I wrote these predictions in the first week of January and meant to publish them as encouragement to think about where WebRTC still needs some work. I’d like to be able to compare the state of WebRTC in the browser a year from now. Therefore, without further ado, here are my thoughts.
WebRTC Browser support
I’m quite optimistic when it comes to browser support for WebRTC. We have seen Edge bring in initial support last year and Apple looking to hire engineers to implement WebRTC. My prediction is that we will see the following developments in 2016:
Edge will become interoperable with Chrome and Firefox, i.e. it will publish VP8/VP9 and H.264/H.265 support
Firefox of course continues to support both VP8/VP9 and H.264/H.265
Chrome will follow the spec and implement H.264/H.265 support (to add to their already existing VP8/VP9 support)
Safari will enter the WebRTC space but only with H.264/H.265 support
Codec Observations
With Edge and Safari entering the WebRTC space, there will be a larger focus on H.264/H.265. It will help with creating interoperability between the browsers.
However, since there are so many flavours of H.264/H.265, I expect that when different browsers are used at different endpoints, we will get poor quality video calls because of having to negotiate a common denominator. Certainly, baseline will work interoperably, but better encoding quality and lower bandwidth will only be achieved if all endpoints use the same browser.
Thus, we will get to the funny situation where we buy ourselves interoperability at the cost of video quality and bandwidth. I’d call that a “degree of interoperability” and not the best possible outcome.
I’m going to go out on a limb and say that at this stage, Google is going to consider strongly to improve the case of VP8/VP9 by improving its bandwidth adaptability: I think they will buy themselves some SVC capability and make VP9 the best quality codec for live video conferencing. Thus, when Safari eventually follows the standard and also implements VP8/VP9 support, the interoperability win of H.264/H.265 will become only temporary overshadowed by a vastly better video quality when using VP9.
The Enterprise Boundary
Like all video conferencing technology, WebRTC is having a hard time dealing with the corporate boundary: firewalls and proxies get in the way of setting up video connections from within an enterprise to people outside.
The telco world has come up with the concept of SBCs (session border controller). SBCs come packed with functionality to deal with security, signalling protocol translation, Quality of Service policing, regulatory requirements, statistics, billing, and even media service like transcoding.
SBCs are a total overkill for a world where a large number of Web applications simply want to add a WebRTC feature - probably mostly to provide a video or audio customer support service, but it could be a live training session with call-in, or an interest group conference all.
We cannot install a custom SBC solution for every WebRTC service provider in every enterprise. That’s like saying we need a custom Web proxy for every Web server. It doesn’t scale.
Cloud services thrive on their ability to sell directly to an individual in an organisation on their credit card without that individual having to ask their IT department to put special rules in place. WebRTC will not make progress in the corporate environment unless this is fixed.
We need a solution that allows all WebRTC services to get through an enterprise firewall and enterprise proxy. I think the WebRTC standards have done pretty well with firewalls and connecting to a TURN server on port 443 will do the trick most of the time. But enterprise proxies are the next frontier.
What it takes is some kind of media packet forwarding service that sits on the firewall or in a proxy and allows WebRTC media packets through - maybe with some configuration that is necessary in the browsers or the Web app to add this service as another type of TURN server.
I don’t have a full understanding of the problems involved, but I think such a solution is vital before WebRTC can go mainstream. I expect that this year we will see some clever people coming up with a solution for this and a new type of product will be born and rolled out to enterprises around the world.
Summary
So these are my predictions. In summary, they address the key areas where I think WebRTC still has to make progress: interoperability between browsers, video quality at low bitrates, and the enterprise boundary. I’m really curious to see where we stand with these a year from now.
—
It’s worth mentioning Philipp Hancke’s tweet reply to my post:
My new startup just released our MVP - this is the story of what got me here.
I love creating new applications that let people do their work better or in a manner that wasn’t possible before.
My first such passion was as a student intern when I built a system for a building and loan association’s monthly customer magazine. The group I worked with was managing their advertiser contacts through a set of paper cards and I wrote a dBase based system (yes, that long ago) that would manage their customer relationships. They loved it - until it got replaced by an SAP system that cost 100 times what I cost them, had really poor UX, and only gave them half the functionality. It was a corporate system with ongoing support, which made all the difference to them.
The story repeated itself with a CRM for my Uncle’s construction company, and with a resume and quotation management system for Accenture right after Uni, both of which I left behind when I decided to go into research.
Even as a PhD student, I never lost sight of challenges that people were facing and wanted to develop technology to overcome problems. The aim of my PhD thesis was to prepare for the oncoming onslaught of audio and video on the Internet (yes, this was 1994!) by developing algorithms to automatically extract and locate information in such files, which would enable users to structure, index and search such content.
Many of the use cases that we explored are now part of products or continue to be challenges: finding music that matches your preferences, identifying music or video pieces e.g. to count ads on the radio or to mark copyright infringement, or the automated creation of video summaries such as trailers.
This continued when I joined the CSIRO in Australia - I was working on segmenting speech into words or talk spurts since that would simplify captioning & subtitling, and on MPEG-7 which was a (slightly over-engineered) standard to structure metadata about audio and video.
In 2001 I had the idea of replicating the Web for videos: i.e. creating hyperlinked and searchable video-only experiences. We called it “Annodex” for annotated and indexed video and it needed full-screen hyperlinked video in browsers - man were we ahead of our time! It was my first step into standards, got several IETF RFCs to my name, and started my involvement with open codecs through Xiph.
Around the time that YouTube was founded in 2006, I founded Vquence - originally a video search company for the Web, but pivoted to a video metadata mining company. Vquence still exists and continues to sell its data to channel partners, but it lacks the user impact that has always driven my work.
As the video element started being developed for HTML5, I had to get involved. I contributed many use cases to the W3C, became a co-editor of the HTML5 spec and focused on video captioning with WebVTT while contracting to Mozilla and later to Google. We made huge progress and today the technology exists to publish video on the Web with captions, making the Web more inclusive for everybody. I contributed code to YouTube and Google Chrome, but was keen to make a bigger impact again.
The opportunity came when a couple of former CSIRO colleagues who now worked for NICTA approached me to get me interested in addressing new use cases for video conferencing in the context of WebRTC. We worked on a kiosk-style solution to service delivery for large service organisations, particularly targeting government. The emerging WebRTC standard posed many technical challenges that we addressed by building rtc.io , by contributing to the standards, and registering bugs on the browsers.
Fast-forward through the development of a few further custom solutions for customers in health and education and we are starting to see patterns of need emerge. The core learning that we’ve come away with is that to get things done, you have to go beyond “talking heads” in a video call. It’s not just about seeing the other person, but much more about having a shared view of the things that need to be worked on and a shared way of interacting with them. Also, we learnt that the things that are being worked on are quite varied and may include multiple input cameras, digital documents, Web pages, applications, device data, controls, forms.
So we set out to build a solution that would enable productive remote collaboration to take place. It would need to provide an excellent user experience, it would need to be simple to work with, provide for the standard use cases out of the box, yet be architected to be extensible for specialised data sharing needs that we knew some of our customers had. It would need to be usable directly on Coviu.com, but also able to integrate with specialised applications that some of our customers were already using, such as the applications that they spend most of their time in (CRMs, practice management systems, learning management systems, team chat systems). It would need to require our customers to sign up, yet their clients to join a call without sign-up.
Collaboration is a big problem. People are continuing to get more comfortable with technology and are less and less inclined to travel distances just to get a service done. In a country as large as Australia, where 12% of the population lives in rural and remote areas, people may not even be able to travel distances, particularly to receive or provide recurring or specialised services, or to achieve work/life balance. To make the world a global village, we need to be able to work together better remotely.
The need for collaboration is being recognised by specialised Web applications already, such as the LiveShare feature of Invision for Designers, Codassium for pair programming, or the recently announced Dropbox Paper. Few go all the way to video - WebRTC is still regarded as a complicated feature to support.
With Coviu, we’d like to offer a collaboration feature to every Web app. We now have a Web app that provides a modern and beautifully designed collaboration interface. To enable other Web apps to integrate it, we are now developing an API. Integration may entail customisation of the data sharing part of Coviu - something Coviu has been designed for. How to replicate the data and keep it consistent when people collaborate remotely - that is where Coviu makes a difference.
We have started our journey and have just launched free signup to the Coviu base product, which allows individuals to own their own “room” (i.e. a fixed URL) in which to collaborate with others. A huge shout out goes to everyone in the Coviu team - a pretty amazing group of people - who have turned the app from an idea to reality. You are all awesome!
With Coviu you can share and annotate:
images (show your mum photos of your last holidays, or get feedback on an architecture diagram from a customer),
pdf files (give a presentation remotely, or walk a customer through a contract),
whiteboards (brainstorm with a colleague), and
share an application window (watch a YouTube video together, or work through your task list with your colleagues).
All of these are regarded as “shared documents” in Coviu and thus have zooming and annotations features and are listed in a document tray for ease of navigation.
This is just the beginning of how we want to make working together online more productive. Give it a go and let us know what you think.
Putting that talk together reminded me about how far we have come in the last year both with the progress of WebRTC, its standards and browser implementations, as well as with our own small team at NICTA and our rtc.io WebRTC toolbox.
One of the most exciting opportunities is still under-exploited: the data channel. When I talked about the above slide and pointed out Bananabread, PeerCDN, Copay, PubNub and also later WebTorrent, that’s where I really started to get Web Developers excited about WebRTC. They can totally see the shift in paradigm to peer-to-peer applications away from the Server-based architecture of the current Web.
Many were also excited to learn more about rtc.io, our own npm nodules based approach to a JavaScript API for WebRTC.
We believe that the World of JavaScript has reached a critical stage where we can no longer code by copy-and-paste of JavaScript snippets from all over the Web universe. We need a more structured module reuse approach to JavaScript. Node with JavaScript on the back end really only motivated this development. However, we’ve needed it for a long time on the front end, too. One big library (jquery anyone?) that does everything that anyone could ever need on the front-end isn’t going to work any longer with the amount of functionality that we now expect Web applications to support. Just look at the insane growth of npm compared to other module collections:
Packages per day across popular platforms (Shamelessly copied from: nodejitsu.com)
For those that - like myself - found it difficult to understand how to tap into the sheer power of npm modules as a font end developer, simply use browserify. npm modules are prepared following the CommonJS module definition spec. Browserify works natively with that and “compiles” all the dependencies of a npm modules into a single bundle.js file that you can use on the front end through a script tag as you would in plain HTML. You can learn more about browserify and module definitions and how to use browserify.
For those of you not quite ready to dive in with browserify we have prepared prepared the rtc module, which exposes the most commonly used packages of rtc.io through an “RTC” object from a browserified JavaScript file. You can also directly download the JavaScript file from GitHub.
So, I hope you enjoy rtc.io and I hope you enjoy my slides and large collection of interesting links inside the deck, and of course: enjoy WebRTC! Thanks to Damon, JEeff, Cathy, Pete and Nathan - you’re an awesome team!
On a side note, I was really excited to meet the author of browserify, James Halliday (@substack) at WDCNZ, whose talk on “building your own tools” seemed to take me back to the times where everything was done on the command-line. I think James is using Node and the Web in a way that would appeal to a Linux Kernel developer. Fascinating!!
If you’ve been interested in WebRTC and haven’t lived under a rock, you will know about Google’s open source testing application for WebRTC: AppRTC.
When you go to the site, a new video conferencing room is automatically created for you and you can share the provided URL with somebody else and thus connect (make sure you’re using Google Chrome, Opera or Mozilla Firefox).
We’ve been using this application forever to check whether any issues with our own WebRTC applications are due to network connectivity issues, firewall issues, or browser bugs, in which case AppRTC breaks down, too. Otherwise we’re pretty sure to have to dig deeper into our own code.
Now, AppRTC creates a pretty poor quality video conference, because the browsers use a 640x480 resolution by default. However, there are many query parameters that can be added to the AppRTC URL through which the connection can be manipulated.
Here are my favourite parameters:
hd=true : turns on high definition, ie. minWidth=1280,minHeight=720
stereo=true : turns on stereo audio
debug=loopback : connect to yourself (great to check your own firewalls)
tt=60 : by default, the channel is closed after 30min - this gives you 60 (max 1440)
Rob explains very clearly how to create your first video, audio or data peer-connection using WebRTC in current Google Chrome or Firefox (I think it also now applies to Opera, though that wasn’t the case when his book was published). He makes available example code, so you can replicate it in your own Web application easily, including the setup of a signalling server. He also points out that you need a ICE (STUN/TURN) server to punch through firewalls and gives recommendations for what software is available, but stops short of explaining how to set them up.
Rob’s focus is very much on the features required in a typical Web application:
video calls
audio calls
text chats
file sharing
In fact, he provides the most in-depth demo of how to set up a good file sharing interface I have come across.
Rob then also extends his introduction to WebRTC to two key application areas: education and team communication. His recommendations are spot on and required reading for anyone developing applications in these spaces.
Alan and Dan’s book was written more than a year ago and explains that state of standardisation at that time. It’s probably a little out-dated now, but it still gives you good foundations on why some decisions were made the way they are and what are contentious issues (some of which still remain). If you really want to understand what happens behind the scenes when you call certain functions in the WebRTC APIs of browsers, then this is for you.
Alan and Dan’s book explains in more details than Rob’s book how IP addresses of communication partners are found, how firewall holepunching works, how sessions get negotiated, and how the standards process works. It’s probably less useful to a Web developer who just wants to implement video call functionality into their Web application, though if something goes wrong you may find yourself digging into the details of SDP, SRTP, DTLS, and other cryptic abbreviations of protocols that all need to work together to get a WebRTC call working.
---
Overall, both books are worthwhile and cover different aspects of WebRTC that you will stumble across if you are directly dealing with WebRTC code.
The key driving force for improvements to WebVTT continues to be the accurate representation of CEA608/708 captioning. As part of that drive, we’ve introduced regions (the CEA708 “window” concept) to WebVTT. WebVTT regions satisfy multiple requirements of CEA608/708 captions:
support for rollup captions
support for background color and border color on a group of cues independent of the background color of the individual cue
possibility to move a group of cues from one location on screen to a different
support to specify an anchor point and a growth direction for cues when their text size changes
support for specifying a fixed number of lines to be rendered
possibility to specify which region is rendered in front of which other one when regions overlap
While WebVTT regions enable us to satisfy all of the above points, the specification isn’t actually complete yet and some of the above needs aren’t satisfied yet.
We have an open bug to move a region elsewhere. A first discussion at FOMS seemed to to indicate that we’ll have to add syntax for updating a region at a particular time and thus give region definitions a way to be valid only for a certain time frame. I can imagine that the region definitions that we have in the header of the WebVTT file now would have an implicitly defined time frame from the start to the end of the file, but can be overruled by a re-definition anywhere within the WebVTT file. That redefinition needs to provide a start and end time.
We registered a bug to add specifying the width and height of regions (and possibly of cues) by em (i.e. by multiples of the largest character in a font). This should allow us to have the region grow/shrink around the region anchor point with a change of font size by script or a user. em specifications should also be applied to cues - that matches the column count of CEA708/608 better.
When regions overlap, the original region extension spec already suggested a “layer” cue setting. It will be easy to add it.
Another change that we will ultimately need is the “scroll” setting: we will need to introduce support for scrolling text down or from left-to-right or right-to-left, e.g. vertical scrolling text seems to be used in some Chinese caption use cases.
2. Unify Rendering Approach
The introduction of regions created a second code path in the rendering spec with some duplication. At FOMS we discussed if it was possible to unify that. The suggestion is to render all cues into a region. Those that are not part of a region would be rendered into an anonymous region that covers the complete viewport. There may be some consequences to this, e.g. cue settings should be usable across all cues, no matter whether or not part of a region, and avoiding cue overlap may need to be done within regions.
Here’s a rough outline of the path of the new rendering algorithm:
Create a cue box and put it in its region (anonymous if none given).
Calculate position & size of cue box from cue settings (position, line, size).
Calculate position of cue text inside cue box from remaining cue settings (vertical, align).
3. Vertical Features
WebVTT includes vertical rendering, both right-to-left and left-to-right. However, regions are not defined for vertical. Eventually, we’re going to have to look at the vertical features of WebVTT with more details and figure out whether the spec is working for them and what real-world requirements we have missed. We hope we can get some help from users in countries where vertically rendered captions/subtitles are the norm.
