube’s search will be monetized quicker and more effectively.
On Thursday, Ralph Giles announced the alpha release of Thusnelda, the next generation implementation of the Theora encoder.
The primary change in comparison to the first generation Theora implementation is a completely rewritten encoder with vastly improved quality vs. bitrate in the default vbr/constant-quality mode, and better tracking of the target bitrate in cbr mode.
In 2007 there was a huge (and mostly uninformed) discussion about the lack of quality of Theora on slashdot and Monty wrote a reply clarifying some of the misinformation and explaining the shortcomings that the Xiph team wants to work on to improve the codec. A lot of these issues are now being attacked through the community and through the financial support of the Mozilla grant.
Theora is now much closer to H.264, if not even having overtaken it in some dimensions. Congratulations to the Theora team, in particular Tim Terriberry, Monty, and Ralph Giles. Once this Theora generation is released, it will be a competitive modern video codec.
Quick Press: the awesome guys from FFmpeg have made an official release this week. The days of pain for compiling and packaging FFmpeg have come to an end. FFmpeg is being used in many Web video sites to provide backend transcoding - FAIK that includes YouTube. I use FFmpeg for all my transcoding needs and it has never let me down. Open media software to the win!
It is great to see such a huge need for this. At the same time I am also worried about the amount of incompatible implementations of this feature. It will inhibit search engines from realising which text relates to and describes a particular video. It will also inhibit accessibility technology such as screen readers or braille devices from realising there is text that would be necessary to be rendered.
A standard means of associating srt (or other format) subtitle files with the video tag is really necessary. So, where are we at with this?
Recently, Greg Millam from Google posted a proposal to WHATWG, that shares a lot of elements with the proposal that has been previously discussed between Mozilla, Xiph, and Opera, the current state of which is summarised in the Mozilla wiki. No implementation into a Browser has been made yet, but initial implementations in javascript exist. I think that we will ultimately come out with a harmonised solution between the browser vendors. It just needs implementation work and continuous improvement.
At the same time, in-band captions that come multiplexed within the Ogg file are also being progressed. At Xiph we are now focusing on using Ogg Kate for these purposes - it really don’t make much sense to invent another codec when Ogg Kate is already so close to solving most problems. So, between the developer of Ogg Kate and myself, we are preparing a Google Summer of Code project that should see a implementation for Firefox 3.1 that is capable of extracting the text from an Ogg file that has a Kate track and displaying that track as though it was a srt file. If you are interested, shoot me an email!
UPDATE: Firefox 3.1 is apparently now called Firefox 3.5 - sorry guys. :-)
ANOTHER UPDATE: My post seemed to imply that Firefox 3.5 will have Ogg Kate support. This is not the case. There is a patch for Firefox and liboggplay to provide Ogg Kate support into Firefox and this patch will be the basis of the Summer of Code project. The student will then work mostly on implementing a comprehensive javascript library to display Ogg Kate encoded time-aligned text (read: captions, Karaoke etc) in the Web browser. This is a proof-of-concept and a first step towards standardising the handling of time-aligned text in Web browsers that suppor the HTML5 video tag.
Michael Dale from Metavid has posted an article on why we are about to hit the tipping point for professional video producers to move to open media codecs. His statement is that it’s not just because the H.264 licensing grace period is about to end, but has a lot to do with the support that open media codecs are increasingly seeing on the Web, where the next big professional video market will happen. I totally agree.
The increasing amount of open tools on the Web for open codecs was all stimulated by the HTML5
Native editing of Ogg Theora/Vorbis video is still a challenge, but any professional video producer will not want to move away from their favorite tool for editing video anyway, so it is a matter of having an export function included into these professional editors. While such export functions will take some time to emerge in these proprietary editors, the use of ffmpeg2theora and similar transcoding tools will be perfectly sufficient to fulfill these needs.
If you want to see why open source codecs and open video technology make such a difference, just go and check out Metavid, the best software around for wiki-style editing of time-aligned annotations for long-form video. I look forward to all the cool new applications that will emerge with open media software on the Web - applications that are not possible with proprietary video technology because of their lack of flexibility, interoperability, and adaptability.
I have spent a lot of time recently researching Sydney-based agencies to invite to the upcoming Launch of our Vquence VQmetrics service. This involved finding their websites, finding out about their target business (do they do online video?), finding a relevant contact, and emailing an invitation to them.
I am close to institutional confinement!
I do understand that agencies need to show off their creativity on their Website. The result of this is that most agency Websites are completely written in Flash. Fortunately I have the latest version of Flash installed, so I can load them all. But my Web browser and MacBook do not deal well with having more than about 5 tabs open with Flash content - my machine almost grunts to a halt. So, there goes the idea of opening multiple tabs at the same time while waiting for the lengthy Flashs of the sites to load…
Then, once the pages are loaded, it is always a surprise to see what the agency has come up with. At the beginning of the exercise it was a surprise. Later it became a nuisance. Now, I am utterly terrified before opening another agency Website. Will it break my browser? Will it start playing a video? Will it start playing music so loud that it blasts off my ears? Will I feel really stupid because I cannot navigate the site? Will I be able to locate the “Contact Us” section? Will they have bothered to publish an email address or do I have to fill in a stupid contact form that I know nobody will look at? Will the contact email work or just bounce?
It almost feels like the creation of the Website is a competition between the agencies as to who can create the maddest, most unusual, and most unusable Website.
Please, please! Can I just have a simple, usable site with obvious navigation, a simple and fast loading list of reference work, and a list of key people working at the agency with their email contacts?
Oh, and Mumbrella has just published a post that gives me scientific proof that this is a conspiracy against me by the agencies! No, stop that - I am not ready to be locked up yet!
I am a slacker, I know - sorry. FOMS happened almost 4 weeks ago and I have neither blogged about it nor uploaded the videos.
So, you will have to take my word for it for the moment: it was a totally awesome and effective workshop that led to a lot of work being started during LCA and having an impact far beyond FOMS.
Every year, the discussions we are having at FOMS are captured in so-called community goals. These are activities that we see as top priorities for open media software to be addressed to improve its use and uptake.
You can read up on our 2009 community goals here in detail. They fall into the following 10 sections:
Patent and legal issues around codecs
Ogg in Firefox: liboggplay
Authoring tools for open media codecs
Server Technology for open media
Time-aligned text and accessibility challenges
FFmpeg challenges
GStreamer challenges
Dirac challenges
Jack challenges
OpenMAX challenges
In this post, I’d just like to point out some cool activities that have already emerged since FOMS.
Liboggplay provides a simple API to decoding and playback of Ogg codecs and is therefore in use for baseline Ogg Theora support in Firefox 3.1. A bunch of bugs were found around it and the opportunity of having Shane Stephens, its original developer, together with Viktor Gal, its new maintainer, in the same room made for a whole lot of bug fixes. The $100K Mozilla grant towards the work of Xiph developers that was announced at FOMS will further help to mature this and other Xiph software. Conrad Parker, Viktor Gal, and Timothy Terriberry, the Xiph developers that will cut code under this grant, were incidentally all present at FOMS.
The discussion about the need for authoring software support for open media codecs is always a difficult one. We all know that it is important to have usable and graphically attractive authoring tools in order to get adoption. However, looking at reality, it is really difficult to design and implement a GUI authoring tool such as a video editor to a competitive quality. In other areas, it has also taken quite some time to gain good authoring software such as e.g. the Gimp or Inkscape. Plus there is the additional need to make it cross-platform. With video, often the underlying editing functionality is missing from media frameworks. Ed Hervey explained how he extended gstreamer with the required subroutines and included them into the gstreamer python plugin, so now he will be able to focus on user interface work in PiTiVi rather than the underlying video editing functionality.
The authoring discussion smoothly led over to the server technology discussion. Robin Garvin explained how he implemented a server-side video editor through EDLs. Michael Dale showed us the latest version of his video editor in the Mediawiki Metavid plugin. And Jan Gerber showed us the Firefogg Firefox plugin for transcoding to Ogg. Web-based tools are certainly the future of video authoring and will make a huge difference in favor of Ogg.
Then there was the accessibility discussions. During FOMS I was in the process of writing up my final report on the Mozilla video accessibility project and it was really important to get input from the FOMS community - in particular from Charles McCathyNevile from Opera, Michael Dale from Metavid/Wikipedia/Archive.org and Jan Gerber. In the end we basically agreed that a lot of work still needs to be done and that a standard way of providing srt support into HTML5 through Ogg, but also out-of-band will be a great step forward, though by far not the final one.
The remaining topics were focused discussions on how to improve support, uptake or functionality of specific tools. Peter Ross took FOMS concerns about ffmpeg to the ffmpeg community and it seems there will be some changes, in particular an upcoming ffmpeg release. Ed Hervey took home a request for new API functions for gstreamer. Anuradha Suraparaju talked with Jan Gerber about support of Dirac in firefogg and with Viktor Gal about support in liboggplay. Further, the idea of libfisheye was born to have a similar abstraction library for Ogg video codecs as libfishsound is for Ogg audio codecs.
As can be seen, there are already some awesome outcomes from FOMS 2009. We are looking forward to a FOMS 2010 in Wellington, New Zealand!
In support of spreadfirefox.com, OZprod (no, they are not Australian, but French) this week released a video on Dailymotion that shows the cool stuff you can do with a video tag and Theora support in Firefox. It’s super-cool!
You will have to install Firefox 3.1 to try it our for yourself here.
Today, Wikimedia and Mozilla announced a grant provided by the Mozilla Corporation towards maturing the support of Ogg in the Firefox Web browser. I’m happy to have helped in making the proposal become concrete and now we have the following three Xiph developers working on it:
Viktor Gal - the maintainer of liboggplay
Conrad Parker - the key developer of multiple Ogg support libraries, in particular liboggz
Tim Terriberry - the key developer of Ogg Theora
Viktor will work towards stabilising the current Ogg Theora support in Firefox, Conrad will work towards Ogg network seeking, language selection and improved library support, and Tim will include the new Thusnelda Theora encoder improvements into Theora mainstream.
Looking forward to awesome Firefox video technology!
During the LCA 2009 Multimedia Miniconf, I gave a talk on video accessibility. Videos have been recorded, but haven’t been published yet. But here are the talk slides:
I basically gave a very brief summary of my analysis of the state of video accessibility online and what should be done. More information can be found on the Mozilla wiki.
The recommendation is to support the most basic and possibly the most widely online used of all subtitle/captioning formats first: srt. This will help us explore how to relate to out-of-band subtitles for a HTML5 video tag - a proposal of which has been made to the WHATWG and is presented in the slides. It will also help us create Ogg files with embedded subtitles - a means of encapsulation has been proposed in the Xiph wiki.
Once we have experience with these, we should move to a richer format that will also allow the creation of other time-aligned text formats, such as ticker text, annotations, karaoke, or lyrics.
Further, there is non-text accessibility data for videos, e.g. sign language recordings or audio annotations. These can also be multiplexed into Ogg through creating secondary video and audio tracks.
Overall, we aim to handle all such accessibility data in a standard way in the Web browser to achieve a uniform experience with text for video and a uniform approach to automating the handling of text for video. The aim is:
to have a default styling of time-aligned text categories,
to allow styling override of time-aligned through CSS,
to allow the author of a Web page with video to serve a multitude of time-aligned text categories and turn on ones of his/her choice,
to automatically use the default language and accessibility settings of a Web browser to request appropriate time-aligned text tracks,
to allow the consumer of a Web page with video to manually select time-aligned text tracks of his/her choice, and
to do all of this in the same way for out-of-band and in-line time-aligned text.
At the moment, none of this is properly implemented. But we are working on a liboggtext library and are furher discussing how to include out-of-band text with the video in the Webpage - e.g. should it go into the Webpage DOM or in a separate browsing context.
I spent the last few days doing some nice research for Vquence, where I was able to watch lots of videos on YouTube. Fun job this is! :-) The full article is on the Vquence metrics blog.
One of the key things that I’ve put together is a list of top 10 commercials for 2008:
Enjoy! And let me know in the comments if you know of any other video ad released in 2008 in the same ballpark number of views that is an actual tv-style commercial.
NOTE: I just had to change the list, because the SoBe Lifewater Super Bowl ad of 2008 actually came out ahead. It’s difficult to discover an ad that has neither ad nor commercial in its annotations!
As requested by the organisers, I just uploaded the slides to Slideshare, which incidentally can now also synchronise audio recordings of your talk to your slides. Here are my slides - even if they don’t actually give you much without the demo:
I had lots of fun giving the talks. The “YouTube” one talks about the Fedora Commons document repository and how we turned it into a video transcoding, keyframing, publication and sharing system. The one on Metavidwiki shows off the Annodex-technology using video wiki that is in use by Wikipedia. Most certainly, I also mentioned that open source CMS systems now have video extensions. However, they are not video-centric sites in general.
Of all the open source Web video technology, I find Fedora Commons and MetaVidWiki the most exciting ones. The former is exciting for its ability to archive and publish video and their metadata in a way that integrates with document management. The latter is even more exciting for using Ogg and the open Annodex technologies to create a completely open source system using open codecs, and for being the world’s second video wiki (just after CMMLwiki), but the first one to achieve wide uptake.
During the last week, I made a proposal to the HTML5 working group about how to support out-of-band time-aligned text in HTML5. What I mean by that is basically: how to link a subtitle file to a video tag in HTML5. This would mirror the way in which in desktop-players you can load separate subtitle files by hand to go alongside a video.
“text” elements are subelements of the “video” element and therefore clearly related to one video (even if it comes in different formats).
the “category” tag allows us to specify what text category we are dealing with and allows the web browser to determine how to display it. The idea is that there would be default display for the different categories and css would allow to override these.
the “lang” tag allows the specification of alternative resources based on language, which allows the browser to select one by default based on browser preferences, and also to turn those tracks on by default that a particular user requires (e.g. because they are blind and have preset the browser accordingly).
the “type” tag allows specification of what actual time-aligned text format is being used in this instance; again, it will allow the browser to determine whether it is able to decode the file and thus make it available through an interface or not.
the “src” attribute obviously points to the time-aligned text resource. This could be a file, a script that extracts data from a database, or even a web service that dynamically creates the data based on some input.