4. Best Practices
Some of he WebVTT users at FOMS suggested it would be advantageous to start a list of “best practices” for how to author captions with WebVTT. Example recommendations are:
Use line numbers only to position cues from top or bottom of viewport. Don’t use otherwise.
Note that when the user increases the fontsize in rollup captions and thus introduces new line breaks, your cues will roll by faster because the number of lines of a rollup is fixed.
Make sure to use and UTF-8 markers to control the directionality of your text.
It would be nice if somebody started such a document.
A common use case for timed data is the use of preview thumbnails on the navigation bar of videos. A native implementation of preview thumbnails would allow crawlers and search engines to have a standardised way of extracting timed images for media files, so introduction of a new @kind value “thumbnails” was suggested.
The content of a “thumbnails” cue could be any of:
an image URL
a sprite URL to a single image
a spatial & temporal media fragment URL to a media resource
base64 encoded image (data URI)
an iframe offset to the media resource
The suggestion is to allow anything that would work in a img @src attribute as value in a cue of @kind=“thumbnails”. Responsive images might also be useful for a track of @kind=“thumbnails”. It may even be possible to define an inband thumbnail track based on the track of @kind=“thumbnails”. Such cues should also work in the JavaScript track API.
5.2 Chapter markers
There is interest to put richer content than just a chapter title into chapter cues. Often, chapters consist of a title, text and and image. The text is not so important, but the image is used almost everywhere that chapters are used. There may be a need to extend chapter cue content with images, similar to what a @kind=“thumbnails” track offers.
The conclusion that we arrived at was that we need to make @kind=“thumbnails” work first and then look at using the learnings from that to extend @kind=“chapters”.
5.3 Inband tracks for live video
A difficult topic was opened with the question of how to transport text tracks in live video. In live captioning, end times are never created for cues, but are implied by the start time of the next cue. This is a use case that hasn’t been addressed in HTML5/WebVTT yet. An old proposal to allow a special end time value of “NEXT” was discussed and recommended for adoption. Also, there was support for the spec change that stops blocking loading VTT until all cues have been loaded.
5.4 Cross-domain VTT loading
A brief discussion centered around the fact that the spec disallows cross-domain loading of WebVTT files, but that no browser implements this. This needs to be discussion at the HTML WG level.
6. Regions in live captioning
The final topic that we discussed was how we could provide support for regions in live captioning.
The currently active region definitions will need to be come part of every header of every VTT file segment that HLS uses, so it’s available in case the cues in the segment file reference it.
“NEXT” in end time markers would make authoring of live captioned VTT files easier.
If the application wants to use 1 word at a time and doesn’t want to delay sending the word until the full cue is authored (e.g. in a Hangout type environment), we will need to introduce the concept of “cue continuation markers”, so we know that a cue could be extended with the next VTT file fragment.
This is an extensive and impressive amount of discussion around WebVTT and a lot of new work to be performed in the future. I’m very grateful for all the people who have contributed to these discussions at FOMS and will hopefully continue to help get the specifications right.
How did that happen, you may ask, in particular since WebVTT and TTML have in the past been portrayed as rival caption formats? How will the WebVTT spec that is currently under development in the Text Track Community Group (TT-CG) move through a Working Group process?
I’ll explain first why there is a need for WebVTT to become a W3C Recommendation, and then how this is proposed to be part of the Timed Text Working Group deliverables, and finally how I can see this working between the TT-CG and the TT-WG.
Advantages of a W3C Recommendation
TTML is a XML-based markup format for captions developed during the time that XML was all the hotness. It has become a W3C standard (a so-called “Recommendation”) despite not having been implemented in any browsers (if you ask me: that’s actually a flaw of the W3C standardisation process: it requires only two interoperable implementations of any kind – and that could be anyone’s JavaScript library or Flash demonstrator – it doesn’t actually require browser implementations. But I digress…). To be fair, a subpart of TTML is by now implemented in Internet Explorer, but all the other major browsers have thus far rejected proposals of implementation.
Because of its Recommendation status, TTML has become the basis for several other caption standards that other SDOs have picked: the SMPTE’s SMPTE-TT format, the EBU’s EBU-TT format, and the DASH Industry Forum’s use of SMPTE-TT. SMPTE-TT has also become the “safe harbour” format for the US legislation on captioning as decided by the FCC. (Note that the FCC requirements for captions on the Web are actually based on a list of features rather than requiring a specific format. But that will be the topic of a different blog post…)
WebVTT is much younger than TTML. TTML was developed as an interchange format among caption authoring systems. WebVTT was built for rendering in Web browsers and with HTML5 in mind. It meets the requirements of the
As we can see and as has been proven by the HTML spec and multiple other specs: browsers don’t wait for specifications to have W3C Recommendation status before they implement them. Nor do they really care about the status of a spec – what they care about is whether a spec makes sense for the Web developer and user communities and whether it fits in the Web platform. WebVTT has obviously achieved this status, even with an evolving spec. (Note that the spec tries very hard not to break backwards compatibility, thus all past implementations will at least be compatible with the more basic features of the spec.)
Given that Web browsers don’t need WebVTT to become a W3C standard, why then should we spend effort in moving the spec through the W3C process to become a W3C Recommendation?
The modern Web is now much bigger than just Web browsers. Web specifications are being used in all kinds of devices including TV set-top boxes, phone and tablet apps, and even unexpected devices such as white goods. Videos are increasingly omnipresent thus exposing deaf and hard-of-hearing users to ever-growing challenges in interacting with content on diverse devices. Some of these devices will not use auto-updating software but fixed versions so can’t easily adapt to new features. Thus, caption producers (both commercial and community) need to be able to author captions (and other video accessibility content as defined by the HTML5 element) towards a feature set that is clearly defined to be supported by such non-updating devices.
Understandably, device vendors in this space have a need to build their technology on standardised specifications. SDOs for such device technologies like to reference fixed specifications so the feature set is not continually updating. To reference WebVTT, they could use a snapshot of the specification at any time and reference that, but that’s not how SDOs work. They prefer referencing an officially sanctioned and tested version of a specification – for a W3C specification that means creating a W3C Recommendation of the WebVTT spec.
Taking WebVTT on a W3C recommendation track is actually advantageous for browsers, too, because a test suite will have to be developed that proves that features are implemented in an interoperable manner. In summary, I can see the advantages and personally support the effort to take WebVTT through to a W3C Recommendation.
Choice of Working Group
FAIK this is the first time that a specification developed in a Community Group is being moved into the recommendation track. This is something that has been expected when the W3C created CGs, but not something that has an established process yet.
The first question of course is which WG would take it through to Recommendation? Would we create a new Working Group or find an existing one to move the specification through? Since WGs involve a lot of overhead, the preference was to add WebVTT to the charter of an existing WG. The two obvious candidates were the HTML WG and the TT-WG – the first because it’s where WebVTT originated and the latter because it’s the closest thematically.
Adding a deliverable to a WG is a major undertaking. The TT-WG is currently in the process of re-chartering and thus a suggestion was made to add WebVTT to the milestones of this WG. TBH that was not my first choice. Since I’m already an editor in the HTML WG and WebVTT is very closely related to HTML and can be tested extensively as part of HTML, I preferred the HTML WG. However, adding WebVTT to the TT-WG has some advantages, too.
Since TTML is an exchange format, lots of captions that will be created (at least professionally) will be in TTML and TTML-related formats. It makes sense to create a mapping from TTML to WebVTT for rendering in browsers. The expertise of both, TTML and WebVTT experts is required to develop a good mapping – as has been shown when we developed the mapping from CEA608/708 to WebVTT. Also, captioning experts are already in the TT-WG, so it helps to get a second set of eyes onto WebVTT.
A disadvantage of moving a specification out of a CG into a WG is, however, that you potentially lose a lot of the expertise that is already involved in the development of the spec. People don’t easily re-subscribe to additional mailing lists or want the additional complexity of involving another community (see e.g. this email).
So, a good process needs to be developed to allow everyone to contribute to the spec in the best way possible without requiring duplicate work. How can we do that?
The forthcoming process
At TPAC the TT-WG discussed for several hours what the next steps are in taking WebVTT through the TT-WG to recommendation status (agenda with slides). I won’t bore you with the different views – if you are keen, you can read the minutes.
What I came away with is the following process:
Fix a few more bugs in the CG until we’re happy with the feature set in the CG. This should match the feature set that we realistically expect devices to implement for a first version of the WebVTT spec.
Make a FSA (Final Specification Agreement) in the CG to create a stable reference and a clean IPR position.
Assuming that the TT-WG’s charter has been approved with WebVTT as a milestone, we would next bring the FSA specification into the TT-WG as FPWD (First Public Working Draft) and immediately do a Last Call which effectively freezes the feature set (this is possible because there has already been wide community review of the WebVTT spec); in parallel, the CG can continue to develop the next version of the WebVTT spec with new features (just like it is happening with the HTML5 and HTML5.1 specifications).
Develop a test suite and address any issues in the Last Call document (of course, also fix these issues in the CG version of the spec).
As per W3C process, substantive and minor changes to Last Call documents have to be reported and raised issues addressed before the spec can progress to the next level: Candidate Recommendation status.
For the next step - Proposed Recommendation status - an implementation report is necessary, and thus the test suite needs to be finalized for the given feature set. The feature set may also be reduced at this stage to just the ones implemented interoperably, leaving any other features for the next version of the spec.
The final step is Recommendation status, which simply requires sufficient support and endorsement by W3C members.
The first version of the WebVTT spec naturally has a focus on captioning (and subtitling), since this has been the dominant use case that we have focused on this far and it’s the part that is the most compatibly implemented feature set of WebVTT in browsers. It’s my expectation that the next version of WebVTT will have a lot more features related to audio descriptions, chapters and metadata. Thus, this seems a good time for a first version feature freeze.
There are still several obstacles towards progressing WebVTT as a milestone of the TT-WG. Apart from the need to get buy-in from the TT-WG, the TT-CG, and the AC (Adivisory Committee who have to approve the new charter), we’re also looking at the license of the specification document.
The CG specification has an open license that allows creating derivative work as long as there is attribution, while the W3C document license for documents on the recommendation track does not allow the creation of derivative work unless given explicit exceptions. This is an issue that is currently being discussed in the W3C with a proposal for a CC-BY license on the Recommendation track. However, my view is that it’s probably ok to use the different document licenses: the TT-WG will work on WebVTT 1.0 and give it a W3C document license, while the CG starts working on the next WebVTT version under the open CG license. It probably actually makes sense to have a less open license on a frozen spec.
Making the best of a complicated world
WebVTT is now proposed as part of the recharter of the TT-WG. I have no idea how complicated the process will become to achieve a W3C WebVTT 1.0 Recommendation, but I am hoping that what is outlined above will be workable in such a way that all of us get to focus on progressing the technology.
At TPAC I got the impression that the TT-WG is committed to progressing WebVTT to Recommendation status. I know that the TT-CG is committed to continue developing WebVTT to its full potential for all kinds of media-time aligned content with new kinds already discussed at FOMS. Let’s enable both groups to achieve their goals. As a consequence, we will allow the two formats to excel where they do: TTML as an interchange format and WebVTT as a browser rendering format.
I finished up at Google last week and am now working at NICTA, an Australian ICT research institute.
My work with Google was exciting and I learned a lot. I like to think that Google also got a lot out of me - I coded and contributed to some YouTube caption features, I worked on Chrome captions and video controls, and above all I worked on video accessibility for HTML at the W3C.
I was one of the key authors of the W3C Media Accessibility Requirements document that we created in the Media Accessibility Task Force of the W3C HTML WG. I then went on to help make video accessibility a reality. We created WebVTT and the and applied it to captions, subtitles, chapters (navigation), video descriptions, and metadata. To satisfy the need for synchronisation of video with other media resources such as sign language video or audio descriptions, we got the MediaController object and the @mediagroup attribute.
I must say it was a most rewarding time. I learned a lot about being productive at Google, collaborate successfully over the distance, about how the WebKit community works, and about the new way of writing W3C standard (which is more like pseudo-code). As one consequence, I am now a co-editor of the W3C HTML spec and it seems I am also about to become the editor of the WebVTT spec.
At NICTA my new focus of work is WebRTC. There is both a bit of research and a whole bunch of application development involved. I may even get to do some WebKit development, if we identify any issues with the current implementation. I started a week ago and am already amazed by the amount of work going on in the WebRTC space and the amazing number of open source projects playing around with it. Video conferencing is a new challenge and I look forward to it.
I decided to use socket.io for the signalling following the idea of Luc, which made the server code even smaller and reduced it to a mere reflector:
var app = require('http').createServer().listen(1337); var io = require('socket.io').listen(app); io.sockets.on('connection', function(socket) { socket.on('message', function(message) { socket.broadcast.emit('message', message); }); });
Then I turned to the client code. I was surprised to see the massive changes that PeerConnection has gone through. Check out my slide deck to see the different components that are now necessary to create a PeerConnection.
I was particularly surprised to see the SDP object now fully exposed to JavaScript and thus the ability to manipulate it directly rather than through some API. This allows Web developers to manipulate the type of session that they are asking the browsers to set up. I can imaging e.g. if they have support for a video codec in JavaScript that the browser does not provide built-in, they can add that codec to the set of choices to be offered to the peer. While it is flexible, I am concerned if this might create more problems than it solves. I guess we’ll have to wait and see.
I was also surprised by the need to use ICE, even though in my experiment I got away with an empty list of ICE servers - the ICE messages just got exchanged through the socket.io server. I am not sure whether this is a bug, but I was very happy about it because it meant I could run the whole demo on a completely separate network from the Internet.
The most exciting news since my talk is that Mozilla and Google have managed to get a PeerConnection working between Firefox and Chrome - this is the first cross-browser video conference call without a plugin! The code differences are minor.
Since the specification of the WebRTC API and of the MediaStream API are now official Working Drafts at the W3C, I expect other browsers will follow. I am also looking forward to the possibilities of:
multi-peer video conferencing like the efforts around webrtc.io,
The best places to learn about the latest possibilities of WebRTC are webrtc.org and the W3C WebRTC WG. code.google.com has open source code that continues to be updated to the latest released and interoperable features in browsers.
The video of my talk is in the process of being published. There is a MP4 version on the Linux Australia mirror server, but I expect it will be published properly soon. I will update the blog post when that happens.
The W3C HTML WG and the WHATWG are currently discussing the introduction of a
element into HTML.
The
element has been proposed by Steve Faulkner and is specified in a draft extension spec which is about to be accepted as a FPWD (first public working draft) by the W3C HTML WG. This implies that the W3C HTML WG will be looking for implementations and for feedback by implementers on this spec.
I am supportive of the introduction of a
element into HTML. However, I believe that the current spec and use case list don’t make a good enough case for its introduction. Here are my thoughts.
Main use case: accessibility
In my opinion, the main use case for the introduction of
is accessibility.
Like any other users, when blind users want to perceive a Web page/application, they need to have a quick means of grasping the content of a page. Since they cannot visually scan the layout and thus determine where the main content is, they use accessibility technology (AT) to find what is known as “landmarks”.
“Landmarks” tell the user what semantic content is on a page: a header (such as a banner), a search box, a navigation menu, some asides (also called complementary content), a footer, … and the most important part: the main content of the page. It is this main content that a blind user most often wants to skip to directly.
In the days of HTML4, a hidden “skip to content” link at the beginning of the Web page was used as a means to help blind users access the main content.
In the days of ARIA, the aria @role=main enables authors to avoid a hidden link and instead mark the element where the main content begins to allow direct access to the main content. This attribute is supported by AT - in particular screen readers - by making it part of the landmarks that AT can directly skip to.
Both the hidden link and the ARIA @role=main approaches are, however, band aids: they are being used by those of us that make “finished” Web pages accessible by adding specific extra markup.
A world where ARIA is not necessary and where accessibility developers would be out of a job because the normal markup that everyone writes already creates accessible Web sites/applications would be much preferable over the current world of band-aids.
Therefore, to me, the primary use case for a
element is to achieve exactly this better world and not require specialized markup to tell a user (or a tool) where the main content on a page starts.
An immediate effect would be that pages that have a
element will expose a “main” landmark to blind and vision-impaired users that will enable them to directly access that main content on the page without having to wade through other text on the page. Without a element, this functionality can currently only be provided using heuristics to skip other semantic and structural elements and is for this reason not typically implemented in AT.
Other use cases
The
element is a semantic element not unlike other new semantic elements such as ,
TTML has been specified by the W3C Timed Text Working Group and released as a RECommendation v1.0 in November 2010. Since then, several organisations have tried to adopt it as their caption file format. This includes the SMPTE, the EBU (European Broadcasting Union), and Microsoft.
Both, Microsoft and the EBU actually looked at TTML in detail and decided that in order to make it usable for their use cases, a restriction of its functionalities is needed.
EBU-TT
The EBU released EBU-TT, which restricts the set of valid attributes and feature. “The EBU-TT format is intended to constrain the features provided by TTML, especially to make EBU-TT more suitable for the use with broadcast video and web video applications.” (see EBU-TT).
In addition, EBU-specific namespaces were introduce to extend TTML with EBU-specific data types, e.g. ebuttdt:frameRateMultiplierType or ebuttdt:smpteTimingType. Similarly, a bunch of metadata elements were introduced, e.g. ebuttm:documentMetadata, ebuttm:documentEbuttVersion, or ebuttm:documentIdentifier.
The use of namespaces as an extensibility mechanism will ascertain that EBU-TT files continue to be valid TTML files. However, any vanilla TTML parser will not know what to do with these custom extensions and will drop them on the floor.
Simple Delivery Profile
With the intention to make TTML ready for “internet delivery of Captions originated in the United States”, Microsoft proposed a “Simple Delivery Profile for Closed Captions (US)” (see Simple Profile). The Simple Profile is also a restriction of TTML.
Unfortunately, the Microsoft profile is not the same as the EBU-TT profile: for example, it contains the “set” element, which is not conformant in EBU-TT. Similarly, the supported style features are different, e.g. Simple Profile supports “display-region”, while EBU-TT does not. On the other hand, EBU-TT supports monospace, sans-serif and serif fonts, while the Simple profile does not.
Thus files created for the Simple Delivery Profile will not work on players that expect EBU-TT and the reverse.
Fortunately, the Simple Delivery Profile does not introduce any new namespaces and new features, so at least it is an explicit subpart of TTML and not both a restriction and extension like EBU-TT.
SMPTE-TT
SMPTE also created a version of the TTML standard called SMPTE-TT. SMPTE did not decide on a subset of TTML for their purposes - it was simply adopted as a complete set. “This Standard provides a framework for timed text to be supported for content delivered via broadband means,…” (see SMPTE-TT).
However, SMPTE extended TTML in SMPTE-TT with an ability to store a binary blob with captions in another format. This allows using SMPTE-TT as a transport format for any caption format and is deemed to help with “backwards compatibility”.
Now, instead of specifying a profile, SMPTE decided to define how to convert CEA-608 captions to SMPTE-TT. Even if it’s not called a “profile”, that’s actually what it is. It even has its own namespace: “m608:”.
Conclusion
With all these different versions of TTML, I ask myself what a video player that claims support for TTML will do to get something working. The only chance it has is to implement all the extensions defined in all the different profiles. I pity the player that has to deal with a SMPTE-TT file that has a binary blob in it and is expected to be able to decode this.
Now, what is a caption author supposed to do when creating TTML? They obviously cannot expect all players to be able to play back all TTML versions. Should they create different files depending on what platform they are targeting, i.e. a EBU-TT version, a SMPTE-TT version, a vanilla TTML version, and a Simple Delivery Profile version? Should they by throwing all the features of all the versions into one TTML file and hope that the players will pick out the right things that they require and drop the rest on the floor?
Maybe the best way to progress would be to make a list of the “safe” features: those features that every TTML profile supports. That may be the best way to get an “interoperable TTML” file. Here’s me hoping that this minimal set of features doesn’t just end up being the usual (starttime, endtime, text) triple.
UPDATE:
I just found out that UltraViolet have their own profile of SMPTE-TT called CFF-TT (see UltraViolet FAQ and spec). They are making some SMPTE-TT fields optional, but introduce a new @forcedDisplayMode attribute under their own namespace “cff:”.
In my probably somewhat subjective view, recommendation level means that a snapshot is taken of the continuously evolving HTML spec, which has a comprehensive feature set, that is implemented in a cross-browser interoperable way, has a complete test set for the features, and has received wide review. The latter implies that other groups in the W3C have had a chance to look at the specification and make sure it satisfies their basic requirements, which include e.g. applicability to all users (accessibility, internationalization), platforms, and devices (mobile, TV).
Basically it means that we stop for a “moment”, take a deep breath, polish the feature set that we’ve been working on this far, and make sure we all agree on it, before we get back to changing the world with cool new stuff. In a software project we would call it a release branch with feature freeze.
Now, as productive as that may sound for software - it’s not actually that exciting for a specification. Firstly, the most exciting things happen when writing new features. Secondly, development of browsers doesn’t just magically stop to get the release (REC) happening. And lastly, if we’ve done our specification work well, there should be only little work to do. Basically, it’s the unthankful work of tidying up that we’re looking at here. :-)
So, why am I doing it? I am not doing this for money - I’m currently part-time contracting to Google’s accessibility team working on video accessibility and this editor work is not covered by my contract. It wasn’t possible to reconcile polishing work on a specification with the goals of my contract, which include pushing new accessibility features forward. Therefore, when invited, I decided to offer my spare time to the W3C.
I’m giving this time under the condition that I’d only be looking at accessibility and video related sections. This is where my interest and expertise lie, and where I’m passionate to get things right. I want to make sure that we create accessibility features that will be implemented and that we polish existing video features. I want to make sure we don’t digress from implementations which continue to get updated and may follow the WHATWG spec or HTML.next or other needs.
I am not yet completely sure what the editorship will entail. Will we look at tests, too? Will we get involved in HTML.next? This far we’ve been preparing for our work by setting up adequate version control repositories, building a spec creation process, discussing how to bridge to the WHATWG commits, and analysing the long list of bugs to see how to cope with them. There’s plenty of actual text editing work ahead and the team is shaping up well! I look forward to the new experiences.
A bit over a week ago I gave a presentation at Web Directions Code 2012 in Melbourne. Maxine and John asked me to speak about something related to HTML5 video, so I went for the new shiny: WebRTC - real-time communication in the browser.
I only had 20 min, so I had to make it tight. I wanted to show off video conferencing without special plugins in Google Chrome in just a few lines of code, as is the promise of WebRTC. To a large extent, I achieved this. But I made some interesting discoveries along the way. Demos are in the slide deck.
UPDATE: Opera 12 has been released with WebRTC support.
Housekeeping: if you want to replicate what I have done, you need to install a Google Chrome Web Browser 19+. Then make sure you go to chrome://flags and activate the MediaStream and PeerConnection experiment(s). Restart your browser and now you can experiment with this feature. Big warning up-front: it’s not production-ready, since there are still changes happening to the spec and there is no compatible implementation by another browser yet.
Here is a brief summary of the steps involved to set up video conferencing in your browser:
Set up a video element each for the local and the remote video stream.
Grab the local camera and stream it to the first video element.
(*) Establish a connection to another person running the same Web page.
Send the local camera stream on that peer connection.
Accept the remote camera stream into the second video element.
Now, the most difficult part of all of this - believe it or not - is the signalling part that is required to build the peer connection (marked with (*)). Initially I wanted to run completely without a server and just enter the remote’s IP address to establish the connection. This is, however, not a functionality that the PeerConnection object provides [might this be something to add to the spec?].
So, you need a server known to both parties that can provide for the handshake to set up the connection. All the examples that I have seen, such as https://apprtc.appspot.com/, use a channel management server on Google’s appengine. I wanted it all working with HTML5 technology, so I decided to use a Web Socket server instead.
I implemented my Web Socket server using node.js (code of websocket server). The video conferencing demo is in the slide deck in an iframe - you can also use the stand-alone html page. Works like a treat.
While it is still using Google’s STUN server to get through NAT, the messaging for setting up the connection is running completely through the Web Socket server. The messages that get exchanged are plain SDP message packets with a session ID. There are OFFER, ANSWER, and OK packets exchanged for each streaming direction. You can see some of it in the below image:
I’m not running a public WebSocket server, so you won’t be able to see this part of the presentation working. But the local loopback video should work.
At the conference, it all went without a hitch (while the wireless played along). I believe you have to host the WebSocket server on the same machine as the Web page, otherwise it won’t work for security reasons.
A whole new world of opportunities lies out there when we get the ability to set up video conferencing on every Web page - scary and exciting at the same time!
With the latest developments in HTML5 and the still fairly new ARIA (Accessible Rich Interface Applications) attributes introduced by the W3C WAI (Web Accessibility Initiative), browsers have now implemented many features that allow you to make your JavaScript-heavy Web applications accessible.
Since I began working on making a complex web application accessible just over a year ago, I discovered that there was no step-by-step guide to approaching the changes necessary for creating an accessible Web application. Therefore, many people believe that it is still hard, if not impossible, to make Web applications accessible. In fact, it can be approached systematically, as this article will describe.
This post is based on a talk that Alice Boxhall and I gave at the recent Linux.conf.au titled “Developing accessible Web apps – how hard can it be?” (slides, video), which in turn was based on a Google Developer Day talk by Rachel Shearer (slides).
These talks, and this article, introduce a process that you can follow to make your Web applications accessible: each step will take you closer to having an application that can be accessed using a keyboard alone, and by users of screenreaders and other accessibility technology (AT).
The recommendations here only roughly conform to the requirements of WCAG (Web Content Accessibility Guidelines), which is the basis of legal accessibility requirements in many jurisdictions. The steps in this article may or may not be sufficient to meet a legal requirement. It is focused on the practical outcome of ensuring users with disabilities can use your Web application.
Step-by-step Approach
The steps to follow to make your Web apps accessible are as follows:
Use native HTML tags wherever possible
Make interactive elements keyboard accessible
Provide extra markup for AT (accessibility technology)
If you are a total newcomer to accessibility, I highly recommend installing a screenreader and just trying to read/navigate some Web pages. On Windows you can install the free NVDA screenreader, on Mac you can activate the pre-installed VoiceOver screenreader, on Linux you can use Orca, and if you just want a browser plugin for Chrome try installing ChromeVox.
1. Use native HTML tags
As you implement your Web application with interactive controls, try to use as many native HTML tags as possible.
HTML5 provides a rich set of elements which can be used to both add functionality and provide semantic context to your page. HTML4 already included many useful interactive controls, like ,
I spoke about the video and audio element in HTML5, how to provide fallback content, how to encode content, how to control them from JavaScript, and briefly about Drupal video modules, though the next presentation provided much more insight into those. I explained how to make the HTML5 media elements accessible, including accessible controls, captions, audio descriptions, and the new WebVTT file format. I ran out of time to introduce the last section of my slides which are on WebRTC.
Linux.conf.au
On the first day of LCA I gave a talk both in the Multimedia Miniconf and the Browser Miniconf.
Browser Miniconf
In the Browser Miniconf I talked about “Web Standardisation – how browser vendors collaborate, or not” (slides). Maybe the most interesting part about this was that I tried out a new slide “deck” tool called impress.js. I’m not yet sure if I like it but it worked well for this talk, in which I explained how the HTML5 spec is authored and who has input.
I also sat on a panel of browser developers in the Browser Miniconf (more as a standards than as a browser developer, but that’s close enough). We were asked about all kinds of latest developments in HTML5, CSS3, and media standards in the browser.
Multimedia Miniconf
In the Multimedia Miniconf I gave a “HTML5 media accessibility update” (slides). I talked about the accessibility problems of Flash, how native HTML5 video players will be better, about accessible video controls, captions, navigation chapters, audio descriptions, and WebVTT. I also provided a demo of how to synchronize multiple video elements using a polyfill for the multitrack API.
Finally, and most importantly, Alice Boxhall and myself gave a talk in the main linux.conf.au titled “Developing Accessible Web Apps - how hard can it be?” (video, slides). I spoke about a process that you can follow to make your Web applications accessible. I’m writing a separate blog post to explain this in more detail. In her part, Alice dug below the surface of browsers to explain how the accessibility markup that Web developers provide is transformed into data structures that are handed to accessibility technologies.
The Open Video Conference that took place on 10-12 September was so overwhelming, I’ve still not been able to catch my breath! It was a dense three days for me, even though I only focused on the technology sessions of the conference and utterly missed out on all the policy and content discussions.
Roughly 60 people participated in the Open Media Software (OMS) developers track. This was an amazing group of people capable and willing to shape the future of video technology on the Web:
HTML5 video developers from Apple, Google, Opera, and Mozilla (though we missed the NZ folks),
codec developers from WebM, Xiph, and MPEG,
Web video developers from YouTube, JWPlayer, Kaltura, VideoJS, PopcornJS, etc.,
content publishers from Wikipedia, Internet Archive, YouTube, Netflix, etc.,
open source tool developers from FFmpeg, gstreamer, flumotion, VideoLAN, PiTiVi, etc,
and many more.
To provide a summary of all the discussions would be impossible, so I just want to share the key take-aways that I had from the main sessions.
Tim Terriberry (Mozilla), Serge Lachapelle (Google) and Ethan Hugg (CISCO) moderated this session together (slides). There are activities both at the W3C and at IETF - the ones at IETF are supposed to focus on protocols, while the W3C ones on HTML5 extensions.
The current proposal of a PeerConnection API has been implemented in WebKit/Chrome as open source. It is expected that Firefox will have an add-on by Q1 next year. It enables video conferencing, including media capture, media encoding, signal processing (echo cancellation etc), secure transmission, and a data stream exchange.
Current discussions are around the signalling protocol and whether SIP needs to be required by the standard. Further, the codec question is under discussion with a question whether to mandate VP8 and Opus, since transcoding gateways are not desirable. Another question is how to measure the quality of the connection and how to report errors so as to allow adaptation.
What always amazes me around RTC is the sheer number of specialised protocols that seem to be required to implement this. WebRTC does not disappoint: in fact, the question was asked whether there could be a lighter alternative than to re-use dozens of years of protocol development - is it over-engineered? Can desktop players connect to a WebRTC session?
We are already in a second or third revision of this part of the HTML5 specification and yet it seems the requirements are still being collected. I’m quietly confident that everything is done to make the lives of the Web developer easier, but it sure looks like a huge task.
Zohar Babin (Kaltura) and myself moderated this session and I must admit that this session was the biggest eye-opener for me amongst all the sessions. There was a large number of Flash developers present in the room and that was great, because sometimes we just don’t listen enough to lessons learnt in the past.
This session gave me one of those aha-moments: it the form of the Flash appendBytes() API function.
The appendBytes() function allows a Flash developer to take a byteArray out of a connected video resource and do something with it - such as feed it to a video for display. When I heard that Web developers want that functionality for JavaScript and the video element, too, I instinctively rejected the idea wondering why on earth would a Web developer want to touch encoded video bytes - why not leave that to the browser.
But as it turns out, this is actually a really powerful enabler of functionality. For example, you can use it to:
display mid-roll video ads as part of the same video element,
sequence playlists of videos into the same video element,
implement DVR functionality (high-speed seeking),
do mash-ups,
do video editing,
adaptive streaming.
This totally blew my mind and I am now completely supportive of having such a function in HTML5. Together with media fragment URIs you could even leave all the header download management for resources to the Web browser and just request time ranges from a video through an appendBytes() function. This would be easier on the Web developer than having to deal with byte ranges and making sure that appropriate decoding pipelines are set up.
Philip Jagenstedt (Opera) and myself moderated this session. We focused on the HTML5 track element and the WebVTT file format. Many issues were identified that will still require work.
One particular topic was to find a standard means of rendering the UI for caption, subtitle, und description selection. For example, what icons should be used to indicate that subtitles or captions are available. While this is not part of the HTML5 specification, it’s still important to get this right across browsers since otherwise users will get confused with diverging interfaces.
Chaptering was discussed and a particular need to allow URLs to directly point at chapters was expressed. I suggested the use of named Media Fragment URLs.
The use of WebVTT for descriptions for the blind was also discussed. A suggestion was made to use the voice tag to allow for “styling” (i.e. selection) of the screen reader voice.
Finally, multitrack audio or video resources were also discussed and the @mediagroup attribute was explained. A question about how to identify the language used in different alternative dubs was asked. This is an issue because @srclang is not on audio or video, only on text, so it’s a missing feature for the multitrack API.
Beyond this session, there was also a breakout session on WebVTT and the track element. As a consequence, a number of bugs were registered in the W3C bug tracker.
This session was moderated by John Luther and John Koleszar, both of the WebM Project. They started off with a presentation on current work on WebM, which includes quality testing and improvements, and encoder speed improvement. Then they moved on to questions about how to involve the community more.
The community criticised that communication of what is happening around WebM is very scarce. More sharing of information was requested, including a move to using open Google+ hangouts instead of Google internal video conferences. More use of the public bug tracker can also help include the community better.