This proposal provides for a lot of flexibility and is somewhat independent of the media file format, while still enabling the Web browser to deal with the text (as long as it can decode it). Also note that this is not meant as the only way in which time-aligned text would be delivered to the Web browser - we are continuing to investigate how to embed text inside Ogg as a more persistent means of keeping your text with your media.
Of course you are now aching to see this in action - and this is where the awesomeness starts. There are already three implementations.
First, Jan Gerber independently thought out a way to provide support for srt files that would be conformant with the existing HTML5 tags. His solution is at http://v2v.cc/~j/jquery.srt/. He is using javascript to load and parse the srt file and map it into HTML and thus onto the screen. Jan’s syntax looks like this:
Then, Michael Dale decided to use my suggested HTML5 syntax and add it to mv_embed. The example can be seen here - it’s the bottom of the two videos. You will need to click on the “CC” button on the player and click on “select transcripts” to see the different subtitles in English and Spanish. If you click onto a text element, the video will play from that offset. Michael’s syntax looks like this:
Then, after a little conversation with the W3C Timed Text working group, Philippe Le Hegaret extended the current DFXP test suite to demonstrate use of the proposed syntax with DFXP and Ogg video inside the browser. To see the result, you’ll need Firefox 3.1. If you select the “HTML5 DFXP player prototype” as test player, you can click on the tests on the left and it will load the DFXP content. Philippe actually adapted Jan’s javascript file for this. And his syntax looks like this:
The cool thing about these implementations is that they all work by mapping the time-aligned text to HTML - and for DFXP the styling attributes are mapped to CSS. In this way, the data can be made part of the browser window and displayed through traditional means.
For time-aligned text that is multiplexed into a media file, we just have to do the same and we will be able to achieve the same functionality. Video accessibility in HTML5 - we’re getting there!
As part of my accessibility work for Mozilla and Xiph, it is necessary to define how time-aligned text such as subtitles, captions, or annotations, are encapsulated into Ogg. In the fansubber community this is called “hard subtitles” as opposed to “soft subtitles” which are subtitles that stay in a text file and are loaded separately to the video file into a media player and synchronised with the video by the media player. (as per comment below, all text annotations are “soft” - or also “closed”.)
I can hear you ask: so how do I do subtitles/captions with Ogg now? Well, it would have been possible to simply choose one subtitling format and map that into Ogg, then ask everyone to just use that one format and be done. But which one to choose? And why prefer a simpler one over a more complex one? And why just do subtitles and not any other time-aligned text?
So, instead, I analysed what types of time-aligned text “codecs” I have come across. Each one would have a multitude of text formats to capture the text data, because it is easy to invent a new format and standardisation hasn’t really happened in this space yet.
I have come up with the following list of typical time-aligned text codecs:
CC: closed captions (for the deaf)
SUB: subtitles
TAD: textual audio descriptions (for the blind - to be transferred to braille or TTS)
KTV: karaoke
TIK: ticker text
AR: active regions
NB: metadata & semantic annotations
TRX: transcripts / scripts
LRC: lyrics
LIN: linguistic markup
CUE: cue points, DVD style chapter markers and similar navigational landmarks
Let me know if you can think of any other classes of video/audio-related time-aligned text.
All of these texts can be represented in text files with some kind of time marker, and possibly some header information to set up the interpretation environment. So, the simplest way of creating a representation of these inside Ogg was to define a generic mapping for time-aligned text into Ogg.
The Xiph wiki holds the current draft specification for mapping text codecs into Ogg. For anyone wanting to map a text codec into Ogg, this should provide the framework. The idea is to separate the text codec’s data into header data and into timed text segments (which can have all sorts of styling and other information with it). Then, the mapping is simple. An example for srt is described on the wiki page.
The specification is still in draft status, because we’re still expecting feedback. In fact, what we now need is people trying an implementation and providing fixes to the specification.
To map your text codec of choice into Ogg, you will probably requrie further mapping specifications. Dependent on how complex your text codec of choice is, these additional mapping specifications may be rather simple or quite complicated. In the case of srt, it should be trivial. Considering the massive amount of srt already freely available online, the srt mapping may well have a really large impact. Enough hits. Let me know if you’re coding up something!
My next duty is to look for a representation that is generic enough to provide representations for any of the above listed text codecs. This representation is what will need to be available to a Web Browser when working with a Web video that has related text. Current contenders are OggKate and W3C TimedText, but I am not sure if either are too restrictive. I am indeed looking for the next generation of captioning technology that will be able to provide any type of time-aligned text that relates to audio/video.
Recently, I noticed an increasing number of videos on YouTube were no longer available - even if they had just been shared through a blog post by friends or even if they were the main video on a producer’s YouTube page, such as QuantumOfSolace.
I was suspicious for a while that there was something wrong with my browser, but when my colleague was able to play the video from the same network and I wasn’t, something had to be done.
I am running Firefox 3.0.4 on OS X 10.5.5 with the Flash 10.0 d26 plugin. First we thought it might be blocked for au.youtube.com and not for www.youtube.com, but there was no difference. Still the same “Sorry, this video is no longer available”.
Finally, an installation of the latest Flash plugin 10.0 r12 fixed the issue. So, if a large number of videos on YouTube isn’t available to you for no apparent reason, you might want to upgrade your Flash plugin.
Today, there were so many news that I can only summarise them in a short post.
The guys from Collabora have announced that they are going to support the development of PiTiVi - one of the best open source video editors around. They are even looking to hire people to help Christian Schaller, the author of PiTiVi. The plan is to have a feature-rich video editor ready by April next year that is comparable in quality to basic proprietary video editors.
The BBC Dirac team have today announced a ffmpeg2dirac software package, which is built along the same lines as the commonly used ffmpeg2theora and of course transcodes any media stream to Ogg Dirac/Vorbis. With Ogg Dirac/Vorbis playback already available in vlc and mplayer, this covers the much needed creation side of Ogg Dirac/Vorbis files. Dirac is an open source, non-patent-encumbered video codec developed by the BBC. It creates higher quality video than Theora at comparable bitrates.
The FOMS - Foundations of Open Media Software hacker workshop for open media software announced today the current list of confirmed participants for the January Workshop. It seems that this year we have a big focus on open video codecs, on browser support of media, on open Flash software, and on media frameworks. It is still possible to take part in the workshop - check out the CFP page.
Finally an important security message: Mozilla has decided to put a security measure around the HTML5 audio and video elements that will stop them from being exploited by cross-site scripting exploits. Chris Double explains the changes that are necessary to your setup to enable your published audio or video to be displayed on domains that are different to the domain on which these files are hosted.
In the media fragment working group at the W3C, we are introducing a standard means to address fragments of media resources through URIs. The idea is to define URIs such as http://example.com/video.ogv#t=24m16s-30m12s, which would only retrieve the subpart of video.ogv that is of interest to the user and thus save bandwidth. This is particularly important for mobile devices, but also for pointing out highlights in videos on the Web, bookmarking, and other use cases.
I’d like to give a brief look into the state of discussion from a technical viewpoint here.
Let’s start by considering the protocols for which such a scheme could be defined. We are currently focusing on HTTP and RTSP, since they are open protocols for media delivery. P2P protocols are also under consideration, however, most of them are proprietary. Also, p2p protocols are mostly used to transfer complete large files, so fragment addressing may not be desired. RSTP already has a mechanism to address temporal fragments of media resources through a range parameter of the play request as part of the protocol parameters. Yet, there is no URI addressing scheme for this. Our key focus however is HTTP, since most video content nowadays is transferred over HTTP, e.g. YouTube.
Another topic that needs discussion are the types of fragmentation for which we will specify addressing schemes. At the moment, we are considering temporal fragmentation, spatial fragmentation, and fragmentation by tracks. In temporal fragmentation, a request asks for a time interval that is a subpart of the media resource (e.g. audio or video). In spatial fragmentation, the request is for an image region (e.g. in an image or a video). Track fragmentation addresses the issue where, e.g. a blind person would not require to receive the actual video data for a video and thus a user agent could request only the data tracks from the resource that are really required for the user.
Another concern is the syntax of URI addressing. URI fragments (”#”) have been invented to created URIs that point at so-called “secondary” resources. Per definition, a secondary resource may be some portion or subset of the primary resource, some view on representations of the primary resource, or some other resource defined or described by those representations. It is therefore the perfect syntax for media fragment URIs.
The only issue is that URI fragments (”#”) are not expected to be transferred from the client to the server (e.g. Apache strips it off the URI if it receives it). Therefore, in the temporal URI specification of Annodex we decided to use the query (”?”) parameter instead. This is however not necessary. The W3C working group is proposing to have the user agent strip off the URI fragment specification and transform it into a protocol parameter. For HTTP, the idea is to introduce new range units for the types of fragmentation that we will define. Then, the Range and Content-Range headers can be used to request and deliver the information about the fragmentation.
The most complicated issue that we are dealing with is the issue of caching in Web proxies. Existing Web proxies will not be able to understand new range units and will therefore not cache such requests. This is unfortunate and we are trying to devise two schemes - one for existing Web proxies and one for future more intelligent Web proxies - to enable proxy caching. This discussion has many dimensions - such as e.g. the ability to uniquely map time to bytes for any codec format, the ability to recompose new fragment requests from existing combined fragment requests, or the need and abilities for partial re-encoding. Mostly we are dealing with the complexities and restrictions of different codecs and encapsulation formats. Possibly, the idea of recomposition of ranges in Web proxies is too complex to realise and caching is best done by regarding each fragment as its own cacheable resource, but this hasn’t been decided yet.
We now have experts from the squid community, from YouTube/Google, HTTP experts, Web accessibility experts, SMIL experts, me from Annodex/Xiph, and a more people with diverse media backgrounds in the team. It’s a great group and we are covering the issues from all aspects. The brief update above is given from my perspective, and only lists the key issues superficially, while the discussions that we’re having on the mailing list and in meetings are much more in-depth.
I am not quite expecting us to meet the deadline of having a first working draft before the end of this month, but certainly before Christmas.
While the open source codec “Theora” has been available since 2004 in a stable format, the open source community is very careful about giving any piece of software the “1.0” stamp of quality and libtheora has been put under scrutiny for years.
Today, libtheora 1.0 was finally released - rejoice and go ahead using it in production!
More hard-core improvements to libtheora are also in the pipeline under a version nick-named “Thusnelda”, improving mostly on quality and bit-rate.
I spent last week in France, near Cannes, at the W3C TPAC meeting. This is the one big meeting that the W3C has every year to bring together all (or most) of the technical working groups and other active groups at the W3C.
It was not my first time at a standards body meeting - I have been part of ISO/MPEG before and also of IETF, and spoken with people at IEEE and SMPTE. However, this time was different. I felt like I was with people that spoke my language. I also felt like my experience was valued and will help solving some of the future challenges for the Web. I am very excited to be an invited expert on the Media Fragments and Media Annotations working groups and be able to provide input into HTML5.
In the Media Fragments working group we are developing a URI addressing scheme that enables direct linking to media fragments, in particular temporal and spatial segments. Experience from our earlier temporal URI scheme is one of the inputs to the scheme. Currently it looks likely that we will choose a scheme that has ”#” in it and then require changes to browsers, Web proxys, and servers to enable delivery of media fragments.
In the Media Annotations working group we are deciding upon an ontology to generically describe media resources - something based on Dublin Core but more extended and more appropriate for audio and video. We are currently looking at Adobe’s XMP specification.
As for HTML5 - there was not much of a discussion at the TPAC meeting about the audio and video elements (unless I missed it by attending the other groups). However, from some of the discussions it became clear to me that they are still in very early stage of specification and much can be done to help define the general architecture of how to publish video on the Web and its metadata, help define javascript APIs and DOM models, and help define accessibility.
I actually gave a lightning talk about the next challenges of HTML5 video at TPAC (see my “video slides”) which points out the need for standard definitions of video structure and annotations together with an API to reach them. I had lots of discussions with people afterwards and also learnt a lot more about how to do accessibility for Web video. I should really write it up in an article…
Of course, I also met a lot of cool people at TPAC, amongst them Larry Masinter, Ian Hickson, and Tim Berners-Lee - past and new heros of Web standards. :-) It was totally awesome and I am very grateful to Mozilla for sending me there and enabling me to learn more about the greater picture of video accessibility and the role it plays on the Web.
Ian Hickson, the main editor of the new HTML5 specification, gave a talk about some of the cool new features in HTML5 and some of the early implementations of these features in different browsers.
It’s pretty long demo with 1:25 hrs but he types in all the code manually, so you can re-do all of the demos yourself. The script of the talk with code examples is here.
The first 5 minutes are about the new video element and really worth watching.
Also, at 1:11 hrs Ian is asked about the choice of baseline codecs, in case you want to hear him speak what he has publicly written elsewhere.
captions, subtitles and other timed text annotations for videos.
These will allow us search for specific topics directly inside the video (such as “form controls” in Ian’s video) and to hyperlink straight into these time offsets. A completely new world is coming!
Ogg has struggled for the last few years to recommend the best format to provide caption and subtitle support for Ogg Theora. The OGM fork had a firm focus on using subtitles in SRT, SSA or VobSub format. However, in Ogg we have always found these too simplistic and wanted a more comprehensive solution. The main aim was to have timed text included into the video stream in a time-aligned fashion. Writ, CMML, and now Kate all do this. And yet, we have still not defined which is the one format that we want everybody to support as the caption/subtitle format.
With Ogg Theora having been chosen by Mozilla as the baseline video codec for Firefox and the HTML5
As a first step in this direction, Mozilla have contracted me to analyse the situation and propose a way forward.
The contract goes beyond simple captions and subtitles though: it analyses all accessibility requirements for video, which includes audio annotations for the blind, sign language video tracks, and also transcripts, karaoke, and metadata tracks as more generic timed text example tracks. The analysis will thus be about how to enable a framework for creating a timed text track in Ogg and which concrete formats should be supported for each of the required functionalities.