Another pain point of the community was that code is introduced and removed without much feedback. It was requested to introduce a peer review process. Also it was requested that example code snippets are published when new features are announced so others can replicate the claims.
This all indicates to me that the WebM project is increasingly more open, but that there is still a lot to learn.
This session was moderated by Frank Galligan and Aaron Colwell (Google), and Mark Watson (Netflix).
Mark started off by giving us an introduction to MPEG DASH, the MPEG file format for HTTP adaptive streaming. MPEG has just finalized the format and he was able to show us some examples. DASH is XML-based and thus rather verbose. It is covering all eventualities of what parameters could be switched during transmissions, which makes it very broad. These include trick modes e.g. for fast forwarding, 3D, multi-view and multitrack content.
MPEG have defined profiles - one for live streaming which requires chunking of the files on the server, and one for on-demand which requires keyframe alignment of the files. There are clear specifications for how to do these with MPEG. Such profiles would need to be created for WebM and Ogg Theora, too, to make DASH universally applicable.
Further, the Web case needs a more restrictive adaptation approach, since the video element’s API is already accounting for some of the features that DASH provides for desktop applications. So, a Web-specific profile of DASH would be required.
Then Aaron introduced us to the MediaSource API and in particular the webkitSourceAppend() extension that he has been experimenting with. It is essentially an implementation of the appendBytes() function of Flash, which the Web developers had been asking for just a few sessions earlier. This was likely the biggest announcement of OVC, alas a quiet and technically-focused one.
Aaron explained that he had been trying to find a way to implement HTTP adaptive streaming into WebKit in a way in which it could be standardised. While doing so, he also came across other requirements around such chunked video handling, in particular around dynamic ad insertion, live streaming, DVR functionality (fast forward), constraint video editing, and mashups. While trying to sort out all these requirements, it became clear that it would be very difficult to implement strategies for stream switching, buffering and delivery of video chunks into the browser when so many different and likely contradictory requirements exist. Also, once an approach is implemented and specified for the browser, it becomes very difficult to innovate on it.
Instead, the easiest way to solve it right now and learn about what would be necessary to implement into the browser would be to actually allow Web developers to queue up a chunk of encoded video into a video element for decoding and display. Thus, the webkitSourceAppend() function was born (specification).
The proposed extension to the HTMLMediaElement is as follows:
partial interface HTMLMediaElement { // URL passed to src attribute to enable the media source logic. readonly attribute [URL] DOMString webkitMediaSourceURL; bool webkitSourceAppend(in Uint8Array data); // end of stream status codes. const unsigned short EOS_NO_ERROR = 0; const unsigned short EOS_NETWORK_ERR = 1; const unsigned short EOS_DECODE_ERR = 2; void webkitSourceEndOfStream(in unsigned short status); // states const unsigned short SOURCE_CLOSED = 0; const unsigned short SOURCE_OPEN = 1; const unsigned short SOURCE_ENDED = 2; readonly attribute unsigned short webkitSourceState;};
The code is already checked into WebKit, but commented out behind a command-line compiler flag.
Frank then stepped forward to show how webkitSourceAppend() can be used to implement HTTP adaptive streaming. His example uses WebM - there are no examples with MPEG or Ogg yet.
The chunks that Frank’s demo used were 150 video frames long (6.25s) and 5s long audio. Stream switching only switched video, since audio data is much lower bandwidth and more important to retain at high quality. Switching was done on multiplexed files.
Every chunk requires an XHR range request - this could be optimised if the connections were kept open per adaptation. Seeking works, too, but since decoding requires download of a whole chunk, seeking latency is determined by the time it takes to download and decode that chunk.
Similar to DASH, when using this approach for live streaming, the server has to produce one file per chunk, since byte range requests are not possible on a continuously growing file.
Frank did not use DASH as the manifest format for his HTTP adaptive streaming demo, but instead used a hacked-up custom XML format. It would be possible to use JSON or any other format, too.
After this session, I was actually completely blown away by the possibilities that such a simple API extension allows. If I wasn’t sold on the idea of a appendBytes() function in the earlier session, this one completely changed my mind. While I still believe we need to standardise a HTTP adaptive streaming file format that all browsers will support for all codecs, and I still believe that a native implementation for support of such a file format is necessary, I also believe that this approach of webkitSourceAppend() is what HTML needs - and maybe it needs it faster than native HTTP adaptive streaming support.
This session was moderated by Zachary Ozer and Pablo Schklowsky (JWPlayer). Their motivation for the topic was, in fact, also HTTP adaptive streaming. Once you leave the decisions about when to do stream switching to JavaScript (through a function such a wekitSourceAppend()), you have to expose stream metrics to the JS developer so they can make informed decisions. The other use cases is, of course, monitoring of the quality of video delivery for reporting to the provider, who may then decide to change their delivery environment.
The discussion found that we really care about metrics on three different levels:
measuring the network performance (bandwidth)
measuring the decoding pipeline performance
measuring the display quality
In the end, it seemed that work previously done by Steve Lacey on a proposal for video metrics was generally acceptable, except for the playbackJitter metric, which may be too aggregate to mean much.
I didn’t actually attend this session held by Anant Narayanan (Mozilla), but from what I heard, the discussion focused on how to manage permission of access to video camera, microphone and screen, e.g. when multiple applications (tabs) want access or when the same site wants access in a different session. This may apply to real-time communication with screen sharing, but also to photo sharing, video upload, or canvas access to devices e.g. for time lapse photography.
This was another session that I wasn’t able to attend, but I believe the creation of good open source video editing software and similar video creation software is really crucial to giving video a broader user appeal.
Jeff Fortin (PiTiVi) moderated this session and I was fascinated to later see his analysis of the lifecycle of open source video editors. It is shocking to see how many people/projects have tried to create an open source video editor and how many have stopped their project. It is likely that the creation of a video editor is such a complex challenge that it requires a larger and more committed open source project - single people will just run out of steam too quickly. This may be comparable to the creation of a Web browser (see the size of the Mozilla project) or a text processing system (see the size of the OpenOffice project).
Jeff also mentioned the need to create open video editor standards around playlist file formats etc. Possibly the Open Video Alliance could help. In any case, something has to be done in this space - maybe this would be a good topic to focus next year’s OVC on?
Monday’s Breakout Groups
The conference ended officially on Sunday night, but we had a third day of discussions / hackday at the wonderful New York Lawschool venue. We had collected issues of interest during the two previous days and organised the breakout groups on the morning (Schedule).
In the Content Protection/DRM session, Mark Watson from Netflix explained how their API works and that they believe that all we need in browsers is a secure way to exchange keys and an indicator of protection scheme is used - the actual protection scheme would not be implemented by the browser, but be provided by the underlying system (media framework/operating system). I think that until somebody actually implements something in a browser fork and shows how this can be done, we won’t have much progress. In my understanding, we may also need to disable part of the video API for encrypted content, because otherwise you can always e.g. grab frames from the video element into canvas and save them from there.
In the Playlists and Gapless Playback session, there was massive brainstorming about what new cool things can be done with the video element in browsers if playback between snippets can be made seamless. Further discussions were about a standard playlist file formats (such as XSPF, MRSS or M3U), media fragment URIs in playlists for mashups, and the need to expose track metadata for HTML5 media elements.
What more can I say? It was an amazing three days and the complexity of problems that we’re dealing with is a tribute to how far HTML5 and open video has already come and exciting news for the kind of applications that will be possible (both professional and community) once we’ve solved the problems of today. It will be exciting to see what progress we will have made by next year’s conference.
Thanks go to Google for sponsoring my trip to OVC.
The group has been created to work on many aspects of video text tracks of which captioning and the WebVTT format are key parts.
The main reason behind creating this group is to create a forum at the W3C for working on WebVTT to allow all browsers to support this format and be involved in its development.
We’ve not gone the full way to creating a Working Group, although that was the initial intention. We had objections from W3C members for going down that path, so are using the CG path for now.
This is actually a good thing because CGs are open for anyone to join, while WGs are only open to W3C members. The key difference is that specs coming out of WGs can become RECs (“standards”), while CG’s specs cannot.
If we eventually see a need to move WebVTT to a REC, that move will be straight forward, since there is a clear path for work to transition from a CG to a WG.
Curious about any new requirements that the TV community may have for HTML5 video, I attended the W3C Web and TV Workshop in Hollywood last week. It’s already the third of its kind and was also the largest to date showing an increasing interest of the TV community to converge with the Web community.
The Workshop Aim
I went into the Workshop not quite knowing what to expect. My previous contact with members of this community was restricted to email exchanges on the W3C Web and TV Interest Group (IG) mailing list. I knew there was some interest in video accessibility (well: particularly captions) and little knowledge of existing HTML5 specifications around text tracks and why the browsers were going with WebVTT. So I had decided to attend the workshop to get a better understanding of the community, it’s background, needs, and issues, and to hopefully teach some of the ways of HTML5. For that reason I had also submitted a WebVTT presentation/demo.
As it turned out, the workshop had as its key target the facilitation of communication between the TV and the HTML5 community. The aim was to identify features that need to be added to the HTML5 video element to satisfy the needs of the TV community. I obviously came to the right workshop.
The process that is being used by the W3C in the Interest Group is to have TV community members express their needs, then have HTML5 experts express how these needs can be satisfied with existing HTML5 features, then make trial implementations and identify any shortcomings, then move forward to progress these through HTML5 or HTML.next. This workshop clearly focused on the first step: expressing needs.
Often times it was painful for me to watch presenters defending their requirements and trying to impress on the audience how important a certain feature is to them when that features actually already has a HTML5 specification, but just not yet a browser implementations. That there were so few HTML5 video experts present and that they were given very little space to directly reply to the expressed needs and actually explain what is already possible (or specified to be possible) was probably one of the biggest drawbacks of the workshop.
To be fair, detailed technical discussions were not possible in a room with 150 attendees with a panel sitting at the front discussing topics and taking questions. Solving a use case with existing HTML5 markup and identifying the gaps requires smaller break-out groups of a maximum of maybe 20 people and sufficient HTML5 knowledge in the room. Ultimately they require a single person to try to implement it using JavaScript alone, and, failing that, writing browser extensions. Only such code actually proves that a feature is missing.
Now, the video features of HTML5 are still continuing to change almost on a daily basis. Much development is, for example, happening around real-time communication features and around the track element as we speak. So, focusing on further requirements finding around HTML5 video for now is probably a good thing.
The TV Community Approach
Before I move on to some of the topics covered by the workshop, I have to express some concern about the behaviour that I observed with lots of the TV community folks. Many people tried pushing existing solutions from other spaces into the Web unchanged with a claim of not re-inventing the wheel and following paved cowpaths, which are some of the underlying design principles for HTML5. I can understand where such behaviour originates thinking that having solved the same problems elsewhere before, those solutions should apply here, too. But I would like to warn people of this approach.
If we blindly apply solutions that were not developed for HTML5 into HTML we will end up with suboptimal solutions that will hurt us further down the track. The principles of not re-inventing the wheel and following paved cowpaths were introduced for features that were already implemented by browsers or in de-facto standard use by JavaScript libraries. They were not created for new features in HTML. The video element is a completely new feature in HTML thus everything around it is new.
I would therefore like to see some more respect given to HTML5 and the complexities involved in finding the best possible technical solutions for the Web given that the video element does not stand alone in HTML5, but is part of a much larger picture of technical capabilities on the Web where many of the requested features for TV applications may already be solved by existing HTML markup that is not part of the video element.
Also, HTML5 is not just about the HTML markup, but also about CSS and JavaScript and HTTP. There are several layers of technology involved in creating a Web application: not only a separation of work between client and servers, but also between the Operating System, the media framework, the browser, browser plugins, and JavaScript has to be balanced. To get this balance right is a fine art that will take many discussion, many experiments and sometimes several design approaches. We need patience and calm to work through this, not a rushed adoption of existing solutions from other spaces.
Session 1 / Content Provider and Consumer Perspective:
The sessions participants postulate that we will see the creation of application stores for TV applications similar to how we have experienced this for mobile phones and tablets. People enjoy collecting apps like they collect badges. Right now, the app store domain is dominated by native apps and now Web apps. The reason is that we haven’t got a standard platform for setting up Web app stores with Web apps that work in all browsers on all operating systems. Thus, developers have to re-deploy their app for many environments.
While essentially an orthogonal need to HTML standardisation, this seems to be one of the key issues that keep Web apps back from making big market inroads and W3C may do well in setting up a new WG to define a standard Web app manifest format and JS APIs.
Session 2+3 / Multi-screen TV in the Home Network:
Several technologies of hybrid TV broadcast and set-top-box Web content delivery were being pointed out, including the European HbbTV and the Japanese Hybridcast, the latter of which gave an in-depth demo.
Web purists would probably say that it would be simpler to just deliver all content over the Web and not have to worry about any further technical challenges encountered by having to synchronize content received via two vastly different delivery mechanisms. I personally believe this development is one of business models: we don’t yet know exactly how to earn money from TV content delivered over the Internet, but we do know how to do so with TV content. So, hybrids allow the continuation of existing income streams while allowing the features to be augmented with those people enjoy from the Internet.
Should requirements that emerge from such a use case for HTML5 video be taken seriously? I think they absolutely should. What I see happening is that a new way of using the Web is starting to emerge. The new way is video-focused rather than text-focused. We receive our Web content by watching video programming online - video channels, not Web pages are the core content that we consume in the living room. Video channels are where we start our browsing experience from. Search may still be our first point of call, but it will be search for video content or a video-centric app rather than search for a Web site.
And it will be a matter of many interconnected devices in the house that contribute to the experience: the 5.1 stereos that are spread all over the house and should receive our video’s sound, the different screens in the different areas of our house between which we move around, and remote controls, laptops or tablets that function as remote controls and preview stations and are used to determine our viewing experience and provide a back-channel to the publishers.
We have barely begun to identify how such interconnected devices within a home fit within the server-client-based view of the Web world, and the new Web Sockets functionality. The Home Networking Task Force of the Web and TV IG is looking at the issues and analysing existing protocols and standards that solve this picture. But I have a gnawing feeling that the best solution will be something new that is more Web-specific and fits better with the technology layers of the Web.
Session 4 / Synchronized Metadata:
The TV environment offers many data services, some of which have been legally prescribed. This session analysed TV needs and how they can be satisfied with current HTML5.
Subtitles and closed captioning support are one of the key requirements that have been legally prescribed to allow for equal access of non-native speakers, and blind and vision-impaired users to TV content. After demonstration of some key features defined into the HTML5 track element and the WebVTT format, it was generally accepted that HTML5 is making big progress in this space, in particular that browsers are in the process of implementing support for the track element. A concern still exists for complete coverage of all the CEA-608/708 features in WebVTT.
Further concern was raised for support of audio descriptions and audio translations, in particular since no browser has as yet committed to implementing the HTML5’s media multitrack API with the @mediagroup attribute. In this context I am excited to see first JavaScript polyfills emerge (see captionator.js & mediagroup.js).
Another concern was that many captions are actually delivered as raster images (in particular DVD captions) and how that would work in the Web context. The proposal was to use WebVTT and encode the raster images as data-URIs included in timed cues, then render them by JavaScript as an overlay. This is something to explore further.
Demos were shown using WebVTT to synchronize ads with videos, to display related metadata from a user’s life log with videos, to display thumbnails along a video’s timeline, and to show the rendering of text descriptions through screen readers. General agreement by the panel was that WebVTT offers many opportunities and that this area will continue to need further development and that we will see new capabilities on the Web around metadata that were not previously possible on TV.
Session 5 / Content Format and Codecs: DASH and Codec standards
The introduction of HTTP adaptive streaming into HTML5 was one of the core issues that kept returning in the discussions. This panel focused on MPEG DASH, but also mentioned the need for programmatic implementation of adaptive streaming functionality.
The work around MPEG DASH would require specifications of how to use DASH with WebM and Ogg Theora, as well as a specification of a HTML5 profile for DASH, which would limit the functionality possible in DASH files to the ones needed in a HTML5 video element. One criticism of DASH was its verbosity. Another was its unclear patent position. Panel attendees with included Qualcomm, Apple and Microsoft made very clear that their position is pro a royalty-free use of DASH.
The work around a programmatic implementation for adaptive streaming would require at least a JavaScript API to measure the quality of service of a presented video element and a JavaScript API to feed the video element with chunks of (encrypted) video content on the fly. Interestingly enough, there are existing experiments both around Video metrics and MediaSource extensions, so we can expect some progress in this space, even if these are not yet a strong focus of the HTML WG.