While I can do much of the analysis myself, a decision on how to move forward can only be made with lots of community input. The whole process of this analysis will therefore be an open one with information being collected on the Mozilla Wiki, see https://wiki.mozilla.org/Accessibility/Video_Accessibility .
An open mailing list is also set up at Xiph to create a discussion forum for video accessibility: accessibility@lists.xiph.org. Join there if you’d like to provide input. I am particularly keen for people with disabilities to join because we need to get it right for them!
I am very excited about this project and feel honoured for being supported to help solve accessibility issues for Ogg and Firefox! Let’s get it right!
Over at the Vquence metrics blog, I have just posted a blog post for this week that summarises all the features a publisher and reader can use on YouTube.
I thought it would be a simple task, since I have been following all of YouTube’s blogs and have previously published videos on YouTube. As it turns out, YouTube’s features set is so massive, that there were some surprises in stock even for me. It took a week to collect all this information (admittedly not full time).
Go and check out the blog post and see if I have missed any!
Today, three of the worlds that I am really engaged in and that tend to not have much in-common with each other seemed to come to a sudden overlap.
The three worlds I am talking about are:
Social video publishing (through my company Vquence)
One Laptop Per Child (I am really keen to see more OLPC work in the Pacific)
Open media software and technology (through Xiph and Annodex work, as well as FOMS)
I was positively surprised to read in this blog message that Dailymotion and the OLPC foundation have partnered to set up a video publishing channel for videos that can be viewed on the OLPC. The channel is available at olpc.dailymotion.com. You can view it on your computer if you have the appropriate codec libraries for Windows and the Mac installed. Your Linux computer should just support it.
To understand the full impact of this message, you have to understand that the XO (the OLPC laptop) does not support the playback of Flash video by default. OLPC cannot ship the official Adobe Flash plugin on the XOs because it is legally restricted and doesn’t meet the OLPC’s standards for open software. Thus, children that receive an XO are somewhat cut off from social video sites like YouTube, Dailymotion, Blip.tv, MySpace.tv, video.google.com and others, even though there are lots of education-relevant videos published there.
The XO however ships with video technology that IS open: namely the Ogg Theora/Vorbis video codec and software. This is incidentally also the codec that the next version of Firefox will be supporting out of the box without need of installation of a further plugin.
Unfortunately, most video content nowadays available on the Internet is not available in the Ogg Theora/Vorbis format. Therefore, Dailymotion and the OLPC Foundation launching this channel that is automatically republishing all the videos uploaded to the Dailymotion OLPC group is a really big thing: It’s a major social video site republishing video in an open format to enable it to be viewed on open systems.
The IETF has just ratified RFC 5334 “Ogg Media Types”, which I have co-authored.
The new Ogg MIME types are as follows:
audio/ogg for all Ogg files that contain predominantly audio, such as Ogg Vorbis files (.ogg or .oga), Ogg Speex files (.spx) or Ogg FLAC files. The file extension recommended to be used is .oga, but .ogg will continue to be used for Ogg Vorbis I files for backwards compatibility.
video/ogg for all Ogg files that contain predominantly video, such as Ogg Theora or Ogg Dirac files. The file extension recommended to be used is .ogv. Please stop using .ogg for Ogg Theora files, since that causes havoc for any application trying to determine which application to use for opening such a file.
application/oggused to be the MIME type recommended for any Ogg encapsulated file. This is obsoleted by the new RFC. Instead, application/ogg is a generic MIME type that can be used for Ogg files containing custom content tracks. This may e.g. be a Ogg file with 5 vorbis, 2 speex, 2 theora, 5 CMML, 2 Kate, and a custom image tracks. Such files have to use the Skeleton extension to Ogg to be able to describe the content of the file. The file extension recommended to be used is .ogx.
The RFC also specifies the possibility of using codec parameters to the MIME types to specify directly within the MIME type what codecs are contained inside the files. This may for example be “video/ogg; codecs=‘dirac,speex,CMML’”.
More details on these decisions and on further considered MIME types are in the Xiph wiki.
Disclaimer: I had no influence on the funny number game that happened between the obsoleted rfc3534 and the new rfc5334. :-)
Have you ever been haunted by an old open source package that you wrote once, published, and then forgot about?
The BSD community has just reminded me of the MPEG audio analysis toolkit Maaate that I wrote at CSIRO when I first came to Australia and that was then published through the CSIRO Mathematical and Information Sciences division.
The BSD guys were going to remove it from their repositories, because since I left CSIRO more than 2 years ago, CSIRO has taken down the project pages and the code, so there were no active project pages available any longer. I’m glad they contacted me before they did so.
Since it is an open source project, I have now resurrected the old pages at Sourceforge. They are available from http://maaate.sourceforge.net/. I have re-instated the relevant weg pages and documentation and updated all the links. I discovered that we did some cool things then and that it may indeed be worth preservation for the future. I expect Sourceforge is up to the task.
Thanks very much, BSD community and welcome back, MPEG Maaate!
The Foundations of Open Media Software workshop has just extended its deadline for submission of registrations requests with travel sponsorship.
FOMS addresses hot topics - such as the new
In previous years, FOMS has stimulated heated technical discussions and amazing new developments in open media software, such as the creation of libsydneyaudio, the uptake of liboggplay, the creation of Xiph ROE, or the creation of the new Ogg CELT codec.
Video proceedings of last years’ workshops are here. There are also community goals that were set in 2008 and 2007 and provide ongoing challenges.
You should definitely attend, if you are an open media software hacker. This is a chance to get to know others in the community personally and clear up those long-standing issues that need a face-to-face to get solved. Also, it’s a great social event not to be missed. As a bonus, you can spend the week after FOMS at LCA, the world-famous Australian Linux hackers conference, and deepen your relationships in the community. Come and join in the fun in January 2009, Summer in Hobart, Tasmania.
liboggplay is a library that vastly simplifies the decoding and playback of Ogg encapsulated audio-visual content for programmers. It abstracts away from the complexity of libogg’s encapsulation pages, codec packets, and encoded data, giving the programmer the freedom to work with audio-visual streams, video frames, and audio samples. It does everything apart from the actual display of audio and video and has thus been selected as the thinnest library to provide support for Ogg Theora/Vorbis in Firefox’s new HTML5 .
Shane Stephens, now with Google, implemented most of liboggplay while working at CSIRO on the Annodex project. Chris Double picked up liboggplay for Mozilla/Firefox, where it got committed to trunk only this week. Many others have and continue to provide patches. And finally, yesterday, I made an actual first tarball release of liboggplay.
There is only one little hick-up: liboggplay doesn’t actually have a maintainer. So, we are now looking to find somebody who is highly enthusiastic about open media codecs, has experience in C programming, can compile and test liboggplay on all major operating systems (probably set it up on a build farm) and has enough time to react swiftly to the need of bug fixes. We don’t want people’s Firefoxes to choke on Ogg content, but rather amaze them about how easy to handle and nicely integrated Ogg works on the Web.
One of the big next challenges for liboggplay is the implementation of support for Ogg Dirac - the BBC’s wavelet-based video codec. Mozilla, would be very keen to get Dirac support into liboggplay and thus diversify the open codecs supported in Firefox.
If you want to become the new maintainer for liboggplay, or want to implement Ogg Dirac support into liboggplay, or do both, get in touch with me and we’ll get you set up.
Mozilla have just published a brief statement that they have taken legal advice before they chose to support Ogg Theora/Vorbis natively in the Firefox codebase. Seems like the risk of submarine patents was not large enough to hold back.
Apple and Microsoft should follow this example, undertake their own patent risk assessment (rather than hiding behind Nokia), and make an informed decision on whether or not to support Ogg Theora in their browsers.
The old excuse that there hasn’t been a large player in the market yet that supports the codec is now not true any longer. The ball is in your court to show us better arguments for not supporting the codec!
Julian Frumar used to be our Visual Communications Manager at Vquence until last year, when he left for new grounds and created a startup with two friends in Palo Alto called Omnisio. They received Y-combinator funding and worked hard on creating this video-centric Web2.0 startup in a very short amount of time.
Today, Techcrunch announced that Omnisio were acquired by Google to extend the YouTube technology base for an estimated US$15M. Congratulations, Julian!
PS: Rodney Gedda wrote a good review on this over at Techworld.
Chris Blizzard and Chris Double of Mozilla have just announced that native Ogg Theora and Vorbis support is now available in the trunk of Firefox’s codebase. Compiles of that codebase have the support enabled by default, which means that very soon now any Firefox that gets installed on any platform will come with built-in Ogg Theora/Vorbis support out of the box.
This is exciting in more than one way.
First of all: it is a browser implementation of the new HTML5 video tag currently in the process of standardisation. Opera is the only other browser that has support for the video tag also using Ogg Theora as the baseline codec, but Opera’s support is in an experimental branch, while Firefox will be the first to have native support.
The choice to include Ogg Theora natively is a huge step forward on Mozilla’s behalf considering the submarinepatentdebate that has been raging around this codec ever since it was removed from the HTML5 specification as baseline codec. So, maybe the Mozilla lawyers believe the risk of this threat is negligible and if they have, other browser vendors may follow.
This is a big day for open media technology and a big day for the future of video on the Web.
It is important because the availability of free and unencumbered video and audio codecs that are natively supported on the Web will make a huge difference in progressing the capabilities of video on the Web. As an example, look at the efforts of Annodex, where we are creating video webs through a video format with embedded hyperlinks and annotations. To make this feasible, you need a standard and open format for the time-aligned hyperlinks and annotations, which will only work with a flexible open video format. This is just an example: open captioning and karaoke formats, open overlay formats and many other extensions to video formats will now be feasible. The golden age of online video is starting.
Michael Dale’s metavid project is giving us a taste of this future. Video can be searched on time-aligned annotations and only the relevant video segment will be retrieved. Video segments can be addressed by temporal hyperlinks and recombined easily into new mash-ups simply through the creation of a list of temporal hyperlinks. How powerful this will be when we do it across sites! This takes video into a completely new dimension.
Now, let’s step back again from the future to the current exciting news. I am particularly proud of the input that Annodex people have made to this development - code from people like Conrad Parker, Andre Pang, Zen Kavanagh, Shane Stephens, and many others.
Chris Double from Mozilla has been implementing the Firefox Ogg Theora support for more than a year and is using Shane Stephens’ liboggplay library, which was originally developed by CSIRO and is in the code repository of the Annodex Association. liboggplay requires libraries from Xiph.org (libogg, libvorbis, libtheora) and from Annodex (liboggz and libfishsound) to work. All of this has to work across operating system platforms.
It is an enormous achievement and I congratulate the open media technology community on this big success.
The W3C has just released a set of proposed charters for a new W3C Video in the Web activity with a request for feedback.
The following working groups are proposed:
Timed Text Working Group
Media Fragments Working Group
Media Annotations Working Group
Two further ones under investigation are:
Codecs and containers
Best practices for video and audio content
It is worth checking out the site and the three different working groups they are planning to create. Sure - the codec discussion is a big one. But it’s not as big as some of the other activities as to new functionality for video on the Web.
On Tuesday 24th June I attended the “Commercialising Video” conference held in beautiful Jones Bay Wharf in Sydney’s harbour. AIMIA and Claudia Sagripanti from VentureOne organised it together.
It was a mixture of case studies and panels. The case studies were talks by successful digital media companies, including Sony, Bebo, Viocorp, Clear Light Digital and Fox Interactive Media (really: mySpaceTV). The panels constituted each a moderator and a small number of industry experts that briefly presented on their knowledge on a specific topic and then discussed this topic led by questions from the audience.
I thought the format was very successful and the conference covered a broad range of current topics of interest in digital media. Panel topics included:
mobile: challenges for getting video onto mobile and making a return on it
business models: how to make money from online video
sports video: what business models work with sports content
metrics: why we need to measure video and what and how
innovations: what innovative products are to be expected in the near future in video
I was one of the panellists on the metrics panel - my slides are here. The very last slide provides a very basic preview of the video metrics service that is in development at Vquence right now. Expect the final product to look much more professional, once I’ve included the awesome designs that we have just received from Chiz.
One thing that I took away from the conference is that the online video market is finally maturing and we are seeing business models that work. While they can roughly be classified into ad-supported, sponsored, and user-paid, there are many details that you have to take care of dependent on the service that you are providing. Ad-support can be inside the video e.g. in pre-roll, post-roll, mid-roll, overlay, or accompanying ads e.g. in dynamically loaded roll-outs, banners etc. Sponsorship is mostly used for non-profit sites. User-paid models are e.g. subscriptions, pay-per-view, pay-per-download. General video sites work not so well for ad-support as specialised sites. There is a lot of money for videos in specialised areas where your community is very keen to receive the latest video content fast, e.g. in sports.
In mobile in Australia, video business is still hard going, because the bandwidth costs are high, extra production cost is high, and because of challenges to get video into a usable form on such a small screen (e.g. soccer-ball is too small to be more than a pixel). This also means that the cost for consumers to get video is high, while the quality is still low. This obviously does not make for a very good market. The size of the iPhone screen, combined with the slow realisation by mobile phone providers that they have to drop prices for video transfers, may however totally change this situation.
Finally, I noticed that there was a large call for metrics. Measurement of the use of video and tracking the distribution of videos around the Internet, as well as measurement of advertising that relates to videos are all being requested to get more transparency into the business and mature the market. Initial services are available, in particular from existing Web Analytics and Internet Market Intelligence companies. However, the technology is new and we have a long way to go online and even more on mobile. This is a great opportunity for Vquence!
Thanks very much, Claudia, for organising this event and I hope there will be more to come in this space.
If you have any engagement with the development of open standards and open source software in the digital media space, consider attending. To attend, all we ask for is an email to the committee. Really simple!
We will have travel sponsorship for some key people and if the last two years are anything to go by, we will see some serious improvements to open media technology coming out of FOMS - an event that always stretches over the whole duration of LCA.
This should come as no surprise, since video is undoubtedly the most effective content on the Web: “People are about twice as likely to play a video, or replay one that started automatically, than they are to click through standard JPG or GIF image ads.”
Wikipedia defines “viral video” as “video clip content which gains widespread popularity through the process of Internet sharing, typically through email or IM messages, blogs and other media sharing websites.” This describes more the process through which viral videos are created rather then what a viral video actually is.