I would personally support the creation of Community Group at the W3C around HTTP adaptive streaming and DASH. I think it would work towards alleviating the perceived patent issues around DASH and allow the right members of the community to participate in preparing a specification for HTML5 without requiring them to become W3C members.
Session 6 / Content Protection and DRM
A core concern of the TV community is around content protection. The requirements in this space seem, however, very confused.
The key assumption here is that Web browsers should support the decoding of DRM-protected content in the HTML5 video element because the video element provides a desirable JavaScript API, accessibility features (the track element), default controls, and the possibility to synchronize multiple media elements. However, at the same time, the video element is part of the core content of a Web page and thus allows direct access to the image content in a canvas etc, so some of its functionality is not desirable.
The picture is further confused by requests for authentication, authorization, encryption, obfuscation, same-origin, secure transmission, secure decryption key delivery, unique content identification and other “content protection” techniques without a clear understanding of what is already possible on the Web and what requirements to content publishers actually have for delivering their content on the Web. This is further complicated by the fact that there are many competing solutions for DRM systems in the market with no clear standard that all browsers could support.
A thorough analysis of the technologies and solutions available in this space as well as an analysis of the needs for HTML5 is required before it becomes clear what solution HTML5 browsers may need to support. There seemed to be agreement in the group, though, that browsers would not need to implement DRM solutions, but rather only hand through the functionality of the platform on which they are running (including the media frameworks and operating system functionalities). How this is supposed to work was, however, unclear.
Session 7 / Web & TV: Additional Device & User Requirements
This was a catch-all session for topics that had not been addressed in other sessions. Among the topics addressed in this group were:
Parental Guidance: how to deal with ratings in an internationally inconsistent ratings landscape, how to deliver the ratings with the content, and how to enforce the viewing restrictions
Emergency Notifications: how to replicate on the Web the emergency notification functionality of TV by providing text overlays to alert users
TV channels: how to detect what channels of programming are available to users
Overall, the workshop was a worthwhile experience. It seems there is a lot of work still ahead for making HTML5 video the best it can be on the Web.
This year I’m really excited to announce that the workshop will be an integral part of the Open Video Conference on 10-12 September 2011.
FOMS 2011 will take place as the Open Media Developers track at OVC and I would like to see as many if not more open media software developers attend as we had in last year’s FOMS.
Why should you go?
Well, firstly of course the people. As in previous years, we will have some of the key developers in open media software attend - not as celebrities, but to work with other key developers on hard problems and to make progress.
Then, secondly we believe we have some awesome sessions in preparation:
I’m actually not quite satisfied with just these sessions. I’d like to be more flexible on how we make the three days a success for everyone. And this implies that there will continue to be room to add more sessions, even while at the conference, and create breakout groups to address really hard issues all the way through the conference.
I insist on this flexibility because I have seen in past years that the most productive outcomes are created by two or three people breaking away from the group, going into a corner and hacking up some demos or solutions to hard problems and taking that momentum away after the workshop.
To allow this to happen, we will have a plenary on the first day during which we will identify who is actually present at the workshop, what they are working on, what sessions they are planning on a attending, and what other topics they are keen to learn about during the conference that may not yet be addressed by existing sessions.
We’ll repeat this exercise on the Monday after all the rest of the conference is finished and we get a quieter day to just focus on being productive.
But is it worth the effort?
As in the past years, whether the workshop is a success for you depends on you and you alone. You have the power to direct what sessions and breakout groups are being created, and you have the possibility to find others at the workshop that share an interest and drag them away for some productive brainstorming or coding.
I’m going to make sure we have an adequate number of rooms available to actually achieve such an environment. I am very happy to have the support of OVC for this and I am assured we have the best location with plenty of space.
Trip sponsorships
As in previous FOMSes, we have again made sure that travel and conference sponsorship is available to community software developers that would otherwise not be able to attend FOMS. We have several such sponsorships and I encourage you to email the FOMS committee or OVC about it. Mention what you’re working on and what you’re interested to take away from OVC and we can give you free entry, hotel and flight sponsorship.
People have been asking me lots of questions about WebVTT (Web Video Text Tracks) recently. Questions about its technical nature such as: are the features included in WebVTT sufficient for broadcast captions including positioning and colors? Questions about its standardisation level: when is the spec officially finished and when will it move from the WHATWG to the W3C? Questions about implementation: are any browsers supporting it yet and how can I make use of it now?
I’m going to answer all of these questions in this post to make it more efficient than answering tweets, emails, and skype and other phone conference requests. It’s about time I do a proper post about it.
Implementations
I’m starting with the last area, because it is the simplest to answer.
No, no browser has as yet shipped support for the
However, you do not have to despair, because there are now a couple of JavaScript polyfill libraries for either just the track element or for video players with track support. You can start using these while you are waiting for the browsers to implement native support for the element and the file format.
Here are some of the libraries that I’ve come across that will support SRT and/or WebVTT (do leave a comment if you come across more):
Captionator - a polyfill for track and SRT parsing (WebVTT in the works)
js_videosub - a polyfill for track and SRT parsing
I am actually most excited about the work of Ronny Mennerich from LeanbackPlayer on WebVTT, since he has been the first to really attack full support of cue settings and to discuss with Ian, me and the WHATWG about their meaning. His review notes with visual description of how settings are to be interpreted and his demo will be most useful to authors and other developers.
Standardisation
Before we dig into the technical progress that has been made recently, I want to answer the question of “maturity”.
The WebVTT specification is currently developed at the WHATWG. It is part of the HTML specification there. When development on it started (under its then name WebSRT), it was also part of the HTML5 specification of the W3C. However, there was a concern that HTML5 should be independent of the chosen captioning format and thus WebVTT currently only exists at the WHATWG.
In recent months - and particularly since browser vendors have indicated that they will indeed implement support for WebVTT as their implementation of the
Many of the new features are about making the WebVTT format more useful for authoring and data management. The introduction of comments, inline CSS settings and default cue settings will help authors reduce the amount of styling they have to provide. File-wide metadata will help with the exchange of management information in professional captioning scenarios and archives.
But even without these new features, WebVTT already has all the features necessary to support professional captioning requirements. I’ve prepared a draft mapping of CEA-608 captions to WebVTT to demonstrate these capabilities (CEA-608 is the TV captioning standard in the US).
So, overall, WebVTT is in a great state for you to start implementing support for it in caption creation applications and in video players. There’s no need to wait any longer - I don’t expect fundamental changes to be made, but only new features to be added.
New WebVTT Features
This takes us straight to looking at the recently introduced new features.
Simpler File Magic: Whereas previously the magic file identifier for a WebVTT file was a single line with “WEBVTT FILE”. This has now been changed to a single line with just “WEBVTT”.
Cue Bold Span: The element has been introduced into WebVTT, thus aligning it somewhat more with SRT and with HTML.
CSS Selectors: The spec already allowed to use the names of tags, the classes of tags, and the voice annotations of tags as CSS selectors for ::cue. ID selector matching is now also available, where the cue identifier is used.
text-decoration support: The spec now also supports the CSS text-decoration property for WebVTT cues, allowing functionality such as blinking text and bold.
Further to this, the email identifies the means in which WebVTT is extensible:
Header area: The WebVTT header area is defined through the “WEBVTT” magic file identifier as a start and two empty lines as an end. It is possible to add into this area file-wide information header information.
Cues: Cues are defined to start with an optional identifier, and then a start/end time specification with ”—>” separator. They end with two empty lines. Cues that contain a ”—>” separator but don’t parse as valid start/end time are currently skipped. Such “cues” can be used to contain inline command blocks.
Inline in cues: Finally, within cues, everything that is within a “tag”, i.e. between "", and does not parse as one of the defined start or end tags is ignored, so we can use these to hide text. Further, text between such start and end tags is visible even if the tags are ignored, so wen can introduce new markup tags in this way.
Given this background, the following V2 extensions have been discussed:
Metadata: Enter name-value pairs of metadata into the header area, e.g.
Inline Cue Settings: Default cue settings can come in a “cue” of their own, e.g.
WEBVTTDEFAULTS --> D:vertical A:end00:00.000 --> 00:02.000This is vertical and end-aligned.00:02.500 --> 00:05.000As is this.DEFAULTS --> A:start00:05.500 --> 00:07.000This is horizontal and start-aligned.
Inline CSS: Since CSS is used to format cue text, a means to do this directly in WebVTT without a need for a Web page and external style sheet is helpful and could be done in its own cue, e.g.
Comments: Both, comments within cues and complete cues commented out are possible, e.g.
WEBVTT COMMENT --> 00:02.000 --> 00:03.000 two; this is entirely commented out 00:06.000 --> 00:07.000 this part of the cue is visible <! this part isn't > <and neither is this>
Finally, I believe we still need to add the following features:
Language tags: I’d like to add a language tag that allows to mark up a subpart of cue text as being in a different language. We need this feature for mixed-language cues (in particular where a different font may be necessary for the inline foreign-language text). But more importantly we will need this feature for cues that contain text descriptions rather than captions, such that a speech synthesizer can pick the correct language model to speak the foreign-language text. It was discussed that this could be done with a xxx type of markup.
Roll-up captions: When we use timestamp objects and the future text is hidden, then is un-hidden upon reaching its time, we should allow the cue text to scroll up a line when the un-hidden text requires adding a new line. This is the typical way in which TV live captions have been displayed and so users are acquainted with this display style.
Inline navigation: For chapter tracks the primary use of cues are for navigation. In other formats - in particular in DAISY-books for blind users - there are hierarchical navigation possibilities within media resources. We can use timestamp objects to provide further markers for navigation within cues, but in order to make these available in a hierarchical fashion, we will need a grouping tag. It would be possible to introduce a
Default caption width: At the moment, the default display size of a caption cue is 100% of the video’s width (height for vertical directions), which can be overruled with the “S” cue setting. I think it should by default rather be the width (height) of the bounding box around all the text inside the cue.
Aside from these changes to WebVTT, there are also some things that can be improved on the . I personally support the introduction of the source element underneath the track element, because that allows us to provide different caption files for different devices through the @media media queries attribute and it allows support for more than just one default captioning format. This change needs to be made soon so we don’t run into trouble with the currently empty track element.
I further think a oncuelistchange event would be nice as well in cases where the number of tracks is somehow changed - in particular when coming from within a media file.
Other than this, I’m really very happy with the state that we have achieved this far.
In the last months, we’ve been working hard at the WHATWG and W3C to spec out new HTML markup and a JavaScript interface for dealing with audio or video content that has more than just one audio and video track.
This is particularly relevant when a Web page author wants to add a sign language track to a video or audio resource for deaf people, or an audio description track (i.e. a sound track in which a speaker explains the key things that can be seen on screen) for blind people. It is also relevant when a Web page author wants to publish a video with multiple audio tracks that are each a different language dub for the video and can be used for less common cases such as a director’s comment track, or making available different camera angles for an event.
Just to be clear: this is not a means to introduce video editing functionality into the Web browser. If you want to do edits, you’re better off with an application that will eventually render a new piece of content and includes fancy transitions etc. Similarly, this is not a means to introduce mixing functionality (as in what DJs do when they play with multiple audio recordings). You’re better off with an actual audio mixing or DJ application that will provide you all sorts of amazing effects and filters.
So, multi-track is squarely focused on synchronizing alternative or additional tracks to a single resource with a single timeline to which all tracks are slaved.
Two means of publishing such multi-track media content are possible:
Of the video file formats that Web browsers support, WebM is currently not defined to contain more than one audio or video track. However, since WebM is using the Matroska container format, which supports multi-track, it is possible to extend WebM for multi-track resources. I have seen multitrack Ogg, MP4 and Matroska files in the wild and most media players support their display.
The specification that has gone into HTML5 to support in-band multi-track looks as follows:
You will notice that every audio and video track gets an index to address them. You can enable and disable individual audio tracks (via the enabled attribute) and you can select a single video track for display (via the selectedIndex attribute). This means that one or more audio tracks can be active at the same time (e.g. main audio and audio description), but only one video track will be active at a time (e.g. main video or sign language).
Through the id, kind, label and language attributes you can find out more about what actual content is available in the individual tracks so as to activate/deactivate them correctly and display the right information about them.
kind identifies the type of content that the track exposes such as “description” (for audio description), “sign” (for sign language), “main” (for the default displayed track), “translation” (for a dubbed audio track), and “alternative” (for an alternative to the default track).
label provides a human readable string that describes the content of the track aiming to be used in a menu.
id provides a short machine-readable string that can be used to construct a media fragment URI for the track. The use case for this will be discussed later.
language provides a machine-readable language code to identify which language is spoken or signed in an audio or sign language video track.
Example 1:
The following uses a video file that has a main video track, a main audio track in English and French, and an audio description track in English and French. (It likely also has caption tracks, but we will ignore text tracks for now.) This code sample switches the French audio tracks on and all other audio tracks off.
The following uses a audio file that has a main audio track in English, no main video track, but sign language video tracks in ASL (American Sign Language), BSL (British Sign Language), and ASF (Australian Sign Language). This code sample switches the Australian sign language track on and all other video tracks off.
If you have more tracks in both examples that conflict with your intentions, you may need to further filter your activation / deactivation code using the kind attribute.
2. Synchronized resources
Sometimes the production process of media creates not a single resource with multiple contained tracks, but multiple resources that all share the same timeline. This is particularly useful for the Web, because it means the user can download only the required resources, typically saving a substantial amount of bandwidth.
For this situation, an attribute called @mediagroup can be added in markup to slave multiple media elements together. This is administrated in the JavaScript API through a MediaController object, which provides events and attributes for the combined multi-track object.
The new IDL interfaces for HTMLMediaElement are as follows:
You will notice that the MediaController replicates some of the states and events of the slave media elements. In general the approach is that the attributes represent the summary state from all the elements and the writable attributes when set are handed through to all the slave elements.
Importantly, if the individual media elements have @controls activated, then the displayed controls interact with the MediaController thus allowing synchronized playback and interaction with the combined multi-track object.
Example 3:
The following uses a video file that has a main video track, a main audio track in English. There is another video file with the ASL sign language for the video, and an audio file with the audio description in English. This code sample creates controls on the first file, which then also control the audio description and the sign language video, neither of which have controls. Since the audio description doesn’t have controls, it doesn’t get visually displayed. The sign language video will just sit next to the main video without controls.
We now accompany a main video with three sign language video tracks in ASL, BSL and ASF. We could just do this in JavaScript and replace the currentSrc of a second video element with the links to BSL and ASF as required, but then we need to run our own media controls to list the available tracks. So, instead, we create a video element for each one of the tracks and use CSS to remove the inactive ones from the page layout. The code sample activates the ASF track and deactivates the other sign language tracks.
In this final example we look at what to do when we have a in-band multi-track resource with multiple video tracks that should all be displayed on screen. This is not a simple problem to solve because a video element is only allowed to display a single video track at a time. Therefore for this problem you need to use both approaches: in-band and synchronized resources.
We take a in-band multitrack resource with a main video and audio track and three sign language tracks in ASL, BSL and ASF. The second resource will be made up from the URI of the first resource with a media fragment address of the sign language tracks. (If required, these can be discovered using the getID() function on the first resource.) The markup will look as follows:
Note that with multiple video elements you can always style them in the way that you want them displayed on screen. E.g. if you want a picture-in-picture display, you scale the second video down and absolutely position it on top of the first one in the appropriate location. You can even grab the second video into a canvas, chroma-key your sign language speaker on a green or blue screen and remove that background through some canvas processing before popping it on top of the video.
The world is all yours!
HOWEVER: There is one big caveat on all these specs - while they have all found entry into the HTML5 specification, it would be expecting a bit much to have browser support already. :-)
UPDATE 23 July 2014: I’ve just changed this to use the latest spec, which should also at least partially be implemented already.
On Wednesday, I gave a talk at Google about WebVTT, the Web Video Text Track file format that is under development at the WHATWG for solving time-aligned text challenges for video.
I started by explaining all the features that WebVTT supports for captions and subtitles, mentioned how WebVTT would be used for text audio descriptions and navigation/chapters, and explained how it is included into HTML5 markup, such that the browser provides some default rendering for these purposes. I also mentioned the metadata approach that allows any timed content to be included into cues.
The talk slides include a demo of how the
The talk was recorded and has been made available as a Google Tech talk with captions and also a separate version with extended audio descriptions.
The slides of the talk are also available (best to choose the black theme).