I tried to analyze the types of viral videos around to understand what a viral video really is. I found that there are three different types and would like to provide a list of descriptive features of each (leave a comment if you disagree with the types or want to suggest more).
The reason for this separation of types is that if you are a company and want to create a viral video advertising campaign, you need to decide what type of viral video you want to create and choose the appropriate approach and infrastructure to allow for that type of viral video to be successful.
Here are the three types of viral videos that I could distinguish:
popular video
A video that has a high view count (in the millions) - possibly emerged over a longer time frame - is viral because in order to get such a high view count, many people must have been told about it and been directed to go to it and watch it.
A prime example of such a video is the “Hahaha” video of a baby laughing, which is currently at position 10 of YouTube’s Most Viewed of All Time page. I would also put the “Evolution of Dance” video into this category, which alone on YouTube has seen over 81M page view and has therefore the top rank on the Most Viewed of All Time videos on YouTube. This video has some aspects that make it a cult, but I don’t think they are strong enough.
The features of videos in this category are as follows:
high page view count
not subject to fashion or short-term fads
interest for many audiences
hasn’t spawned an active community
The reason for the last feature is that a popular video is simply a video that is a “must see” for everybody, but it doesn’t instill in people an urge to “become involved”. This is a bit of black-and-white painting of course - see also how many people created copies of the “Evolution of Dance” - but it is a general feature that applies to most of the audience.
cult video
Videos that become “cult” are not necessarily videos that achieve the highest view counts. They will however achieve a high visibility and almost 100% coverage in a certain sub-community. Such videos are regarded as viral since they virally spread within their target community. Sometimes they even create a community - their fan club.
The main aim of these videos is not a high view count on a single video, but an active community that is highly motivated to have the video be part of their culture.
A typical example is the “Diet Coke and Mentos” phenomenon. I would not be able to point to a single video on this phenomenon but there is a whole cult that has emerged around it with people doing their own experiments, posting videos, discussing it on forums, helping each other on IM etc. There are even fan clubs on Facebook.
The features of videos in this category are as follows:
many videos have been created on the same topic, in particular UCG
often, it is not clear which was the originating video that started the phenomenon
there is a substantial view count on the individual videos
not subject to fashion or short-term fads
interest for a sub-community mostly
has spawned an active community, possibly with their own website
I would use the “Ask a Ninja” series of vodcasts as another example of a cult video. It has a central website and a very active community of fans around it.
trendy video
The term “Internet meme” has been coined for the videos in this category. They are essentially videos that create a high amount of activity around the Internet for a short time, but then people lose interest and move on. They are trendy for a limited amount of time.
A typical example in this category is the “Dramatic Chipmunk” with more than 7M views on YouTube on this one video, and further millions of views on the diverse mash-ups that were created. At one point, it was a “must see” and you had to have mashed it up to be “in”. Now it has been replaced by Rick Rolling - the activity of pointing people to a URL of something but then falsely directing them to Rick Astley’s video of “Never Gonna Give You Up” on YouTube with more than 9M page views.
The features of videos in this category are as follows:
videos achieve high page view in a short amount of time
audience interest vanishes after a limited time
often consists of funny, shocking, embarrassing, bizarre, or slanderous content
there is a substantial view count on the video(s) related to the phenomenon
creates high user activity for a short time e.g. through mash-ups, remixes, or parodies
Now that we have defined the different types of viral videos there are the lessons for viral video marketing campaigns.
If you want to create a popular video, create a beautiful, time-less video like the Sony Bravia Bunnies ad that everybody just has to have seen. Then make sure to release it on the Internet before you release it on TV by uploading to YouTube and a set of other social video hosting sites. Feel free to complement that with your own Website for the video. Start the viral spread through emailing your employees, friends, social networks, etc and rely on the cool-ness of the video to spread.
If you want to create a cult video, you should create something that will excite a sub-community and provide the opportunities for the community to emerge. Blendtec did this very well with their “Will it Blend?” videos and website. I actually believe, they should open that Website even further an allow discussion forums to emerge. They could pull all those blender communities at Facebook into their site. OTOH they could just be involved in the social networks that build elsewhere around their brand to make the most from their fan base.
If your video ad is however just meant to create a high audience activity for a short time, you might consider doing a shocking video like the one Unicef created with the Smurfs. Or something a little less extreme like the funny German Coastguard video created by the Berlitz Language Institute.
This is not my typical blog post, but if it helps achieve the goal, so be it.
Zen Kavanaugh, who used to develop the Ogg DirectShow filters is not able to continue maintaining these. Therefore, the DirectShow filters are now searching for a new maintainer.
If you develop in Windows and are able to compile, test and package the DirectShow filters that are available from http://www.illiminable.com/ogg/, please consider becoming the maintainer.
At this point in time, there is not much actual development required - just the occasional application of a patch, compilation, packaging and then publication.
This is really important, so if you can help you should really consider stepping forward.
It’s great to read at ClickZ that the Interactive Advertising Bureau (IAB) is preparing new format guidelines for video advertising. This includes pre-, mid- and post-roll, overlays, product placement, and companion ads (display ads placed alongside video).
The standard is currently in public comment phase, which closes on 2nd May 2008.
It is good to see that the standard also contains recommendations on the ratio of ad-to-content and on capping the frequency of ads to save the consumer from overly getting swamped with advertising.
The effect this standard will have on the video advertising industry will be enormous. Content publishers will build their websites with these standards in mind and provide generic advertising spaces into which they can then include advertising as required from the appropriate advertisers. Advertisers can create ads that will be re-usable across websites. And video advertising agencies can finally start to emerge that provide the market place for video ads to find their locations.
This is a sign that online video advertising is maturing and more generally that free online video distribution will become more viable for content owners.
For Vquence this is great news since all this new advertising will need to be measured for impact - I expect the need for video analytics will grow enormously. :-)
Yesterday, YouTube gave video metrics to their users. If you have uploaded videos to YouTube, you can go to your video list and click “About this video” to see a history of view counts. Very simple, but a good move.
It is great to see YouTube provide this service, even if just for your own, personally uploaded videos. It validates the newly emerging industry category of “online video metrics”, that Vquence is also a part of.
Our colleagues from VisibleMeasures expressed a similar feeling in their blog entry saying: “we view anything that companies can do to help showcase the need and improve the landscape for video measurement as a plus for the entire ecosystem”. I couldn’t express it any better.
Following the blogging community, there is alargeneed for online video metrics, both for tracking your own published videos - as YouTube has started providing since yesterday - as well as tracking videos published by the market generally for market analysis and intelligence reasons.
The number of players in the field is still small and FAIK we are the only Australians to offer these services.
U.S. spending on internet video advertising alone is expected to grow to US$4.3 billion by 2011. The need for online video publications is predicted to grow even stronger in the near future when each and every Website will be expected to use video to communicate their message. The need for video metrics will increase enormously.
Check out our new Website if you want to learn more about how Vquence measures video.
If you’re a student and keen to get more open media technology to the Web, apply for a Google summer of code project with Xiph. There are also a few Annodex-style projects in the mix, which bring annotations and metadata to Ogg.
Your interest could be with javascript, ruby, php, XML, or C no matter - you will find a project at Xiph to suit your favorite programming language.
Of the list of proposed projects, my personal favorite is OggPusher - a browser plugin for transcoding video to Theora. Imagine an online service for transcoding video to Ogg Theora without having to worry about having all the libraries installed.
You also have the chance to propose your own project to the Xiph/Annodex guys - you just need to find somebody who is willing to mentor you, so hop on irc channel #xiph at freenode.net and start discussing.
Incidentally, Google is providing a financial reward for successful conclusion of a project - but don’t let that be your only motivation. If you’re not in it with your passion, don’t do a GSoC project. This is about interacting with an open source community whose goals you can identify with. Become involved!
Late last year at Xiph we worked over our mime types and file extensions for Xiph content. The new set avoids using .ogg for everything and gives the different Xiph audio files a .oga (audio/ogg) and the Xiph video files a .ogv (video/ogg) extension, while using .ogx for more generic multiplexed content in Ogg. It’s important to separate between audio-only and video files - the codecs inside don’t really matter as much to select the appropriate application to start for using the file.
Try it out and be amazed! It should work in any browser - provide feedback to Michael if you discover any issues.
All of Metavidwiki is built using open standards, open APIs, and open source software. This give us a taste of how far we can take open media technology and how much of a difference it will make to Web Video in comparison to today’s mostly proprietary and non-interoperable Web video applications.
The open source software that Metavidwiki uses is very diverse. It builds on Wikipedia’s Mediawiki, the Xiph Ogg Theora and Vorbis codecs, a standard LAMP stack and AJAX, the Annodex apache server extension mod_annodex, and is capable of providing the annotations as CMML, ROE, or RSS. Client-side it uses the capabilities of your specific Web browser: should you run the latest Firefox with Ogg Theora/Vorbis support compiled in, it will make use of this special capability. Should you have a vlc browser plugin installed, it will make use of that to decode Ogg Theora/Vorbis. The fallback is the java cortado player for Ogg Theora/Vorbis.
Now just imagine for a minute the type of applications that we will be able to build with open video APIs and interchangable video annotation formats, as well as direct addressing of temporal and spatial fragments of media across sites. Finally, video and audio will be able to become a key part in the picture of a semantic Web that Tim Berners-Lee is painting - a picture of open and machine-readable information about any and all information on the Web. We certainly live in exciting times!!!
Today, for the millionth time I had to listen to a statement that goes along the following lines: “CMML technology is not ideal for media annotations, because the metadata is embedded with the object rather than separate”.
For once and all let me shout it out: THIS IS UTTER BULLSHIT!
I am so sick of hearing this statement from people who criticise CMML from a position of complete lack of understanding. So, let me put it straight.
While it is true that CMML has the potential to be multiplexed as a form of timed text inside a media file, the true nature of CMML is that it is versatile and by no means restricted to this representation.
In fact, the specification document for CMML is quite clearly a specification of a XML document. CMML is in that respect more like RSS than a timed text format.
Further, I’ll let you in on a little secret: CMML can be stored in databases. Yes!! In fact, CMMLWiki, one of the first online media applications that were implemented using Annodex, uses a mysql database to store CMML data. The format in which it can be extracted depends on your needs: you can get out single field content, you can put it in an interchangeable XML file (called CMML), or you can multiplex it with the media data into an Annodex file.
The flexibility of CMML is it’s beauty! It was carefully designed to allow it to easily transform between these different representations. It’s powerful because it can easily appear in all these different formats. By no means is this “not ideal”.
There are 28 participants to the startup carnival and each one of them is being introduced through an interview that was taken electronically. Questions for this interview were rather varied and detailed. They included technical and system backgrounds as well as asking for your use of open source software.
All the questions you have always wanted to ask about Vquence, and a few more. ;-)
UPDATE: The Startup Carnival has announced the prizes and they are amazing - first prize being an exhibition package at CeBIT. Good luck to us all!!
I have been so busy with my work as CEO of Vquence since the end of last year that I’ve neglected blogging about Vquence. It’s on my list of things to improve on this year.
I get asked frequently what it is that we actually do at Vquence. So here’s an update.
Let me start by providing a bit of history. At the beginning of 2007 Vquence was totally focused on building a social video aggregation site. The site now lives at http://www.vqslices.com/ and is useful, but lacks some of the key features that we had envisaged to have a breakthrough.
As the year grew older and we tried to create a corporate business and an income with our video aggregation, search and publication technology, we discovered that we had something that is of much higher value than the video handling technology: we had quantitative usage information about videos on social video sites in our aggregated metadata. In addition, our “crawling” algorithms, are able to supply up-to-date quantitative data instantly.
In fact, I should not simply call our data acquisition technology a “crawler” because in the strict sense of the word, it’s not. Bill Burnham describes in his blog post about SkyGrid the difference between crawlers of traditional search engines and the newer “flow-based” approach that is based on RSS/ping servers. At Vquence we are embracing the new “flow-based” approach and are extending it by using REST APIs where available. A limitation of the flow-based approach is that just a very small part of the Web is accessible through RSS and REST APIs. We therefore complement flow-based search with our own new types of data-discovery algorithms (or “crawlers”) as we see fit. In particular: locating the long tail of videos stored on YouTube is a challenge that we have mastered.
But I digress…
So we have all this quantitative data about social videos, which we update frequently. With it, we can create graphs of the development of view counts, comment counts, video replies and such. See for example the below image for a graph that compares the aggregate view count of the videos that were published by the main political parties in Australia during last year’s federal election. The graph shows the development of the view count over the last 2.5 months before the election in 2007.
At first you will notice that Labor started far above everyone else. Unfortunately we didn’t start recording view counts that early, but we assume it is due to the Kevin07 website that was launched on 7th August. In the graph, you will notice a first increase on the coalition’s view count on the 2nd September - that’s when Howard published the video for the APEC meeting 2-9 Sept 2007. Then there’s another bend on the 14th September, when Google launched it’s federal election site and we saw first videos of the Nationals going up on YouTube. The dip in the curve of the Nationals a little after that is due to a software bug. Then on the 14th October the Federal Election was actually announced and you can see the massive increase in view count from there on for all parties, ending with a huge advantage of Labor over everybody else. Interestingly enough, this also mirrors the actual outcome of the election.
So, this is the kind of information that we are now collecting at Vquence and focusing our business around.
On that background, check out a recent blog post by Judah Phillips on “Thinking about Measuring Internet Video?”. It is actually a wonderful description of the kind of things we are either offering or working on.
Using his vocabulary: we can currently provide a mix of Instream and Outstream KPI to the video advertising market. Our larger aim is to provide outstream audience metrics that are exceptional and we know how to get them regardless of where the video goes on the Internet. Our technology plan centers around a mix of a panel-based approach (through a browser plugin) and a census-based approach (through a social network plugin for facebook et al, also using OpenID), and video duplicate identification.
This information isn’t yet published at our corporate website, which still mostly focuses on our capabilities in video aggregation, search, and publication. But we have a replacement in the making. Watch this space… :-)
The report of the recent W3C Video on the Web workshop has come out and has some recommendations to form a Video Metadata Working Group, or even more generally a Web Video Working Group.