At the recent Linux conference in Brisbane, Australia, I promised a free copy of my book to the person that could send me the best idea for an HTML5 video application. I later also tweeted about it.
While I didn’t get many emails, I am still impressed by the things people want to do. Amongst the posts were the following proposals:
Develop a simple video cutting tool to, say setting cut points and having a very simple backend taking the cut points and generating quick enough output. The cutting doesn’t need to retranscode.
Use HTML5 video, especially the tracking between video and text, to better present video from the NZ Parliament.
Making a small MMO game using WebGL, HTML5 audio and WebSockets. I also want to use the same code for desktop and web.
These are all awesome ideas and I found it really hard to decide whom to give the free book to. In the end, I decided to give it to Brian McKenna, who is working on the MMO game - simply because it it is really pushing the boundaries of several HTML5 technologies.
To everyone else: the book is actually not that expensive to buy from APRESS or Amazon and you can get the eBook version there, too.
Thanks to everyone who started really thinking about this and sent in a proposal!
Working in the WHAT WG and the W3C HTML WG, you sometimes forget that all the things that are being discussed so heatedly for standardization are actually leading to some really exciting new technologies that not many outside have really taken note of yet.
This week, during the Australian Linux Conference in Brisbane, I’ve been extremely lucky to be able to show off some awesome new features that browser vendors have implemented for the audio and video elements. The feedback that I got from people was uniformly plain surprise - nobody expected browser to have all these capabilities.
The examples that I showed off have mostly been the result of working on a book for almost 9 months of the past year and writing lots of examples of what can be achieved with existing implementations and specifications. They have been inspired by diverse demos that people made in the last years, so the book is linking to many more and many more amazing demos.
Incidentally, I promised to give a copy of the book away to the person with the best idea for a new Web application using HTML5 media. Since we ran out of time, please shoot me an email or a tweet (@silviapfeiffer) within the next 4 weeks and I will send another copy to the person with the best idea. The copy that I brought along was given to a student who wanted to use HTML5 video to display on surfaces of 3D moving objects.
I further gave a brief lightning talk about “HTML5 Media Accessibility Update”. I am expecting lots to happen on this topic during this year.
Finally, I gave a presentation today on “The Latest and Coolest in HTML5 Media” with a strong focus on video, but also touching on audio and media accessibility.
The talks were streamed live - congrats to Ryan Verner for getting this working with support from Ben Hutchings from DebConf and the rest of the video team. The videos will apparently be available from http://linuxconfau.blip.tv/ in the near future.
In the past week, I was invited to an IBM workshop on audio/text descriptions for video in Japan. Geoff Freed and Trisha O’Connell from WGBH, and Michael Evans from BBC research were the other invited experts to speak about the current state of video accessibility around the world and where things are going in TV/digital TV and the Web.
The two day workshop was very productive. The first day was spent with presentations which were open to the public. A large vision-impaired community attended to understand where technology is going. It was very humbling to be part of an English-spoken workshop in Japan, where much of the audience is blind, but speaks English much better than my average experience with English in Japan. I met many very impressive and passionate people that are creating audio descriptions, adapting NVDA for the Japanese market, advocating to Broadcasters and Government to create more audio descriptions, and perform fundamental research for better tools to create audio descriptions. My own presentation was on “HTML5 Video Descriptions”.
On the second day, we only met with the IBM researchers and focused discussions on two topics:
How to increase the amount of video descriptions
HTML5 specifications for video descriptions
The first topic included concerns about guidelines for description authoring by beginners, how to raise awareness, who to lobby, and what production tools are required. I personally was more interested in the second topic and we moved into a smaller breakout group to focus on these discussions.
HTML5 specifications for video descriptions Two topics were discussed related to video descriptions: text descriptions and audio descriptions. Text descriptions are descriptions authored as time-aligned text snippets and read out by a screen reader. Audio descriptions are audio recordings either of a human voice or even of a TTS (text-to-speech) synthesis - in either case, they are audio samples.
For a screen reader, the focus was actually largely on NVDA and people were very excited about the availability of this open source tool. There is a concern about how natural-sounding a screen reader can be made and IBM is doing much research there with some amazing results. In user experiment between WGBH and IBM they found that the more natural the voice sounds, the more people comprehend, but between a good screen reader and an actual human voice there is not much difference in the comprehension level. Broadcasters and other high-end producers are unlikely to accept TTS and will prefer the human voice, but for other materials - in particular for the large majority of content on the Web - TTS and screen readers can make a big difference.
An interesting lesson that I learnt was that video descriptions can be improved by 30% (i.e. 30% better comprehension) if we introduce extended descriptions, i.e. descriptions that can pause the main video to allow for a description be read for something that happens in the video, but where there is no obvious pause to read out the description. So, extended descriptions are one of the major challenges to get right.
We then looked at the path that we are currently progressing on in HTML5 with WebSRT, the TimedTrack API, the
For text descriptions we identified a need for the following:
extension marker on cues: often it is very clear to the author of a description cue that there is no time for the cue to be read out in parallel to the main audio and the video needs to be paused. The proposal is for introduction of an extension marker on the cue to pause the video until the screen reader is finished. So, a speech-complete event from the screen reader API needs to be dealt with. To make this reliable, it might make sense to put a max duration on the cue so the video doesn’t end up waiting endlessly in case the screen reader event isn’t fired. The duration would be calculated based on a typical word speaking rate.
importance marker on cues: the duration of all text cues being read out by screen readers depends on the speed set-up of the screen reader. So, even when a cue has been created for a given audio break in the video, it may or may not fit into this break. For most cues it is important that they are read out completely before moving on, but for some it’s not. So, an importance maker could be introduced that determines whether a video stops at the end of the cue to allow the screen reader to finish, or whether the screen reader is silenced at that time no matter how far it has gotten.
ducking during cues: making the main audio track quieter in relation to the video description for the duration of a cue such as to allow the comprehension of the video description cue is important for comprehension
voice hints: an instruction at the beginning of the text description file for what voice to choose such that it won’t collide with e.g. the narrator voice of a video - typically the choice will be for a female voice when the narrator is male and the other way around - this will help initialize the screen reader appropriately
speed hints: an indicator at the beginning of a text description toward what word rate was used as the baseline for the timing of the cue durations such that a screen reader can be initialized with this
synthesis directives: while not a priority, eventually it will make for better quality synchronized text if it is possible to include some of the typical markers that speech synthesizers use (see e.g. SSML or speech CSS), including markers for speaker change, for emphasis, for pitch change and other prosody. It was, in fact, suggested that the CSS3’s speech module may be sufficient in particular since Opera already implements it.
This means we need to consider extending WebSRT cues with an “extension” marker and an “importance” marker. WebSRT further needs header-type metadata to include a voice and a speed hint for screen readers. The screen reader further needs to work more closely with the browser and exchange speech-complete events and hints for ducking. And finally we may need to allow for CSS3 speech styles on subparts of WebSRT cues, though I believe this latter one is not of high immediate importance.
For audio descriptions we identified a need for:
external/in-band descriptions: allowing external or in-band description tracks to be synchronized with the main video. It would be assumed in this case that the timeline of the description track is identical to the main video.
extended external descriptions: since it’s impossible to create in-band extended descriptions without changing the timeline of the main video, we can only properly solve the issue of extended audio descriptions through external resources. One idea that we came up with is to use a WebSRT file with links to short audio recordings as external extended audio descriptions. These can then be synchronized with the video and pause the video at the correct time etc through JavaScript. This is probably a sufficient solution for now. It supports both, sighted and vision-impaired users and does not extend the timeline of the original video. As an optimization, we can also do this through a single “virtual” resource that is a concatenation of the individual audio cues and is addressed through the WebSRT file with byte ranges.
ducking: making the main audio track quieter in relation to the video description for the duration of a cue such as to allow the comprehension of the video description cue is important for comprehension also with audio files, though it may be more difficult to realize
separate loudness control: making it possible for the viewer to separately turn the loudness of an audio description up/down in comparison to the main audio
For audio descriptions, we saw the need for introduction of a multitrack video API and markup to synchronize external audio description tracks with the main video. Extended audio descriptions should be solved through JavaScript and hooking up through the TimedTrack API, so mostly rolling it by hand at this stage. We will see how that develops in future. Ducking and separate loudness controls are equally needed here, but we do need more experiments in this space.
Finally, we discussed general needs to locate accessibility content such as audio descriptions by vision-impaired user:
the need for accessible user menus to turn on/off accessibility content
the introduction of dedicated and standardized keyboard short-cuts to turn on and manipulate the volume of audio descriptions (and captions)
the introduction of user preferences for automatically activating accessibility content; these could even learn from current usage, such that if a user activates descriptions for a video on one Website, the preferences pick this up; different user profiles are already introduced by ISO in “Access for all” and used in websites such as teachersdomain
means to generally locate accessibility content on the web, such as fields in search engines and RSS feeds
more generally there was a request to have caption on/off and description on/off buttons be introduced into remote controls of machines, which will become prevalent with the increasing amount of modern TV/Internet integrated devices
Overall, the workshop was a great success and I am keen to see more experimentation in this space. I also hope that some of the great work that was shown to us at IBM with extended descriptions and text descriptions will become available - if only as screencasts - so we can all learn from it to make better standards and technology.
I wanted to give people an introduction into how to use these elements while at the same time stirring their imagination as to the design possibilities now that these elements are available natively in browsers. I re-used some of the demos that I have put together for the book that I am currently writing, added some of the cool stuff that others have done and finished off with an outlook towards what new features will probably arrive next.
“Slides” are now available, which are really just a Web page with some demos that work in modern browsers.
At this week’s FOMS in New York we had one over-arching topic that seemed to be of interest to every single participant: how to do adaptive bitrate streaming over HTTP for open codecs. On the first day, there was a general discussion about the advantages and disadvantages of adaptive HTTP streaming, while on the second day, we moved towards designing a solution for Ogg and WebM. While I didn’t attend all the discussions, I want to summarize the insights that I took out of the days in this blog post and the alternative implementation strategies that were came up with.
Use Cases for Adaptive HTTP Streaming
Streaming using RTP/RTSP has in the past been the main protocol to provide live video streams, either for broadcast or for real-time communication. It has been purpose-built for chunked video delivery and has features that many customers want, such as the ability to encrypt the stream, to tell players not to store the data, and to monitor the performance of the stream such that its bandwidth can be adapted. It has, however, also many disadvantages, not least that it goes over ports that normal firewalls block and thus is rather difficult to deploy, but also that it requires special server software, a client that speaks the protocol, and has a signalling overhead on the transport layer for adapting the stream.
RTP/RTSP has been invented to allow for high quality of service video consumption. In the last 10 years, however, it has become the norm to consume “canned” video (i.e. non-live video) over HTTP, making use of the byte-range request functionality of HTTP for seeking. While methods have been created to estimate the size of a pre-buffer before starting to play back in order to achieve continuous playback based on the bandwidth of your pipe at the beginning of downloading, not much can be done when one runs out of pre-buffer in the middle of playback or when the CPU on the machine doesn’t manage to catch up with decoding of the sheer amount of video data: your playback stops to go into re-buffering in the first case and starts to become choppy in the latter case.
An obvious approach to improving this situation is the scale the bandwidth of the video stream down, potentially even switch to a lower resolution video, right in the middle of playback. Apple’s HTTP live streaming, Microsoft’s Smooth Streaming, and Adobe’s Dynamic Streaming are all solutions in this space. Also, ISO/MPEG is working on DASH (Dynamic Adaptive Streaming over HTTP) is an effort to standardize the approach for MPEG media. No solution yets exist for the open formats within Ogg or WebM containers.
Some features of HTTP adaptive streaming are:
Enables adaptation of downloading to avoid continuing buffering when network or machine cannot cope.
Gapless switching between streams of different bitrate.
No special server software is required - any existing Web Server can be used to provide the streams.
The adaptation comes from the media player that actually knows what quality the user experiences rather than the network layer that knows nothing about the performance of the computer, and can only tell about the performance of the network.
Adaptation means that several versions of different bandwidth are made available on the server and the client switches between them based on knowledge it has about the video quality that the user experiences.
Bandwidth is not wasted by downloading video data that is not being consumed by the user, but rather content is pulled moments just before it is required, which works both for the live and canned content case and is particularly useful for long-form content.
Viability
In discussions at FOMS it was determined that mid-stream switching between different bitrate encoded audio files is possible. Just looking at the PCM domain, it requires stitching the waveform together at the switch-over point, but that is not a complex function. To be able to do that stitching with Vorbis-encoded files, there is no need for a overlap of data, because the encoded samples of the previous window in a different bitrate page can be used as input into the decoding of the current bitrate page, as long as the resulting PCM samples are stitched.
For video, mid-stream switching to a different bitrate encoded stream is also acceptable, as long as the switch-over point adheres to a keyframe, which can be independently decoded.
Thus, the preparation of the alternative bitstream videos requires temporal synchronisation of keyframes on video - the audio can deal with the switch-over at any point. A bit of intelligent encoding is thus necessary - requiring the encoding pipeline to provide regular keyframes at a certain rate would be sufficient. Then, the switch-over points are the keyframes.
Technical Realisation
With the solutions from Adobe, Microsoft and Apple, the technology has been created such there are special tools on the server that prepare the content for adaptive HTTP streaming and provide a manifest of the prepared content. Typically, the content is encoded in versions of different bitrates and the bandwidth versions are broken into chunks that can be decoded independently. These chunks are synchronised between the different bitrate versions such that there are defined switch-over points. The switch-over points as well as the file names of the different chunks are documented inside a manifest file. It is this manifest file that the player downloads instead of the resource at the beginning of streaming. This manifest file informs the player of the available resources and enables it to orchestrate the correct URL requests to the server as it progresses through the resource.
At FOMS, we took a step back from this approach and analysed what the general possibilities are for solving adaptive HTTP streaming. For example, it would be possible to not chunk the original media data, but instead perform range requests on the different bitrate versions of the resource. The following options were identified.
Chunking
With Chunking, the original bitrate versions are chunked into smaller full resources with defined switch-over points. This implies creation of a header on each one of the chunks and thus introduces overhead. Assuming we use 10sec chunks and 6kBytes per chunk, that results in 5kBit/sec extra overhead. After chunking the files this way, we provide a manifest file (similar to Apple’s m3u8 file, or the SMIL-based manifest file of Microsoft, or Adobe’s Flash Media Manifest file). The manifest file informs the client about the chunks and the switch-over points and the client requests those different resources at the switch-over points.
Disadvantages:
Header overhead on the pipe.
Switch-over delay for decoding the header.
Possible problem with TCP slowstart on new files.
A piece of software is necessary on server to prepare the chunked files.
A large amount of files to manage on the server.
The client has to hide the switching between full resources.
Advantages:
Works for live streams, where increasing amounts of chunks are written.
Works well with CDNs, because mid-stream switching to another server is easy.
Chunks can be encoded such that there is no overlap in the data necessary on switch-over.
May work well with Web sockets.
Follows the way in which proprietary solutions are doing it, so may be easy to adopt.
If the chunks are concatenated on the client, you get chained Ogg files (similar concept in WebM?), which are planned to be supported by Web browsers and are thus legal files.
Chained Chunks
Alternatively to creating the large number of files, one could also just create the chained files. Then, the switch-over is not between different files, but between different byte ranges. The headers still have to be read and parsed. And a manifest file still has to exist, but it now points to byte ranges rather than different resources.
Advantages over Chunking:
No TCP-slowstart problem.
No large number of files on the server.
Disadvantages over Chunking:
Mid-stream switching to other servers is not easily possible - CDNs won’t like it.
Doesn’t work with Web sockets as easily.
New approach that vendors will have to grapple with.
Virtual Chunks
Since in Chained Chunks we are already doing byte-range requests, it is a short step towards simply dropping the repeating headers and just downloading them once at the beginning for all possible bitrate files. Then, as we seek to different positions in “the” file, the byte range of the bitrate version that makes sense to retrieve at that stage would be requested. This could even be done with media fragment URIs, through addressing with time ranges is less accurate than explicit byte ranges.
In contrast to the previous two options, this basically requires keeping n different encoding pipelines alive - one for every bitrate version. Then, the byte ranges of the chunks will be interpreted by the appropriate pipeline. The manifest now points to keyframes as switch-over points.
Advantage over Chained Chunking:
No header overhead.
No continuous re-initialisation of decoding pipelines.
Disadvantages over Chained Chunking:
Multiple decoding pipelines need to be maintained and byte ranges managed for each.