I had some discussions with people that have a keen interest in the space and we have come up with a list of topics that a W3C Video Working Group should look into. I want to share this list here. It goes into somewhat more detailed than the topics that the W3C Video on the Web workshop has raised. Feel free to add any further concerns or suggestions that you have in the comments - I’d be curious to get feedback.
First, there are the fundamental issues:
Choice of royalty-free baseline codecs for audio and video
Choice of encapsulation format for multi-track media delivery
Both of these really require the generation of a list of requirements and use cases, then analysis of existing format with respect to these requirements and finally a decision on which ones to use.
Requirements for codecs would encompass, amongst others, the need to cover different delivery and receiving devices - from mobile phones with 3G bandwidth, over Web video, to full-screen TV video over ADSL.
Here are some requirements for an encapsulation format:
usable for live streaming and for canned delivery,
the ability to easily decode from any offset in a media file,
the use for temporal and spatial hyperlinking and the required partial delivery that comes with these,
the ability to dynamically create multi-track media streams on a server and to deliver requested tracks only,
the ability to compose valid streams by composing segments from different servers based on a (play)list of temporal hyperlinks,
the ability to cache segments in the network,
and the ability to easily add a different “codec” track into the encapsulation (as a means of preparing for future improved codecs or other codec plugins).
The decisions for an encapsulation format and for a/v codecs may potentially require a further specification of how to map specific codecs into the chosen encapsulation format.
Then we have the “Web” requirements:
The technologies that have created what is known as the World Wide Web are fundamentally a hypertext markup language (HTML), a hypertext transfer protocol (HTTP) and a resource addressing scheme (URIs). Together they define the distributed nature of the Web. We need to build an infrastructure for hypermedia that builds on the existing Web technologies so we can make video a first-class citizen on the Web.
Create a URI-compatible means of temporal hyperlinking directly into time offsets of media files.
Create a URI-compatible means of spatial hyperlinking directly into picture areas of video files.
Create a HTTP-compatible protocol for negotiating and transferring video content between a Web server and a Web client. This also includes a definition of how video can be cached in HTTP network proxies and the like.
Create a markup language for video that also enables hyperlinks from any time and region in a video to any other Web resource. Time-aligned annotations and metadata need to be part of this, just like HTML annotates text.
All of these measures together will turn ordinary media into hypermedia, ready for a distributed usage on the Web.
In addition to these fundamental Web technologies, to integrate into modern Web environments, there would need to be:
a standard definition of a javascript API to interact with the media data,
an event model,
a DOM integration of the textual markup,
and possibly the use of CSS or SVG to define layout, effects, transitions and other presentation issues.
Then there are the Metadata requirements:
We all know that videos have a massive amount of metadata - i.e. data about the video. There are different types of metadata and they need to be handled differently.
Time-aligned text, such as captions, subtitles, transcripts, karaoke and similar text.
Header-type metadata, such as the ID3 tags for mp3 files, or the vorbiscomments for Ogg files.
Manifest-type description of the relationships between different media file tracks, similar to what SMIL enables, like the recent ROE format in development with Xiph.
The time-aligned text should actually be regarded as a codec, because it is time-aligned just like audio or video data. If we want to be able to do live streaming of annotated media content and receive all the data as a multiplexed stream through one connection, we need to be able to multiplex the text codec into the binary stream just like we do with audio and video. Thus, the definition of the time-aligned text codecs have to ascertain the ability to multiplex.
Header-type metadata should be machine accessible and available for human consumption as required. They can be used to manage copyright and other rights-related information.
The manifest is important for dynamically creating multi-track media files as required through a client-server interaction, such as the request for a specific language audio track with the video rather than the default.
Other topics of interest:
There are two more topics that I would like to point out that require activities.
“DRM”: It needs to be analysed what the real need is here. Is it a need to encrypt the media file such that it can only be read by specific recipients? Maybe an encryption scheme with public and private keys could provide this functionality? Or is it a need to retain copyright and licensing information with the media data? Then the encapsulation of metadata inside the media files may be a good solution already, since this information stays with the media file after a delivery or copy act.
Accessibility: It needs to be ascertained that the association of captions, sign language, video descriptions and the like in a time-aligned fashion to the video is possible with the chosen encapsulation format. A standard time-aligned format for specifying sign language would be needed.
This list of required technologies has been built through years of experience experimenting with the seamless integration of video into the World Wide Web in the Annodex project and through further recent discussions from the W3C Video on the Web workshop and elsewhere.
This list is just providing a structure towards what is necessary to address in making video a first-class citizen on the Web. There are many difficult detail problems to solve in each one of these areas. It is a challenge to understand the complexity of the problem, but I hope this structure can contribute to break down some of the complexity and help us to start attacking the issues.
I am really excited about the huge progress we made at FOMS with metadata and Ogg. The metadata specifications are actually not Ogg-specific - only their mapping into Ogg is. Here are the things that I expect will make for a very structured and sensible distributed handling of metadata on the Web.
At FOMS, we started improving CMML and are now specifying the next version of CMML. CMML is a timed text description language that can easily be multiplexed alongside audio or video data. It is very flexible with its fields and satisfies needs for hypermedia, captions, annotations and other time-aligned text. We took out the Ogg dependencies and it can now be used in any media container format. The specification is now also in an XML schema rather than a DTD, which enables us to reuse modules from XHTML and make it generally more extensible.
We introduced ROE, a description language (or a “manifest”) for multitrack media files. It describes media tracks and their dependencies and thus goes much further than the old stream and import elements in CMML, that now have been deprecated.
ROE can be used to author multitrack media files - in the Ogg case to author Ogg files with a Skeleton track and multiple media tracks. We are in the process of extending Skeleton to incorporate the description of dependencies between logical bitstreams. To complete this, we will be creating a description of how to map ROE into Ogg/Skeleton and vice versa.
ROE can also be used to negotiate with a Web client what media streams to send from the complete manifest that is available on the server. For example, a Web client could request the German sound track with a movie rather than the default English one, and to add English subtitles. This requires a small protocol for negotiation, which can easily be build using Web infrastructure. We are introducing some new HTTP request/response parameters and specific URLs, such as e.g. http://example.com/movie.ogg?track=V1,A2,TT2.
The set of ROE, Skeleton, CMML, and the HTTP and URI specifications will enable a very structured means of interacting with metadata-rich video on the Web. It will be distributed and integrated into the Web infrastructure, much like the Annodex set of technologies already is today.
Since I am also a business owner aside of being an open media enthusiast, let me add that I expect it to have a huge impact on online business around audio and video, enabling business processes and business models that are not possible today. Watch this space!
When I started organising the first FOMS (Foundations of open media software developers workshop) in 2007, I did it because I saw a need to have media hackers get together in a room and discuss stuff in person. Email, irc, svn, bugzilla and wikis only get you a certain distance for collaboration. But no distance communication tool can replace the energy and creative spirit that is created through an in-person meeting and the ability to have a beer together in the evening. Discussions are more intense, impossibilities are identified faster, progress is amazing - and the energy will last and have an impact on the community for months to come after the event.
FOMS 2007 was great in that respect, because some 25 hackers got to know each other for the first time, friendships were formed, trust was built and new ideas (speaking: new code) was created. It was awesome and gave me the motivation to go and organise FOMS 2008. At this point let me express my gratitude to the organising committees of both FOMS 2007 and FOMS 2008 for the support they have given me to organise both workshops and hope they will help again next year in Tasmania.
So then FOMS 2008 took place and what can I say!? It totally blew me away. For me it was a much better experience than the year before because I didn’t also organise the video recordings at LCA. I was therefore more relaxed, got involved in design discussions, and was able to sit down during the week after FOMS at LCA and actually interact with people. On a side note here: Thanks so much to Donna Benjamin, the main organiser of LCA 2008, for getting the FOMS participants a room to ourselves where we were able to gather and get an awesome whole lot of work done.
Nearly the whole Xiph community was at FOMS and issues that have been brewing for years were tabled and discussed. A large number of audio hackers were there, too, and the issue of a standard sound APIs got some heated discussion. There’s a press release and the proceedings of the FOMS discussions up on the FOMS 2008 website, where you can make yourself a complete picture of all the issues that were discussed.
In addition to FOMS, Conrad Parker and I had also organised a Multimedia Miniconf at LCA. It was a great place to communicate some of the outcomes of FOMS and to present some of the latest developments in open media software in the Linux community. Video proceedings are available on the site.
Overall I must say that January has become the highlight of my year in open media software.
I’ve been meaning to write about this for a while, but haven’t found a good motivation yet. Today I stumbled across the videos from RailsConf2007 on Blip.tv and decided - this is it! I will show off the nice new sexy layout of the Vquence player with this content - after all, we are a rails shop (apart from all those other programming languages that we use).
Julian has worked over the design of the player in December and done an awesome job. The image pane’s scroll slows down as your reach the left or right border. It works similar to a scrollbar, where if you go to the middle of the image pane, it will scroll to the middle clip in the playlist. As you leave the image pane, it snaps back to focus on the clip that you are currently watching.
The new player also has a lot more text in it. As you mouse over the images, you get the titles of the clips. As you click on the (i) button, you get the annotations of the current clip (click (i) again to make it go away). At the beginning of each clip, there’s a small text reminder at the top that a click on the video will take you to the full video.
And finally - to give the video more space, the transport bar actually disappears as you keep watching and stop interacting with the player. This gives it more of a sit-back experience. The possibility to activate the full-screen display also adds to this experience.
Overall, I am really thrilled how far we have taken the player. Enjoy!
(But should you have any feedback or suggestions for improvement, feel free to shoot me an email or leave a comment.)
Many people wonder what the future of video on the Web should be and want a more integrated and simpler video solution than what flash provides right now.
At the recent W3C’s video workshop, I realised that people’s requirements and expectations go far beyond what the HTML5 spec is currently providing. And most of those requirements can be satisfied with the Annodex technologies. But it will need a lot of explaining, documenting and demonstrating to show that Annodex provides these solutions in a simple, yet comprehensive manner. And what’s more: any technology developed to satisify the requirements will need to take on board many of the design decisions that we made for Annodex, so I hope, whatever will be the next Video Web technology, we can provide our input.
The most fundamental point to understand is that you cannot create a solution for video webs without considering all aspects of handling video on the Web in an integrated fashion. This includes topics such as the URI addressing scheme, seeking and indexing of video, the metadata and annotation scheme, and how all of this fits together with the binary video data and Web servers. Let me repeat: these topics have to be addressed together and not as separate projects, because they influence each other!
Apart from Annodex, no other existing or suggested video technology for the Web brings together all the required facets to really solve the big picture - and that includes video metadata specifications, hyperlinking approaches, codecs etc.
Having said all of this, let me demonstrate to you what I mean by full integration.
Shane Stephens has been coding on a library that brings native Annodex support into Web browsers (called liboggplay) and has provided me with a video that demonstrates what you can do as a programmer once your Web browser understands Annodex. Take note of the integrated use of annotations. And also of the simplicity of URI addressing. And the use of an adapted Web server.
[I wrote this more than 8 months ago, but didn’t want to publish it at the time because I want us to solve the issues around video in HTML5 and not fight each other. But I’ve made some changes and I’m now ready to have it published.]
There’s a clash of ecosystems happening at the WHATWG mailing list around the need for the specification of a baseline codec for a future
The clash is mostly between the open community which want Ogg Theora as a recommended baseline codec and big vendors (Apple & Nokia), which wanted that recommendation taken out. They claim that such a recommendation has nothing to do in a HTML standard, which should specify tags but not recommend external file formats. From one perspective, I agree - some things are better left to the software engineers to decide and left open to the market. However, in this particular instance, I think it would be a big mistake not to specify a baseline video codec. In fact, it would in my mind make the whole move to a new HTML5 standard an irrelevant exercise.
Let’s look at history and play a mind game on the consequences of such a decision.
Around the turn of the century we had a wonderfully diverse situation: we had RealMedia, QuickTime and WindowsMedia all being video formats that people expected to find on the Internet and to stream video. It most certainly made business sense to the involved companies! However, it made no business sense to Web developers and media content producers. They had to set up a transcoding and streaming infrastructure for all these three formats in parallel if they were wanting to reach all their potential clientele. I have actually seen this happening here in Australia at the ABC, which has a mandate to serve all the Australian people and therefore had to provide video in all potential formats. I remember the pain that was written across the faces of the infrastructure people.
A few years fast forward and the ABC can now give sighs of relief: supporting Adobe Flash, they can do away with all this expensive and support-intensive infrastructure and just support one codec.
Another story from the past to keep in mind is the story of PNG and GIF http://www.libpng.org/pub/png/pnghist.html where the collecting of royalties on the GIF codec started the creation of the open and free PNG format, which became a W3C recommendation in 1996 (see http://www.w3.org/Press/PNG-PR.en.html). TBL states in there “We are seeing more of our Members adopt the format and are helping make it the industry standard.”
With these in mind, let’s try and project into the future.
Assuming we do not provide a baseline codec in the spec, what will happen is that we will see each browser adopt support for the codec that “makes business sense”, i.e. Microsoft will support WindowsMedia, and Apple will support QuickTime, while the rest will be looking for a “cheaper” codec which could e.g. be MPEG-1 or Ogg Theora. Or stated differently: we will end up with the same situation that we had around 2001 with streaming codecs, except that Web developers and content owners still have the choice of Flash through the object/embed tag. Who will we confuse? The consumers who will be wanting to create their own content and publish it online. They will want a free and interoperable option. Since that’s not to be had, they will choose what makes most sense on their OS platform - i.e. QuickTime on Macs (comes for “free”), WindowsMedia on Windows, and Ogg Theora on Linux. Yes, this makes business sense to some of us. It will certainly make Adobe happy because - as before - Flash will come out as the winner.
Assuming we do provide a baseline codec in the spec, a very similar situation will actually happen and the browsers will support different codecs initially, since Ogg Theora is just a recommendation, which will probably not be implemented in Apple or MS Web browsers. However, now, Web developer and content owners have a focus on what format they should be providing through the recommendation in the standard. And they will request support for the recommended baseline format from the vendors. So, there may actually be a chance that the confusing mess of codec formats may be sorted after a while. This is the chance we have to make things easier for Web developers and online businesses - and this is why a baseline codec is imperative.
What we now need is to address the issues of Apple, Nokia and MS with Ogg Theora. These are mostly around submarine patents. My suggestion is that the W3C pay an independent patent attorney to perform a patent research on Ogg Theora to address the perceived risks of the big vendors. If the patent search is as comprehensive as possible, we may reach a situation where the big vendors do not perceive the risk any longer. However, there is also a risk that Theora is found to infringe specific patents. I guess we will then either correct the codebase or just have put all our development efforts into Dirac. :-) In any case - all the FUD that is currently being sent both ways can then be addressed more easily with some decent data behind it.
We are in the middle of a big technological change for the dear old World Wide Web. And it will have a massive impact on how we are using video on the Web.
Not only is the Web Hypertext Application Technology Working Group (WHATWG) defining an all-new HTML5 standard which will have a native video tag (just as current HTML4 has a native img tag).
The W3C is wondering how to go even beyond that onto a road that will make video a first-class citizen on the Web. Next week, a W3C Video Workshop will be held on that exact topic.
Funnily enough, when we described the aim of the Annodex project at CSIRO in the year 2000, we used those exact words: how to make video a first-class citizen on the Web. At that time, people thought we were crazy. Now that YouTube is a commonly accepted phenomenon, we can actually see the limitations of existing video technology on the Web: we can still not interact as naturally with video as we do with Web pages - we can still not search well for video - and we can still not mash-up video as easily as we do with HTML pages, e.g. through RSS feeds.
I will be travelling to the US next week to share our experiences on Annodex with the Web World and have my input on what the future of video on the Web should look like. To that end, I have submitted two position papers to the workshop - one on Temporal URIs and one on our experiences with Annodex and CMML. Check out the other cool talks on the agenda or even the full list of position papers that got submitted!
Also, I have just been asked whether I would like to be part of the “Future of Video and Next Steps” Panel on the second day of the workshop - a panel that has been very well selected to represent online and traditional video technology, content interests, and consumer interests. I am looking forward to a very lively discussion and a great overall workshop that may be the first step towards a better video web.
Video on the Web is still only at the beginning of its evolution - comparable to the evolution that film and movie theatres have gone through over the last hundred years. It’s awesome to be working on the next technology revolution and to see that the best is yet to come!
A few years ago when I was still at CSIRO, I was contacted by Linda Barwick from PARADISEC to research into the use of Annodex for linguists. The main problem was that ethnographic researchers are publishing research outcomes on paper or even HTML, which are essentially discussions about small sections of field recordings of exotic languages - however, they had no means to do citations of these sections through hyperlinks or any other simple interactive means. In the time of online media, that should be a trivial task, right? But it wasn’t. Annodex and the timed URIs provided the right basis for a solution.
Fast forward lots of months of work in the EthnoER project and you get a solution for ethnographic researchers which is unique and completely based on open formats and open source software. Check out Linda’s blog entry of today!
Congratulations to everybody who has put all that effort into the project - Nick Thieberger, Linda Barwick, Shane Stephens, Stuart Hungerford, Jonathan McCabe, and all the others whom I forgot. EthnoER and Annodex might have changed the way in which linguistic research online can be published - not a small feat at all!
In the last few weeks, I’ve created an Internet-Draft (I-D - a draft specification of an IETF RFC) for the Ogg Skeleton meta track, and updated the CMML I-D to include a new element called “caption” (CMML DTD). All of this is work that should have been done a long time ago, but I only got the motivation for it through the WHATWG work on HTML5 which will take Ogg Theora and Ogg Vorbis as baseline codecs. Since liboggplay is the key open source library that implements this baseline codec support, and liboggplay supports Annodex, it seems plausible that Annodex (which adds essentially Skeleton + CMML) will be available in Web browsers of the future. So, now is the time to fix up the few open issues that remain and cast the specifications into readable I-Ds.
If you haven’t seen the great functionality that will be available with liboggplay, you should check out the liboggplay javascript API. I’ve seen Shane make a demo web page through which you can toy with the javascript API, but haven’t got the link available right now.
Tonight is Webjam night in Sydney and I have custom created a Vquence for this occasion on my favorite band right now: “My Chemical Romance”. I’ll be presenting in a slide show how to go about getting it to here:
Am looking forward to getting to know other Web 2.0 players in Sydney!
It is awesome to see FOMS - the Open Media Software developer workshop we ran for the first time this year - turning into a major audio and video developer event for Linux. FOMS 2008 will be in Mel8ourne in January and will focus on audio on Linux (in particular libsydneyaudio) and on native Firefox support for Ogg Theora (in particular liboggplay). Because of the latter, FOMS has attracted sponsorship by the Mozilla Foundation. This sponsorship is very welcome since most of the relevant developers come from overseas and are not part of large organisations that could afford to pay the expense. Check out the current list of participants on the site - it will be another milestone event for open media! And … thanks Mozilla Foundation!
Today, I had to deal with some badly behaving Flash content. The debugging process involved some extensive use of google and brought out a few interesting facts, which I thought would be good to be put together into a coherent story.
Webpages that embed Flash together with other layers of Web page content generally suck - in particular on Linux. It’s not the Web design that sucks - in fact: being able to use “depth” in a Web page is actually really nice for fitting more content on a page without making it too crowded (or hammering those flash ads at us - sigh).
Indeed, it is the technology that sucks because Flash on Linux doesn’t do what it’s supposed to do. Flash misbehaves on Linux by being bullish and always trying to stay dominant in the foreground over the top of DHTML content, even though being told not to. Don’t be prejudiced though: it’s not Adobe’s fault - or at least “not only”.
Before we try to teach Flash good manners, let’s first understand the problem.
When you embed an Adobe Flash 9 swf file in a Web page, Adobe provides a parameter called “wmode” (windowless mode), through which Flash is being told to be either “transparent” or “opaque”, either of which will prevent a Flash from playing in the topmost layer and allow you to adjust the layering of the movie within other layers of the HTML document. Layering in HTML is done by using the z-index.
Now, using wmode and “transparent” teaches Flash good manners on most operating systems. However, when the Flash ends up on a Linux computer, it’s old dominant personality returns and it turns evil again.
Yes, it is a bug. However, it is quite an interesting and long-standing bug - and longer-standing in Mozilla than other Linux Web Browsers, too.
Here is the story: On the 12th April 2002, Braden registered Bug 7189 with Mozilla about window-less plugin support on X. It was soon established that in principle window-less support is possible on Linux and the bug was re-focused on Flash. It turned out that multiple levels of fixes were necessary to get this working: at first, X needed window-less plugin support - a patch to fix this was provided by Dec 2004 by Pete Collins. Next thing necessary was support by Adobe to have an active “wmode” parameter, which was provided by end 2006. In April 2007 finally there was a first patch for Mozilla. A later patch was finally applied to trunk on July,2nd 2007. W00t!!
So, while we are all waiting for this patch to make it into Firefox and Linux distributions, to finally end up on our Desktop and make Flash behave, there is indeed a way for keen Web developers around this problem. And I can’t believe I’m actually going to say this: iFrames were the answer to our problem in my July’s blog post - and iFrames are again the answer here. Evil, detested, but oh so useful iFrames. Who would have thought…
To complete the pack, LCA MultiMedia is an a/v miniconf for LCA in planning, such that LCA attendees will also have a chance to hear the latest and most exciting news from the developer bench.
FOMS 2007 was a huge success. It brought face-to-face some of the core Linux audio and video developers, which promptly started attacking some of the key obstacles for an improved audio/video experience on Linux and with open media software in general.
Jean-Marc Valin (author of speex), Lennart Poettering (author of PulseAudio) a group of programmers from Nokia and a few others started designing libsydneyaudio - a library which is deemed to solve the mess of audio on Linux in a means that is also cross-platform compatible.
Also, a community started building around liboggplay, a library designed to allow drop-in playback of Xiph.Org media in an application. libogg is currently being prepared for a submission to Mozilla to provide native Ogg (and Annodex) support inside Firefox as part of the new HTML5 . Then, Ogg Theora, Vorbis & Speex will play out of the box on a newly installed Firefox without requiring to install any further helpers software.
These are just the highlights from FOMS 2007 - expect more exiting news from FOMS 2008!
Last week, YouTube brought out a new flash video player. The player had thumbnails of related videos from YouTube content included directly into the embedded video as you moused over it. This provides access to other YouTube videos through any embedded video.
People who have seen what we do over at Vquence noticed the similarity in the user interfaces. They also assumed that therefore the functionality must be the same. However, quite the opposite is true.
YouTube is a video hosting site. People upload videos there to publish them and most probably to re-embed them into their own websites. When you use video hosting, you don’t want your video hosting provider to suddenly display other videos on top of the one you have embedded, since that changes the perception of the page that you have created around the video.
In contrast, Vquence is a video aggregator. The Vquence video player is for “playlists” (rather: slicecasts or vquences) of videos collected from multiple hosting sites. So, when you embed the Vquence player, you expect display of and easy access to all the videos in the slicecast. It is a very different concept: the aim is not the embedding of a video, but rather the recommendation of multiple videos to your readers. Vquences enable you to share your bookmarked videos in a viewer-friendly fashion. It’s not about embedding videos in your page - it’s about providing hyperlinks to videos by using videos.
Last week, we put a new front page on http://www.vqslices.com/, which shows off the concept of “vquences”. A vquence is essentially a collection of video bookmarks presented as a “video mash-up” and in an embeddable “widget”. Or without bullshit: we concatenate 10sec previews of the bookmarked videos into a playlist, which is embeddable into other sites. And since it’s embeddable - here is an example vquence:
This vquence shows some snippets from Missy Higgins videos - she’s such a great singer! If you cannot see it here (due to planet sanetisation), go to http://www.vqslices.com/vq/dXelFQeQCr3kFQaby-aaea .
Vquences are a powerful concept and we’re right now working on the beta website, which will bring authoring to you out there, so you can create your own vquences. Also, we are working towards providing a REST API to register sites with Vquence, and RSS feeds, so you can always keep up to date on the latest vquences. Lot’s of other developments in the pipeline here…
Today we nailed down a policy for Xiph on what file extensions and mime types we recommend using for Xiph technology.
Basically, we have introduced some new file extensions to allow applications to more easily identify whether they are dealing with audio (.oga) or video (.ogv) files, or some random multiplexed codecs inside Ogg (.ogx).
We recognized the fact that existing Ogg Vorbis hardware players will need to continue to work with whatever scheme we come up and therefore decided to dedicate the extension .ogg to Ogg Vorbis I files - and deprecate all other use of it. That includes the deprecation of the use of Ogg Theora and Ogg Flac with this extension. In future, Ogg Theora files should have a .ogv extension and Ogg Flac a .oga extension. (For further details, check out the wiki page.)
MIME types will be changed accordingly and the RFCs required to register them will start to be authored now.
None of this has been written in stone yet though and there is still time to change this policy if it doesn’t make sense. So if you have any strong objections, speak up now!
As I was playing with Ogg Theora lots for LCA, I needed to script the extraction of keyframes from Ogg Theora files.
There’s a manual way to achieve this through totem: you just use ctrl-s to capture a frame. However, I didn’t want to do this for every one of the hundreds of videos that we captured.
Here’s a script that I found somewhere and might work for you, but it didn’t work for me: dumpvideo foo.ogg | yuv2ppm | pnmsplit - image-%d.ppm; for file in image-*.ppm; do convert $file `basename $file .ppm`.jpeg; done
What worked for me in the end was a nice and simple call to mplayer: mplayer -ss 120 -frames 1 -vo jpeg $file
I’ve just come across this cool video site which aggregates the “best tech videos” - and what do you know - it has many of the LCA videos there, too! Awesome!
As you may know, Vquence is the online video startup that Chris Gilbey and I have created over the past months. We now have a great team of people working with us.
We’ve worked hard on our new Web presence to get a nice modern logo and Web design, to produce some good pictures to describe what we actually do, and to give a sneak preview of our technology.
Go check out the video on the front page. It’s a flash player (sorry, not Annodex yet) and has some awesome functionality hidden inside - thanks to Peter Withers, Michael Dale and Jamie Madden. Click on the video slices as they are playing. And notice how all the full videos are hosted on different video hosting sites (sorry to all those hosting providers who missed out - we simply haven’t got enough people working for us yet ;).
Thanks to Julian Frumar and Alister Walters for all the great design work, to Chris Gilbey and Richard McKinnon for the copy, and to Matt Moor and John Ferlito for getting the hosting under control with some cool scripts to be used for future rollouts of our final product.
This week, we’ve been working hard towards getting the corporate website for my new company Vquence up. As part of that, we shot videos of most of our key people in an attempt to “eat our own dogfood”: show off our slicecasting technology, which comes as embeddable vquences (video sequences). The idea is to extract slices from a set of videos, collate them together like highlights, and make them clickable - so people can click through to the full length videos.
On click-through, we wanted to have the embedded videos from those hosting sites to start playback directly without enforcing people to make another click on the image. This has turned out as quite a challenge.
Not every video hosting site that supports embedding also supports autoplay. Here’s what I found.
The following sites provide an autoplay parameter for their embed tags (only key components shown in the code):
VSocial: <embed src="http://static.vsocial.com/flash/ups.swf?d=yyyy&**a=1**&s=xxxxxx"/> - be warned though that their player takes a third for menu stuff
I know that both Guba and iFilm have an autoplay feature since the video on their websites plays without the need for an additional activation, but I couldn’t find out what parameters were needed or which other flash player I would need to use.
Revver simply refuses to support this feature reasoning that nobody would want a video to play back automatically without the need for an interaction. Guys - come on! Nowadays videos live on their own Web page. A person that is navigating to that Webpage and knows what they are navigating to shouldn’t really have to jump an additional hurdle just to get your videos to play!
BTW: I was unable to manage to upload a video to Metacafe from my Mac inside Firefox, although I tried for 3 days. :-( - worked now!