Unchunked Byte Ranges
We can even consider going all the way and not preparing the alternative bitrate resources for switching, i.e. not making sure that the keyframes align. This will then require the player to do the switching itself, determine when the next keyframe comes up in its current stream then seek to that position in the next stream, always making sure to go back to the last keyframe before that position and discard all data until it arrives at the same offset.
Disadvantages:
There will be an overlap in the timeline for download, which has to be managed from the buffering and alignment POV.
Overlap poses a challenge of downloading more data than necessary at exactly the time where one doesn’t have bandwidth to spare.
Requires seeking.
Messy.
Advantages:
No special authoring of resources on the server is needed.
Requires a very simple manifest file only with a list of alternative bitrate files.
Final concerns
At FOMS we weren’t able to make a final decision on how to achieve adaptive HTTP streaming for open codecs. Most agreed that moving forward with the first case would be the right thing to do, but the sheer number of files that can create is daunting and it would be nice to avoid that for users.
Other goals are to make it work in stand-alone players, which means they will need to support loading the manifest file. And finally we want to enable experimentation in the browser through JavaScript implementation, which means there needs to be an interface to provide the quality of decoding to JavaScript. Fortunately, a proposal for such a statistics API already exists. The number of received frames, the number of dropped frames, and the size of the video are the most important statistics required.
Today I gave a talk at the Open Video Conference about the state of the specifications in HTML5 for media accessibility.
To be clear: at this exact moment, there is no actual specification text in the W3C version of HTML5 for media accessibility. There is, however, some text in the WHATWG version, providing a framework for text-based alternative content. Other alternative content still requires new specification text. Finally, there is no implementation in any browser yet for media accessibility, but we are getting closer. As browser vendors are moving towards implementing support for the WHATWG specifications of the , the TimedTrack JavaScript API, and the WebSRT format, video sites can also experiment with the provided specifications and contribute feedback to improve the specifications.
Attached are my slides from today’s talk. I went through some of the key requirements of accessibility users and showed how they are being met by the new specifications (in green) or could be met with some still-to-be-developed specifications (in blue). Note that the talk and slides focus on accessibility needs, but the developed technologies will be useful far beyond just accessibility needs and will also help satisfy other needs, such as the needs of internationalization (through subtitles), of exposing multitrack audio/video (through the JavaScript API), of providing timed metadata (through WebSRT), or even of supporting Karaoke (through WebSRT). In the tables on the last two pages I summarize the gaps in the specifications where we will be working on next and also show what is already possible with given specifications.
Over the last two days we had the Open Subtitles Summit here in New York. It was very exciting to feel the energy in the room to make a change to media accessibility - I am sure we will see much development over the next 12 months. We spoke much about HTML5 video and standards and had many discussions about subtitles, captions, and other accessibility information.
On Wednesday we had a discussion about metadata and I quickly realized that “your metadata is not my metadata”: everyone used the word for something different. So, I suggested to have a metadata discussion on Thursday where we would put a structure onto all of this, identify what kinds of metadata we have and whether and how it should be supported in HTML5 standards.
Our basic findings are very simple and widely accepted. There are three fundamentally different types of metadata:
Technical metadata about video: information about the format of the resource - things that can be determined automatically and are non-controversial, such as the width, height, framerate, audio sample rate etc. This information can be used to, e.g. decide if a video is appropriate for a certain device.
Semantic metadata about video: semantic information about the video resource - e.g. license, author, publication date, version, attribution, title, description. This information is good for search and identification.
Timed semantic metadata: semantic information that is associated with time intervals of the video, not with the full video - e.g. active speaker, location, date-time, objects.
As we talked about this further, however, we identified subclasses of these generic types that are very important to identify because they will be handled differently.
We found that semantic metadata can be separated into universal metadata and domain-specific metadata. Universal metadata is semantic metadata that can basically be applied to any content. There is very little of that and the W3C Media Annotations WG has done a pretty good job in identifying it. Domain-specific metadata is such metadata that only applies to some content, e.g. all the videos about sports have metadata such as game scores, players, or type of sport.
As for adding such metadata into media resources, we discussed that it makes sense to have the universal metadata explicitly spelled out and to have a generic means to associate name-value pairs with resource. Of course it will all be stored in databases, but there was also a requirement to have it encoded into the media resource - and in our discussion case: into external captions or subtitle files.
As for timed metadata - it is possible to separate this into metadata that is only relevant as part of a subtitle or caption file, because the metadata relates to a certain word or a word sequence, and into independent timed metadata that can be stored in, e.g. JSON or some similar format.
Since we are particularly interested in subtitles and captions, the timed metadata that is associated with words or word sequences is particularly important. The most natural metadata that is useful as part of subtitles is of course speaker segmentation. We also identified that hyperlinks to related content are just as important, since it can enable applications such as popcorn.js.
Potentially there is a use for metadata association with any sequence of words in a caption or subtitle, which could be satisfied with the use of a generic markup element for a sequence of words, such that microdata or RDFa may get associated. A request for such a generic means of associating metadata was made. However, the need for it still has to be confirmed with good use cases - the breakout group was out of time as we came to this point. So, leave your ideas for use cases in the requirements - they will help shape standards.
What I want to do here is to summarize what was introduced, together with the improvements that I and some others have proposed in follow-upemails, and list some of the media accessibility needs that we are not yet dealing with.
For those wanting to only selectively read some sections, here is a clickable table of contents of this rather long blog post:
The first and to everyone probably most surprising part is the new file format that is being proposed to contain out-of-band time-synchronized text for video. A new format was necessary after the analysis of all relevant existing formats determined that they were either insufficient or hard to use in a Web environment.
The new format is called WebSRT and is an extension to the existing SRT SubRip format. It is actually also the part of the new specification that I am personally most uncomfortable with. Not that WebSRT is a bad format. It’s just not sufficient yet to provide all the functionality that a good time-synchronized text format for Web media should. Let’s look at some examples.
WebSRT is composed of a sequence of timed text cues (that’s what we’ve decided to call the pieces of text that are active during a certain time interval). Because of its ancestry of SRT, the text cues can optionally be numbered through. The content of the text cues is currently allowed to contain three different types of text: plain text, minimal markup, and anything at all (also called “metadata”).
In its most simple form, a WebSRT file is just an ordinary old SRT file with optional cue numbers and only plain text in cues:
1 00:00:15.00 --> 00:00:17.95 At the left we can see... 2 00:00:18.16 --> 00:00:20.08 At the right we can see the... 3 00:00:20.11 --> 00:00:21.96 ...the head-snarlers
A bit of a more complex example results if we introduce minimal markup:
00:00:15.00 --> 00:00:17.95 A:start Auf der <i>linken</i> Seite sehen wir... 00:00:18.16 --> 00:00:20.08 A:end Auf der <b>rechten</b> Seite sehen wir die.... 00:00:20.11 --> 00:00:21.96 A:end <1>...die Enthaupter. 00:00:21.99 --> 00:00:24.36 A:start <2>Alles ist sicher. Vollkommen <b>sicher</b>.
and add to this a CSS to provide for some colors and special formatting:
Minimal markup accepts , , and a timestamp in <>, providing for italics, bold, and ruby markup as well as karaoke timestamps. Any further styling can be done using the CSS pseudo-elements ::cue and ::cue-part, which accept the features ‘color’, ‘text-shadow’, ‘text-outline’, ‘background’, ‘outline’, and ‘font’.
Note that positioning requires some special notes at the end of the start/end timestamps which can provide for vertical text, line position, text position, size and alignment cue setting. Here is an example with vertically rendered Chinese text, right-aligned at 98% of the video frame:
Finally, WebSRT files can be authored with abstract metadata inside cues, which practically means anything at all. Here’s an example with HTML content:
00:00:15.00 --> 00:00:17.95 A:start <img src="pic1.png"/>Auf der <i>linken</i> Seite sehen wir... 00:00:18.16 --> 00:00:20.08 A:end <img src="pic2.png"/>Auf der <b>rechten</b> Seite sehen wir die.... 00:00:20.11 --> 00:00:21.96 A:end <img src="pic3.png"/>...die <a href="http://members.chello.nl/j.kassenaar/elephantsdream/subtitles.html">Enthaupter</a>. 00:00:21.99 --> 00:00:24.36 A:start <img src="pic4.png"/>Alles ist <mark>sicher</mark>.<br/>Vollkommen <b>sicher</b>.
Here is another example with JSON in the cues:
00:00:00.00 --> 00:00:44.00 { slide: intro.png, title: "Really Achieving Your Childhood Dreams" by Randy Pausch, Carnegie Mellon University, Sept 18, 2007 } 00:00:44.00 --> 00:01:18.00 { slide: elephant.png, title: The elephant in the room... } 00:01:18.00 --> 00:02:05.00 { slide: denial.png, title: I'm not in denial... }
What I like about WebSRT:
it allows for all sorts of different content in the text cues - plain text is useful for texted audio descriptions, minimal markup is useful for subtitles, captions, karaoke and chapters, and “metadata” is useful for, well, any data.
it can be easily encapsulated into media resources and thus turned into in-band tracks by regarding each cue as a data packet with time stamps.
it is not verbose
Where I think WebSRT still needs improvements:
break with the SRT history: since WebSRT and SRT files are so different, WebSRT should get its own MIME type, e.g. text/websrt, and file extensions, e.g. .wsrt; this will free WebSRT for changes that wouldn’t be possible by trying to keep conformant with SRT
introduce some header fields into WebSRT: the format needs
file-wide name-value metadata, such as author, date, copyright, etc
language specification for the file as a hint for font selection and speech synthesis
a possibility for style sheet association in the file header
a means to identify which parser is required for the cues
a magic identifier and a version string of the format
allow innerHTML as an additional format in the cues with the CSS pseudo-elements applying to all HTML elements
allow full use of CSS instead of just the restricted features and also use it for positioning instead of the hard to understand positioning hints
on the minimum markup, provide a neutral structuring element such as <span @id @class @lang> to associate specific styles or specific languages with a subpart of the cue
Note that I undertook some experiments with an alternative format that is XML-based and called WMML to gain most of these insights and determine the advantages/disadvantages of a xml-based format. The foremost advantage is that there is no automatism with newlines and displayed new lines, which can make the source text file more readable. The foremost disadvantages are verbosity and that there needs to be a simple encoding step to remove all encapsulating header-type content from around the timed text cues before encoding it into a binary media resource.
Now that we have a timed text format, we need to be able to associate it with a media resource in HTML5. This is what the was introduced for. It associates the timestamps in the timed text cues with the timeline of the video resource. The browser is then expected to render these during the time interval in which the cues are expected to be active.
Here is an example for how to associate multiple subtitle tracks with a video:
In this case, the UA is expected to provide a text menu with a subtitle entry with these three tracks and their label as part of the video controls. Thus, the user can interactively activate one of the tracks.
Here is an example for multiple tracks of different kinds:
In this case, the UA is expected to provide a text menu with a list of track kinds with one entry each for subtitles, captions and descriptions through the controls. The chapter tracks are expected to provide some sort of visual subdivision on the timeline and the metadata tracks are not exposed visually, but are only available through the JavaScript API.
Here are several ideas for improving the
karaoke and lyrics are supported by WebSRT, but aren’t in the HTML5 spec as track kinds - they should be added and made visible like subtitles or captions.
This is where we take an extra step and move to a uniform handling of both in-band and out-of-band timed text tracks. Futher, a third type of timed text track has been introduced in the form of a MutableTimedTrack - i.e. one that can be authored and added through JavaScript alone.
The JavaScript API that is exposed for any of these track type is identical. A media element now has this additional IDL interface:
interface HTMLMediaElement : HTMLElement {... readonly attribute TimedTrack[] tracks; MutableTimedTrack addTrack(in DOMString label, in DOMString kind, in DOMString language);};
A media element thus manages a list of TimedTracks and provides for adding TimedTracks through addTrack().
The timed tracks are associated with a media resource in the following order:
The
Tracks created through the addTrack() method, in the order they were added, oldest first.
In-band timed text tracks, in the order defined by the media resource’s format specification.
The IDL interface of a TimedTrack is as follows:
interface TimedTrack { readonly attribute DOMString kind; readonly attribute DOMString label; readonly attribute DOMString language; readonly attribute unsigned short readyState; attribute unsigned short mode; readonly attribute TimedTrackCueList cues; readonly attribute TimedTrackCueList activeCues; readonly attribute Function onload; readonly attribute Function onerror; readonly attribute Function oncuechange;};
The first three capture the value of the @kind, @label and @srclang attributes and are provided by the addTrack() function for MutableTimedTracks and exposed from metadata in the binary resource for in-band tracks.
The readyState captures whether the data is available and is one of “not loaded”, “loading”, “loaded”, “failed to load”. Data is only availalbe in “loaded” state.
The mode attribute captures whether the data is activate to be displayed and is one of “disabled”, “hidden” and “showing”. In the “disabled” mode, the UA doesn’t have to download the resource, allowing for some bandwidth management.
The cues and activeCues attributes provide the list of parsed cues for the given track and the subpart thereof that is currently active.
The onload, onerror, and oncuechange functions are event handlers for the load, error and cuechange events of the TimedTrack.
Individual cues expose the following IDL interface:
The @track attribute links the cue to its TimedTrack.
The @id, @startTime, @endTime attributes expose a cue identifier and its associated time interval. The getCueAsSource() and getCueAsHTML() functions provide either an unparsed cue text content or a text content parsed into a HTML DOM subtree.
The @pauseOnExit attribute can be set to true/false and indicates whether at the end of the cue’s time interval the media playback should be paused and wait for user interaction to continue. This is particularly important as we are trying to support extended audio descriptions and extended captions.
The onenter and onexit functions are event handlers for the enter and exit events of the TimedTrackCue.
The @direction, @snapToLines, @linePosition, @textPosition, @size, @alignment and @voice attributes expose WebSRT positioning and semantic markup of the cue.
My only concerns with this part of the specification are:
The WebSRT-related attributes in the TimedTrackCue are in conflict with CSS attributes and really should not be introduced into HTML5, since they are WebSRT-specific. They will not exist in other types of in-band or out-of-band timed text tracks. As there is a mapping to do already, why not rely on already available CSS features.
There is no API to expose header-specific metadata from timed text tracks into JavaScript. This such as the copyright holder, the creation date and the usage rights of a timed text track would be useful to have available. I would propose to add a list of name-value metadata elements to the TimedTrack API.
In addition, I would propose to allow media fragment hyperlinks in a
The third part of the timed track framework deals with how to render the timed text cues in a Web page. The rendering rules are explained in the HTML5 rendering section.
I’ve extracted the following rough steps from the rendering algorithm:
All timed tracks of a media resource that are in “showing” mode are rendered together to avoid overlapping text from multiple tracks.
The timed tracks cues that are to be rendered are collected from the active timed tracks and ordered by the timed track order first and by their start time second. Where there are identical start times, the cues are ordered by their end time, earliest first, or by their creation order if all else is identical.
Each cue gets its own CSS box.
The text in the CSS boxes is positioned and formated by interpreting the positioning and formatting instructions of WebSRT that are provided on the cues.
An anonymous inline CSS box is created into which all the cue CSS boxes are wrapped.
The wrapping CSS box gets the dimensions of the video viewport. The cue CSS boxes are positioned so they don’t overlap. The text inside the cue CSS boxes inside the wrapping CSS box is wrapped at the edges if necessary.
To overcome security concerns with this kind of direct rendering of a CSS box into the Web page where text comes potentially from a different and malicious Web site, it is required to have the cues come from the same origin as the Web page.
To allow application of a restricted set of CSS properties to the timed text cues, a set of pseudo-selectors was introduced. This is necessary since all the CSS boxes are anonymous and cannot be addressed from the Web page. The introduced pseudo-selectors are ::cue to address a complete cue CSS box, and ::cue-part to address a subpart of a cue CSS box based on a set of identifiers provided by WebSRT.
I have several issues with this approach:
I believe that it is not a good idea to only restrict rendering to same-origin files. This will disallow the use of external captioning services (or even just a separate caption server of the same company) to link to for providing the captions to a video. Henri Sivonen proposed a means to overcome this by parsing every cue basically as its own HTML document (well, the body of a document) and then rendering these in iFrame-manner into the Web page. This would overcome the same-origin restriction. It would also allow to do away with the new ::cue CSS selectors, thus simplifying the solution.