I do not claim to have tested all the video hosting sites out there. But these are a good selection and my current state of experience.
Ah yes: go and enjoy our new site - http://www.vquence.com/ - and don’t forget to check out the videos at the bottom of the front page.
It is particularly amazing since to everyone who has licensed from the MP3 licensing consortium was held under the impression that with that license they are off the hook for all patents related to MP3.
Well, now that MP3 is coming of age and any related patents will be running out fairly soon, Alcatel-Lucent has decided to take a share of the cake - and a rather large one.
What is worrying is that through this step, all companies that are licensing “standardized” codecs and thought that getting a license through the standards body would cover all possible infringement, now have to fear that there is always another hidden patent somewhere, which somebody can pull out of the hat at any time to sue them.
Doesn’t that put the aim of standardization on its head?
To me it just confirms that standardized technology should be technology that is not covered by patents and that the standards body has to make sure that such patents don’t exist.
Unfortunately, ISO/MPEG - and other standardisation bodies - have worked in the exact opposite direction until now: everyone who participated in MPEG made sure to get as many patents registered with MPEG as possible so as to get as large a share of the licensing payments as possible.
The only solution out of this mess is to create media codecs that are not infringing patents. Luckily, Xiphophorus is doing exactly that. So, this should encourage media companies to use Ogg Vorbis and Ogg Theora.
And if these codecs are too “old” for you, expect the new Dirac codec from the BBC to shake up things a lot! Open source, open standard, and the latest wavelet technology - should be un-beatable!
The first FOMS (Foundations of Open Media Software) workshop is over and it was an overwhelming success - more than ever expected! And wow - we have videos of it, too - thanks to Ralph Giles and Thomas Vander Stichele.
The goal of FOMS was to bring a diverse group of people from all around the planet who are all working on open media software together for the first time so they could get to know each other, exchange ideas, and generally address the things that annoy us all with open media technologies.
Strategically placing FOMS in the week before LCA was a great idea: not only would some of the developers attend LCA anyway and thus would not need to use up extra travel time, but also would LCA provide opportunities for the newly forged relationships to flourish and create code.
A new forum for discussion was created and since the community has committed to achieving a set of community goals, we expect it will have some basic effect on the usability of open media software over time.
And yes … all participants are up for a repetition of FOMS - possibly as a precursor to other FLOSS conferences overseas, but at a minimum again at next year’s LCA in Melbourne. Let’s rock it!
I’ve just fixed some missing links on the LCA video site, so all the talks are now online - yay!
It’s been an interesting experience, which is still not finished. I’m working on collecting all the slides for the talks and putting them into a common format (probably both pdf and odf). Jean-Marc is still working on transcoding the videos to speex (speech-only). And then there are all the annotations that we received through the irc channel, which I’d like to publish onto a cmmlwiki together with the videos.
It will all come in good time. The hardest and most important task were the videos.
I think we found a good formula this year to make the videos happen. DV tapes are impossible to handle. Recording to DVD provides a good backup straight away and a simple storage means. It could be further simplified if recording was done straight to disk and everything handled as files only, which is the way in which the DebConfs were done. But then - I am a big fan of having physical, high-quality backups.
Here’s a little FAQ for those annoying recurring questions:
Why are there not all miniconf talks present? We did not aim to record Monday and Tuesday, but rather used them as testing days for the equipment and the team. Therefore, having any video at all from the miniconfs is a bonys.
The sound is rather quiet on some videos - can you fix that? Unfortunately, some days came out really quiet and it will take a lot of post-processing to fix this. We don’t have the time and people to undertake this. So, just turn up your speakers, the volume on your desktop and on the application.
What software did you use to transcode and publish? We are only publishing the video in the open and free Ogg Theora format. Since we recorded straight to DVD, all we had to do thus was to rip the DVDs using "vobcopy" (with the “-l” option in order to get all the pieces on the DVD stiched together). If the resulting vob file consisted of multiple sessions, then the timing restarted in the middle which confuses transcoding. So, we used "avidemux" to recreate a correct MPEG_TS (transport stream). The resulting vob file was transcoded to Ogg Theora using a ffmpeg2theora script and finally uploaded to the server using "scp" with the “-l” option. On a fast machine and a fast connection, each of these steps is faster than realtime (i.e. takes less time than the duration of the video). My slowest process was the upload, which I had to do over night in batch from my home ADSL connection.
How much space do the published Ogg Theora files use? Using the “-p preview” option of ffmpeg2theora provides you with 384x288 video at 25 fps for PAL recordings. The size in bytes varies a lot between the files. Our largest file is about 257MB and is from a 1:23 hrs long talk. Our shortest file is about 10MB and is from a 6 min long talk. Overall we’re using 11.9GB of disk space for 141 files. That comprises only the Ogg Theora video files. The vob files are a bit more than 10 times the size of a Ogg Theora file, so we don’t keep them on the server.
I’ve just been asked to give a recommendation on the kind of setup a LUG would require to do regular video recordings. Here is the email reply that I wrote - and now thought I should share through my blog.
—
The tech gear that is required to record LUG meetings depends on the amount of effort that you want to put in and the type of rooms you are recording.
—
I would certainly recommend an expensive tripod - it needs to be heavy to be stable and smooth for panning and tilting. Trust me: it makes a world of a difference!
Then, you will need a DV camera - consumer-quality will be plenty. Don’t go for a DVD camera - their recording capacity is 30 min only. They are thus good to capture random walk-around footage, but not talks.
Finally, hook up a headphone to your camera to be able to hear what it records.
This is the baseline equipment, really. Record to DV tapes, later hook up the camera to your computer, use Kino to rip and edit (mostly trim front and back), use ffmpeg2theora to transcode, and you’re done.
—
The only problem with this equipment is that you will not get good sound unless you are able to hook up to a PA output. Here is where the complexity starts, since most theatres don’t provide you with such output. All the art in video production is in the audio.
A first step to improving the sound is by using lapel mics (make sure your camera can take mic input). These give you the speaker in perfect sound quality.
What you may still be worrying about is the questions and the laptop sound.
To get the questions, you need wireless handheld mics. But now you have two sound sources that need mixing. Well, the cheapest approach to that is a Beachtek XLR adapter, which you screw under your camera onto the tripod and takes 2 inputs to mix down to one with mic output.
If you’re really keen and want to get the laptop sound, too, you end up with three inputs and now you need a proper mixer to take all the signals in.
—
Another improvement to make is the medium onto which you record. DV tapes are rather hard to handle and take ages to rip. We wanted a simpler process and thus bought some consumer DVD recorders that we’d hook up to the firewire output of the cameras to do recording.
Of course you want to monitor that the recording is actually happening, so we also bought some small black/white TVs, which we got from Toys’R’US for under $20.
You can throw the DVDs into any computer and transcode from there. They are also a good back-up medium. And they require lots less storage than DV tapes and are much easier to organise.
And this is my preferred future setup for SLUG: DV camera, tripod, lapel mic, DVD recorder, TV.
I keep getting asked how we did the technical setup, so let me share it here.
With Video at LCA, this year, we did not want a repetition of the more experimental setups of previous years. We set out with only one goal: to publish good quality video during LCA to increase the number of talks that people will be able to look at and discuss. Our only aim is the Ogg Theora format since it is the only open video codec and what would a conference on FLOSS be if we didn’t stick to our ideals even with codecs!
One consequence of our narrow goal is that you will not find any live video streaming at LCA in 2007. The reasoning behind this is that we reach maybe a few hundred people with streaming, but that publishing reaches millions. Another reason is that previous years of video recordings at LCA have mostly had problems with one particular part in this picture: computers. So, we decided to take the computer out of the recording process and only use it in the transcoding, uploading and publishing part of the conference.
We are therefore recording from the DV cameras straight to DVD, which provides us with a physical backup as well as a quick way to get the data into the computer (in comparison to using DV tapes). Though this means that we use a non-free compression format in the middle of our process, it makes it a lot less error-prone. We’re waiting for the day when we can replace our camera - DVD recorder setup with Ogg Theora recording hard-disk cameras!
But the technical part of the video recordings is only one part of the picture. If you want good quality footage, you have to put people behind the cameras at all times. Speakers do weird things and a recording of slides with voice-over is not a very sensible video recording of conference talks. You really require a minimum of 2 people per lecture hall to cover the semi-professional setup that was required for the Mathews theatres: one looking after the audio and the other after the video, with a bit of slack time to give each other a break.
In parallel to the camera crews, we have a transcoding and upload team, which constantly receives the DVDs (and the DV tape backups) from the recording rooms. You also need stand-by people for relief. The upload process involves editing of the start and end points of videos, then a transcode to Ogg Theora and an upload to a local file server at the conference. This video gets mirrored to a Linux Australia Server and published into the conference Wiki through an automatic script.
We are very lucky to have a competent and reliable A/V team of volunteers at LCA 2007 who give up their opportunities to attend the conference for the greater good of all of us. Each team member covers all the days and it takes a lot of dedication to be up in the morning before everyone else (and possible after a hard night’s partying) and working a full day behind the camera or the computer. One of the team members even spent his birthday behind the camera!
I’d like to thank everyone on the A/V Team (in no particular order):
Timothy Terriberry,
James Courtier-Dutton,
Michael Dale,
Holger Levsen,
Nick Seow,
Sridhar Dhanapalan,
Chris Deigan,
Jeremy Apthorp,
Andrew Sinclair,
Andreas Fischer,
Adam Nelson,
Ryan Vernon, and
Ken Wilson.
In addition, the networking people have worked hard to make the uploading and publishing process as smooth as possible - I’d like to thank in particular John Ferlito and Matt Moor for their hard work.
It was a great experience to work with such a large team in such a professional setup where we managed to overcome many technical and human challenges and get the first video published even during LCA!
I’ve just finished writing a small script that will help us edit and transcode video recorded at LCA 2007. Since we will record directly to DVD, we will need a simple laptop with a DVD drive and the installed software gmplayer and ffmpeg2theora to do the editing and transcoding, before uploading to a Web server. Which means that just about all LCA participants are potential helpers for making sure the video material gets published on the same day.
If you happen to be a LCA participant and want to help ascertain video publishing happens, please walk up to the video guys and offer your editing & transcoding help.
Ah yes, and here is the script - in case anyone is interested:
#!/bin/sh # usage function function func_usage () { echo "Usage: VOB2Theora.sh " echo " starttime/endtime given as HH:MM:SS" echo " filename input file for conversion" } # convert from SMPTE to seconds function func_convert2sec () { tspec=$1; tlen=${#tspec} #strlen # parse seconds out of string tsecstart=$[ ${tlen} - 2 ] tsec=${tspec:$tsecstart:2} #substr # parse minutes tminstart=$[ ${tlen} - 5 ] if test $tminstart -ge 0; then tmin=${tspec:$tminstart:2} #substr else tmin=0 fi # parse hours thrsstart=$[ ${tlen} - 8 ] if test $thrsstart -ge 0; then thrs=${tspec:$thrsstart:2} #substr else thrs=0 fi # calculate number of seconds from hrs, min, sec tseconds=$[ $tsec + (($tmin + ($thrs * 60)) * 60) ] } # test number of parameters of script if test $# -lt 3; then func_usage exit 0 fi # convert start time func_convert2sec $1 tstart=$tseconds # convert end time func_convert2sec $2 tstop=$tseconds # input file inputfile=$3 if test -e $inputfile; then echo "Converting $3 from $tstart sec to $tstop sec ..." echo "" else echo "File $inputfile does not exist" exit 1; fi # convert using ffmpeg2theora strdate=`date`; strorga="LCA"; strcopy="LCA 2007"; strlicense="Creative Commons BY SA 2.5"; strcommand="ffmpeg2theora -s $tstart -e $tstop --date '$strdate' --organization '$strorga' --copyright '$strcopy' --license '$strlicense' --sync $inputfile" echo $strcommand; sh -c "$strcommand";
Have you ever been stuck with a video file that does not play in any of your video players or the Web Browser? It happens frequently because the media technology landscape is still a very fragmented one where a lot of energy is put into the creation of proprietary compression technologies. But the consumer is unwilling to follow every new encoding format and to pay for codecs which he/she may only need for this one file.
Just as the use of free and unencumbered text encoding formats (ASCII, UTF-8) is a prerequisite to the development of novel applications and an enabler of email, the Web, and many other common applications, free video and audio formats enable the creation of novel applications with media.
Free and unencumbered codecs are starting to become mature. The codecs from Xiph.org cover audio (Vorbis, Speex, FLAC) and video (Theora) are readily available and supported on many platforms. The BBC’s next-generation video codec called Dirac is still in the labs, but is one of the few cutting-edge codecs built on Wevelets, a novel transform that promises higher compression rates with less artefacts - and it is free and unencumbered.
However, the availability of codecs is not all that matters. Audio-visual applications that make use of these codecs need to be developed, too. Applications such as video editors, desktop audio/video players, Webbrowser embedded players, and streaming technology are fundamental to enable the full production-to-publishing chain. And then there are the higher-level applications such as playlist and collections manager (iTunes-like), video Web hosting, video search, or Internet video conferencing applications which provide the real value to people.
Foundations of Open Media Software is the first conference ever to bring together the architects of open media software systems from around the world to address technical issues and further the development of a open media ecology where the focus is on the development of new high-value applications rather than a tiring and unproductive competition of formats.
FOMS furthers the development of media technology on Linux, addresses support of open media codecs across platforms, and works towards the creation of an ecosystem of rich media applications.
The principles of creative commons content around a free exchange of ideas through digital media requires adequate licenses to be attached to media files, which in turn will only work in an environment where the media formats of such content is unrestricted and unencumbered, too.
Foundations of Open Media Software takes place in Sydney, Australia 11th-12th January 2007. Since it is a conference organised by developers for developers, donations are highly welcome. There are also some spaces for professional delegates available still. Details are at http://www.annodex.org/events/foms2007/ .
No, Google do not offer a video search service, don’t be blinded. Time and time again I have to explain that Google’s video.google.com is a video hosting service, not a horizontal video search service. They do not follow their own mission with Google video, but offer search only on their own collection of content, i.e. they offer vertical search and not search on “the world’s” video, which is what horizontal search is about.
And now they have acquired YouTube - btw: this was a really cheap deal, too, through a masterly financial stragey. But I diverge - I am not a market analyst, but a technologist. And I want to share what I see as an immense opportunity for Google in this deal.
Let me go back in history: Google started video.google.com because there was not enough video content on the Web and thus a dedicated video search engine didn’t make much sense. So they ran a dual strategy to get content on the Web: they made it simple for consumers to upload their content thus starting the wave of consumer-created (and consumer-mediated) content. And they mediated content from the old media industry to go online. This instantly put Google into the video hosting business.
Fast-forward a year and you find YouTube did a better job at providing consumers with a video hosting service. So, Google buys them. With what intention? To have a second video hosting business? Maybe… but to be quite honest, I have a different take on this.
This is the chance for Google to turn the Google brand away from video hosting and back to horizontal video search. With YouTube they have a channel to move their existing corporate customers and their upload users to a more successful hosting site. Then they can get their core brand back into search.
Bah - gotta get back to coding, so our company is ready for when the time comes!
From Thursday 11 - Friday 12 January 2007 we will have some of the world’s top open media software developers gather in Sydney at a workshop titled “Foundations of Open Media Software” (FOMS).
The workshop takes place in the week before linux.conf.au (LCA), thus enabling developers to cross-pollinate with the developers and attendants of LCA. FOMS is supported by LCA with venue and other logistics.
I’m happy to be one of the core organisers of this workshop and very excited about the vibe that this will bring to the open media software developer community. FOMS creates a venue for a community that has thus far not had its own gathering place.
In January: Sydney will rock the FOSS world doubly!!
I’ve spent a lot of time recently analysing video on the Web.
YouTube and Google Video introduced what seems to be the standard now: videos get published on what I like to call a “host page”. This is one webpage completely dedicated to this video.
Why are there still so many videos out there that get published through a hyperlink behind two words of text instead of giving them proper recognition?
Think about it: the creation of a video usually costs a lot of effort and when it’s done, it needs a proper presentation. Hiding it behind a hyperlink is like putting your blog up on an ftp server in pdf format.
So, what information has to be on a video host page?
Best practice is to have an embeddable video player on the host page that displays a keyframe.
Other information that typically resides on a host page is a short textual description of the video, its duration, who published it, who created it, license rights (check out Creative Commons for this), tags & category attributions, comments from viewers, number of page views, and a description of how to use this thing in other environments, such as how to embed it in blogs or how to download it to the iPod or PSP.
We don’t need Google or YouTube to do this for us. We can publish video in that way ourselves. Well, maybe apart from the bit about transcoding to the iPod or PSP. Incidentally, is there any open source SW around to do that?
We can transcode our videos to Ogg Theora using ffmpeg2theora and then publish it with the embedded java theora player Cortado. Then we just need to create our own host page in html.
All we need now are a few more plugins for common Web content management systems like WordPress or drupal to simplify this process even more. Here’s your Friday afternoon challenge. :-)
Videos will be everywhere on the web! Yes, cope with it: soon the majority of videos won’t be with some hosting site like youtube, but it will reside on our private servers, on company servers, actually on any and all web servers. And there will be interesting stuff, but it will be hard to find.
Yes, history will repeat itself again and finding those videos on the Web that satisfy our need - be it for information or entertainment - will be a nightmare. Why? Because google’s pagerank (and many other ranking algorithms) rely on Web pages pointing to the videos to give them a higher rank. However, the way in which videos are currently published is through embedding them into Web pages (let’s call such a page the “embedding page”). Thus, the link analysis will actually return the pagerank for the embedding page - but not for the video itself!
Now, if the embedding page can actually be seen as representative for the video because the only reason that the webpage exists is to publish the video and its annotations, then the pagerank for the embedding page is actually the same as the pagerank for the video. This is the case for google video and for youtube and for many other hosting sites.
However, you and I mostly publish our videos in blogs or on Web pages that describe more than just the video - some will even have several videos embedded. This is where the chaos for a Web search engine for videos begins. And this is where the discoverability of your videos through video search engines ends.
Here is the solution.
Just as we do with normal Web pages, we have to introduce SEO (search engine optimisation) for videos. That means, we have to make it easier for the search engines to find out information about our videos, i.e. to index and rank them.
Because videos are binary data, a common Web search engine cannot extract information about this Web resource directly from it (let’s ignore signal analysis and automatic content analysis approaches for the moment). We have to help the search engine.
The solution is to have a text file sitting “next” to the actual video file which contains indexable text about the video. It will have all the annotations, meta data, tags, copyright information and other textual meta information that search engines require to index and rank it better. This text file is an indexable textual representation of the video.
So, whenever a video search engine reaches a video in a crawl, it will check out this text file for its indexing work. If this text file is HTML, then people may link directly to it and it will be included in the pagerank calculations again. If it is a XML file, there should be a simple way to transcode it to HTML, e.g. via a xslt script, so links can go there directly again.
So much for the theory: here comes the practice.
For every video file (and incidentally it would work for audio, too), you should start writing a CMML file and publish it on your Web server together with the original. Here is a xslt script that you can use to transcode CMML to HTML. If you actually use Ogg Theora as your Video publishing format, you can even publish Annodex videos and make direct access to the clips that you defined in CMML and to time offsets possible by using the Apache Annodex module. Try using it in your blog with the external embedding of the Annodex Firefox extension.
When we’ve done this, all that remains is to encourage the video search engines to exploit the CMML data in their crawls. :)
So you think we’re in the middle of an “explosion” of online video clips, in particular consumer-created video clips? Think again. How many videos have you published online so far? Compare that to the number of web pages you have written or contributed to.
It’s still only very few people who upload clips. The “masses” haven’t even decided to start yet.
The “mass” consists of all the people who see something useful in uploading, making accessible, and finding video clips (and no, that’s not just pr0n). It took the Web a few years before companies started having a Web presence and to use the Web as a marketing instrument. It took private people even longer before they started having blogs and publish their cv and photo collections.
Videos can be used as much as a marketing instrument as a Web page. In a convergent world, videos will even be more important than text because it reaches the couch potato. People will start making videos about their success story in gardening, about their home-grown cooking receipe, about the way to repair a special valve on their car, about how to train pets - or children (“be your own super-nanny”). Small companies will make videos about their products, the corner-shop will advertise its services to the neighbourhood, the medical centre will present its doctors and procedures through online videos, the computer shop its software, the travel agency its best locations etc. The video explosion on the Web hasn’t even started yet.
Flumotion is a streaming server product developed by Fluendo. Flumotion runs in a distributed environment, where the video capture, encoding, and transmission can be run on different computers, so the load can be better balanced.
I have found it rather difficult to find an introductory help on how to get flumotion set up and running, so I’ll share my insights with you here.
Imagine a setup where you want machine A to capture and encode the video from a DV camera, machine B relaying the stream onto the Internet to several clients, and machine C getting the stream off machine B and writing it to disk. The software that you’d need to run on each of these machines is the following:
Run flumotion-manager on machine B. flumotion-manager is the central component of a flumotion streaming setup, which connects up all the components and makes sure that everything works. It has to run before anything else can happen.
Run flumotion-worker on every machine where you want work to be done, i.e. on machine A, B, and C. The workers are demons that connect to the manager and wait for commands to do something.
Run flumotion-admin on any machine to set up the details of the flumotion streaming setup.
So, here are the commands, that I use to get it running using the default setup:
flumotion start (which will run flumotion-manager -D -n default /etc/flumotion/managers/default/planet.xml for you).
flumotion-worker -u pants -p off & (yes, these are the default user name and password :).
flumotion-admin (and go through the GUI setup wizard).
… and you should be up and going with either your DV camera, your Webcam or your TV tuner card. Watch the cute smileys go happy! And connect to the stream using your favorite media player that can decode Ogg Theora/Vorbis, e.g. totem, vlc, xine.



 Using rtc.io rtc JS library
Using rtc.io rtc JS library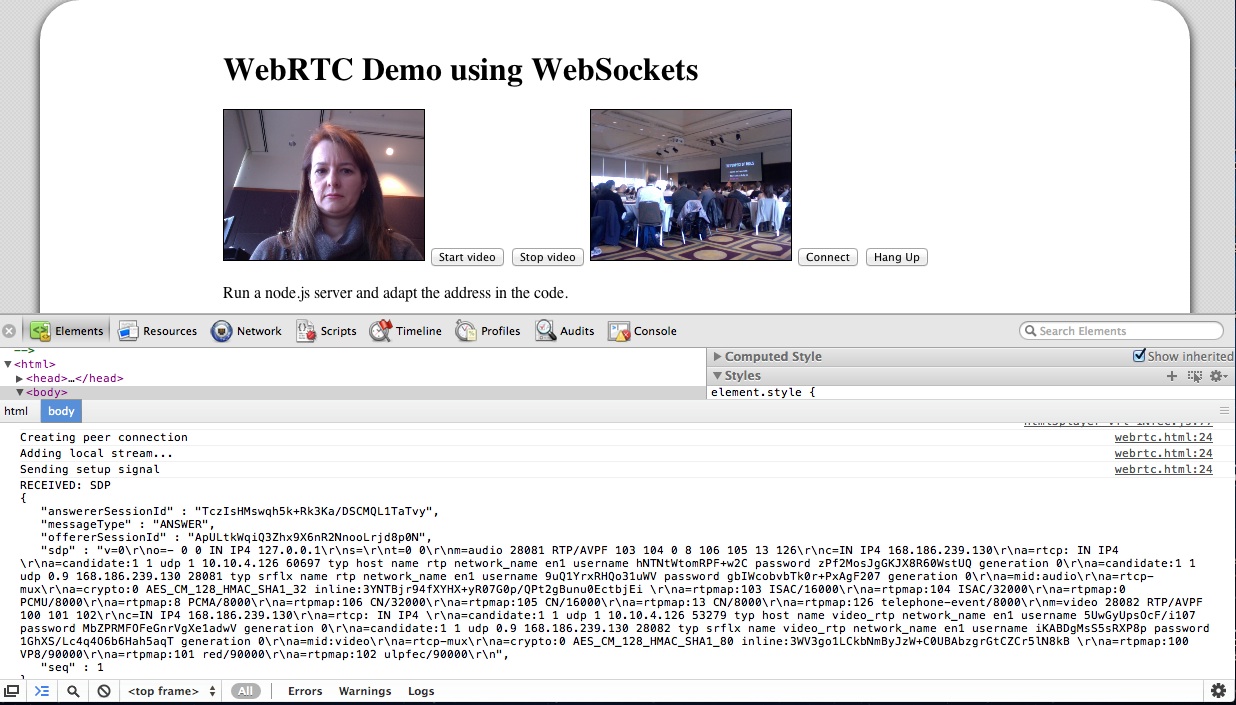







 Screenshot of first itext video player experiment
Screenshot of first itext video player experiment
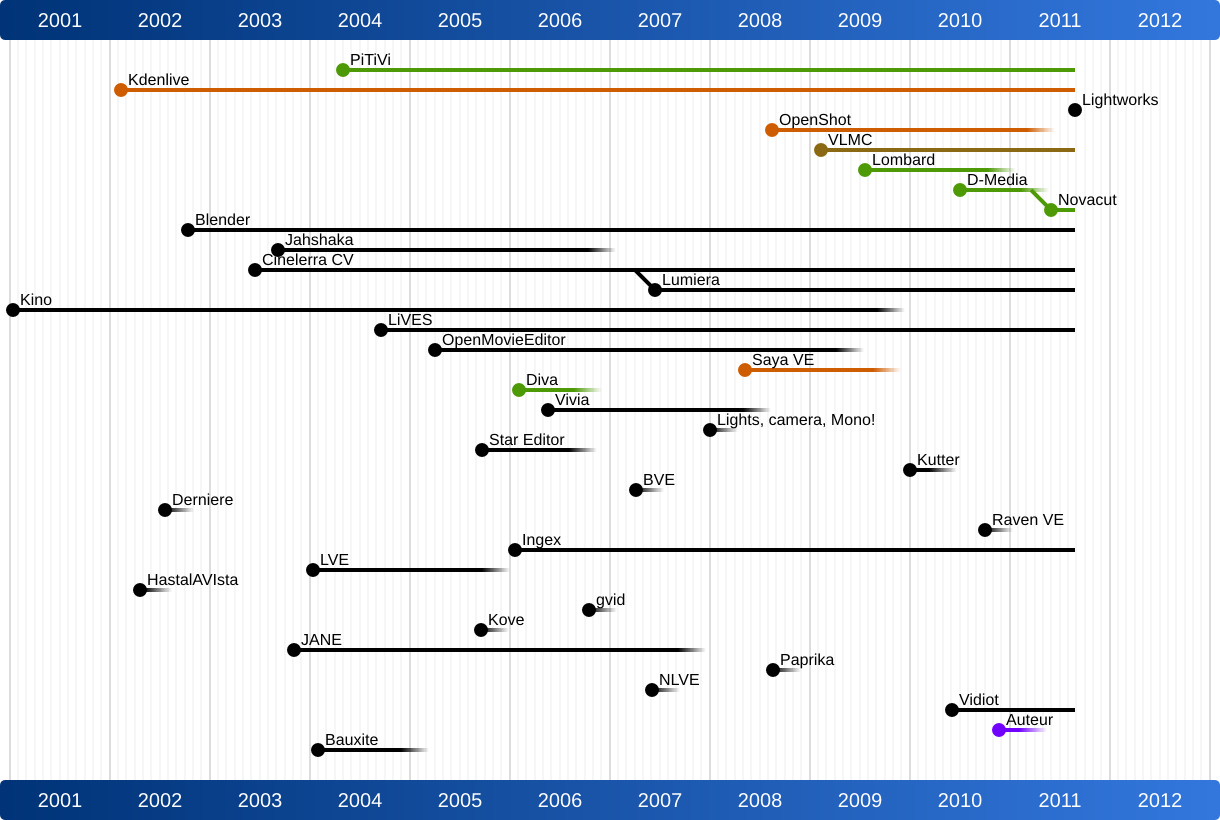{kind=link}