In general I am concerned about how tightly the rendering is tied to WebSRT. Step 4 should not be in the HTML5 specification, but only apply to WebSRT. Every external format should provide its own mapping to CSS. As it is specified right now, other formats, such as e.g. 3GPP in MPEG-4 or Kate in Ogg, are required to map their format and positioning information to WebSRT instructions. These are then converted again using the WebSRT to CSS mapping rules. That seems overkill.
I also find step 6 very limiting, since only the video viewport is regarded as a potential rendering area - this is also the reason why there is no rendering for audio elements. Instead, it would make a lot more sense if a CSS box was provided by the HTML page - the default being the video viewport, but it could be changed to any area on screen. This would allow to render music lyrics under or above an audio element, or render captions below a video element to avoid any overlap at all.
SUMMARY AND FURTHER NEEDS
We’ve made huge progress on accessibility features for HTML5 media elements with the specifications that Ian proposed. I think we can move it to a flexible and feature-rich framework as the improvements that Henri, myself and others have proposed are included.
However, we are not solving any of the accessibility needs that relate to alternative audio-visual tracks and resources. In particular there is no solution yet to deal with multi-track audio or video files that have e.g. sign language or audio description tracks in them - not to speak of the issues that can be introduced through dealing with separate media resources from several sites that need to be played back in sync. This latter may be a challenge for future versions of HTML5, since needs for such synchoronisation of multiple resources have to be explored further.
In a first instance, we will require an API to expose in-band tracks, a means to control their activation interactively in a UI, and a description of how they should be rendered. E.g. should a sign language track be rendered as pciture-in-picture? Clear audio and Sign translation are the two key accessibility needs that can be satisfied with such a multi-track solution.
Finally, another key requirement area for media accessibility is described in a section called “Content Navigation by Content Structure”. This describes the need for vision-impaired users to be able to navigate through a media resource based on semantic markup - think of it as similar to a navigation through a book by book chapters and paragraphs. The introduction of chapter markers goes some way towards satisfying this need, but chapter markers tend to address only big time intervals in a video and don’t let you navigate on a different level to subchapters and paragraphs. It is possible to provide that navigation through providing several chapter tracks at different resolution levels, but then they are not linked together and navigation cannot easily swap between resolution levels.
An alternative might be to include different resolution levels inside a single chapter track and somehow control the UI to manage them as different resolutions. This would only require an additional attribute on text cues and could be useful to other types of text tracks, too. For example, captions could be navigated based on scenes, shots, coversations, or individual captions. Some experimentation will be required here before we can introduce a sensible extension to the given media accessibility framework.
For 2 months now, I have been quietly working along on a new Mozilla contract that I received to continue working on HTML5 media accessibility. Thanks Mozilla!
Lots has been happening - the W3C HTML5 accessibility task force published a requirements document, the Media Text Associations proposal made it into the HTML5 draft as a , and there are discussions about the advantages and disadvantages of the new WebSRT caption format that Ian Hickson created in the WHATWG HTML5 draft.
The first three now already have first drafts in the HTML5 specification, though the details still need to be improved and an external text track file format agreed on. The last has had a major push ahead with the Media Fragments WG publishing a Last Call Working Draft. So, on the specification side of things, major progress has been made. On the implementation - even on the example implementation - side of things, we still fall down badly. This is where my focus will lie in the next few months.
After two years of effort, the W3C Media Fragment WG has now created a Last Call Working Draft document. This means that the working group is fairly confident that they have addressed all the required issues for media fragment URIs and their implementation on HTTP and is asking for outside experts and groups for input. This is the time for you to get active and proof-read the specification thoroughly and feed back all the concerns that you have and all the things you do not understand!
The media fragment (MF) URI specification specifies two types of MF URIs: those created with a URI fragment (”#”), e.g. video.ogv#t=10,20 and those with a URI query (”?”), e.g. video.ogv?t=10,20. There is a fundamental difference between the two that needs to be appreciated: with a URI fragment you can specify a subpart of a resource, e.g. a subpart of a video, while with a URI query you will refer to a different resource, i.e. a “new” video. This is an important difference to understand for media fragments, because only some things that we want to achieve with media fragments can be achieved with ”#”, while others can only be achieved by transforming the resource into a different new bitstream.
This all sounds very abstract, so let me give you an example. Say you want to retrieve a video without its audio track. Say you’d rather not download the audio track data, since you want to save on bandwidth. So, you are only interested to get the video data. The URI that you may want to use is video.ogv#track=video. This means that you don’t want to change the video resource, but you only want to see the video. The user agent (UA) has two options to resolve such a URI: it can either map that request to byte ranges and just retrieve those - or it can download the full resource and ignore the data it has not been requested to display.
Since we do not want the extra bytes of the audio track to be retrieved, we would hope the UA can do the byte range requests. However, most Web video formats will interleave the different tracks of a media resource in time such that a video track will results in a gazillion of smaller byte ranges. This makes it impractical to retrieve just the video through a ”#” media fragment. Thus, if we really want this functionality, we have to make the server more intelligent and allow creation of a new resource from the existing one which doesn’t contain the audio. Then, the server, upon receiving a request such as video.ogv#track=video can redirect that to video.ogv?track=video and actually serve a new resource that satisfies the needs.
This is in fact exactly what was implemented in a recently published Firefox Plugin written by Jakub Sendor - also described in his presentation “Media Fragment Firefox plugin”.
Media Fragment URIs are defined for four dimensions:
temporal fragments
spatial fragments
track fragments
named fragments
The temporal dimension, while not accompanied with another dimension, can be easily mapped to byte ranges, since all Web media formats interleave their tracks in time and thus create the simple relationship between time and bytes.
The spatial dimension is a very complicated beast. If you address a rectangular image region out of a video, you might want just the bytes related to that image region. That’s almost impossible since pixels are encoded both aggregated across the frame and across time. Also, actually removing the context, i.e. the image data outside the region of interest may not be what you want - you may only want to focus in on the region of interest. Thus, the proposal for what to do in the spatial dimension is to simply retrieve all the data and have the UA deal with the display of the focused region, e.g. putting a dark overlay over the regions outside the region of interest.
The track dimension is similarly complicated and here it was decided that a redirect to a URI query would be in order in the demo Firefox plugin. Since this requires an intelligent server - which is available through the Ninsuna demo server that was implemented by Davy Van Deursen, another member of the MF WG - the Firefox plugin makes use of that. If the UA doesn’t have such an intelligent server available, it may again be most useful to only blend out the non-requested data on the UA similar to the spatial dimension.
The named dimension is still a largely undefined beast. It is clear that addressing a named dimension cannot be done together with the other dimensions, since a named dimension can represent any of the other dimensions above, and even a combination of them. Thus, resolving a named dimension requires an understanding of either the UA or the server what the name maps to. If, for example, a track has a name in a media resource and that name is stored in the media header and the UA already has a copy of all the media headers, it can resolve the name to the track that is being requested and take adequate action.
But enough explaining - I have made a screencast of the Firefox plugin in action for all these dimensions, which explains things a lot more concisely than word will ever be able to - enjoy:
Google have today announced the open sourcing of VP8 and the creation of a new media format WebM.
Technical Challenges
As I predicted earlier, Google had to match VP8 with an audio codec and a container format - their choice was a subpart of the Matroska format and the Vorbis codec. To complete the technical toolset, Google have:
developed ffmpeg patches, so an open source encoding tool for WebM will be available
Google haven’t forgotten the mobile space either - a bunch of Hardware providers are listed as supporters on the WebM site and it can be expected that developments have started.
The speed of development of software and hardware around WebM is amazing. Google have done an amazing job at making sure the technology matures quickly - both through their own developments and by getting a substantial number of partners included. That’s just the advantage of being Google rather than a Xiph, but still an amazing achievement.
Browsers
As was to be expected, Google managed to get all the browser vendors that are keen to support open video to also support WebM: Chrome, Firefox and Opera all have come out with special builds today that support WebM. Nice work!
What is more interesting, though, is that Microsoft actually announced that they will support WebM in future builds of IE9 - not out of the box, but on systems where the codec is already installed. Technically, that is be the same situation as it will be for Theora, but the difference in tone is amazing: in this blog post, any codec apart from H.264 was condemned and rejected, but the blog post about WebM is rather positive. It signals that Microsoft recognize the patent risk, but don’t want to be perceived of standing in the way of WebM’s uptake.
Apple have not yet made an announcement, but since it is not on the list of supporters and since all their devices exclusively support H.264 it stands to expect that they will not be keen to pick up WebM.
Publishers
What is also amazing is that Google have already achieved support for WebM by several content providers. The first of these is, naturally, YouTube, which is offering a subset of its collection also in the WebM format and they are continuing to transcode their whole collection. Google also has Brightcov, Ooyala, and Kaltura on their list of supporters, so content will emerge rapidly.
Uptake
So, where do we stand with respect to a open video format on the Web that could even become the baseline codec format for HTML5? It’s all about uptake - if a substantial enough ecosystem supports WebM, it has all chances of becoming a baseline codec format - and that would be a good thing for the Web.
And this is exactly where I have the most respect for Google. The main challenge in getting uptake is in getting the codec into the hands of all people on the Internet. This, in particular, includes people working on Windows with IE, which is still the largest browser from a market share point of view. Since Google could not realistically expect Microsoft to implement WebM support into IE9 natively, they have found a much better partner that will be able to make it happen - and not just on Windows, but on many platforms.
Yes, I believe Adobe is the key to creating uptake for WebM - and this is admittedly something I have completely overlooked previously. Adobe has its Flash plugin installed on more than 90% of all browsers. Most of their users will upgrade to a new version very soon after it is released. And since Adobe Flash is still the de-facto standard in the market, it can roll out a new Flash plugin version that will bring WebM codec support to many many machines - in particular to Windows machines, which will in turn enable all IE9 users to use WebM.
Why would Adobe do this and thus cement its Flash plugin’s replacement for video use by HTML5 video? It does indeed sound ironic that the current market leader in online video technology will be the key to creating an open alternative. But it makes a lot of sense to Adobe if you think about it.
Adobe has itself no substantial standing in codec technology and has traditionally always had to license codecs. Adobe will be keen to move to a free codec of sufficient quality to replace H.264. Also, Adobe doesn’t earn anything from the Flash plugins themselves - their source of income are their authoring tools. All they will need to do to succeed in a HTML5 WebM video world is implement support for WebM and HTML5 video publishing in their tools. They will continue to be the best tools for authoring rich internet applications, even if these applications are now published in a different format.
Finally, in the current hostile space between Apple and Adobe related to the refusal of Apple to allow Flash onto its devices, this may be the most genius means of Adobe at getting back at them. Right now, it looks as though the only company that will be left standing on the H.264-only front and outside the open WebM community will be Apple. Maybe implementing support for Theora wouldn’t have been such a bad alternative for Apple. But now we are getting a new open video format and it will be of better quality and supported on hardware. This is exciting.
IP situation
I cannot, however, finish this blog post on a positive note alone. After reading the review of VP8 by a x.264 developer, it seems possible that VP8 is infringing on patents that are outside the patent collection that Google has built up in codecs. Maybe Google have calculated with the possibility of a patent suit and put money away for it, but Google certainly haven’t provided indemnification to everyone else out there. It is a tribute to Google’s achievement that given a perceived patent threat - which has been the main inhibitor of uptake of Theora - they have achieved such an uptake and industry support around VP8. Hopefully their patent analysis is sound and VP8 is indeed a safe choice.
In recent months, people in the W3C HTML5 Accessibility Task Force developed two proposals for introducing caption, subtitle, and more generally time-aligned text support into HTML5 audio and video.
These time-aligned text files can either come as external files that are associated with the timeline of the media resource, or they come as part of the media resource in a binary track.
For both cases we now have proposals to extend the HTML5 specification.
Firstly, let’s look at time-aligned text in external files. The change proposal introduces markup to associate such external files as a kind of “virtual track” with a media resource. Here is an example: <video src="video.ogv"> <track src="video_cc.ttml" type="application/ttaf+xml" language="en" role="caption"></track> <track src="video_tad.srt" type="text/srt" language="en" role="textaudesc"></track> <trackgroup role="subtitle"> <track src="video_sub_en.srt" type="text/srt; charset='Windows-1252'" language="en"></track> <track src="video_sub_de.srt" type="text/srt; charset='ISO-8859-1'" language="de"></track> <track src="video_sub_ja.srt" type="text/srt; charset='EUC-JP'" language="ja"></track> </trackgroup> </video> The video resource is “video.ogv”. Associated with it are five timed text resources.
The first one is written in TTML (which is the new name for DFXP), is a caption track and in English. TTML is particularly useful when you want to provide more than just an unformatted piece of text to the viewers. Hearing-impaired users appreciate any visual help they can be provided with to absorb the caption text more quickly. This includes colour coding of speakers, positioning of text close to the speaking person on screen, or even animated musical notes to signify music. Thus, a format like TTML that allows for formatting and positioning information is an appropriate format to specify captions.
All other timed text resources are provided in SRT format, which is a simpler format that TTML with only plain text in the text cues.
The second text track is a textual audio description track. A textual audio description is in fact targeted at the vision-impaired and contains text that is expected to be read out by a screen reader or routed to a braille device. Thus, as the video plays, a vision-impaired user receives additional information about the visual content of the scene through their screen reader or braille device. The SRT format is particularly useful for providing textual audio descriptions since it only provides plain text, which can easily be handed on to assistive technology. When authoring such textual audio descriptions, it is very important to pick time intervals in the original media resource where no other significant audio cue is provided, such that the vision-impaired user is able to listen to the screen reader during that time.
The last three text tracks are subtitle tracks. They are grouped into a trackgroup element, which is not strictly necessary, but enables the author to say that these tracks are supposed to be alternatives. Thus, a Web Browser can create a menu with all the available tracks and put the tracks in the trackgroup into a menu of their own where only one option is selectable (similar to how radiobuttons work). Incidentally, the trackgroup element also allows to avoid having to repeat the role attribute in all the containing tracks. It is expected that these menus will be added to the default media controls and will thus be visible if the media element has a controls attribute.
With the role, type and language attributes, it is easy for a Web Browser to understand what the different tracks have to offer. A Web Browser can even decide to offer new functionality that is helpful to certain user groups. For example, an addition to a Web Browser’s default settings could be to allow users to instruct a Web Browser to always turn on captions or subtitles if they are available in the user’s main language. Or to always turn on textual audio descriptions. In this way, a user can customise their default experience of a media resource over and on top of what a Web page author decides to expose.
Incidentally, the choice of “track” as a name for relating external text resources to a media element has a deeper meaning. It is easily possible in future to extend “track” elements to not just point to dependent text resources, but also to dependent audio or video resources. For example, an actual audio description that is a recording of a human voice rather than a rendered text description could be association in the same way. Right now, such an implementation is not envisaged by the Browser vendors, but it will be something to work towards in the future.
Now, with such functionality available, there is naturally a desire to be able to control activation or de-activation of text tracks through JavaScript, not just through user interaction. A Web Developer may for example want to override the default controls provided by a Web Browser and run their own JavaScript-based controls, thus requiring to create their own selection menu for the tracks.
This is actually also an issue more generally and applies to all track types, including such tracks that come inside an existing media resource. In the current specification such tracks are not exposed and can therefore not be activated.
This is where the second specification that the W3C Accessibility Task Force has worked towards comes in: the media multitrack JavaScript API.
This specification introduces a read-only JavaScript interface to the audio and video elements to allow Web Developers to find out about the tracks (including the virtual tracks) that a media resource offers. The only action that the interface currently provides is to enable or disable tracks. Here is an example use to turn on a french subtitle track: if (video.tracks[2].role == "subtitle" && video.tracks[2].language == "fr") video.tracks[2].enabled = true;
There is still a need to introduce a means to actually expose the text cues as they relate to the currentTime of the media resource. This has not yet been specified in the given proposals.
The text cues could be exposed in several ways. They could be exposed through introducing an event, i.e. every time a new text cue becomes active, a callback is called which is given the active text cue (if such a callback had been registered previously). Another option is to simply write the text cues into a specified div-element in the DOM and thus expose them directly in the Browser. A third idea could be to expose the text cues in an iframe-like element to avoid any cross-site security issues. And a fourth idea that we have discussed is to expose the text cues in an attribute of the track.
All of this obviously also relates to how to actually render the text cues and whether to render them in a shadow DOM so as to make the JavaScript reading separate from the rendering and address security and copyright issues. I’d be curious in opinions here on how it should be done.
Recently, I was asked to review the W3C Media Annotations specifications as they are about to go into Last Call (a state that comes before the request for implementations at the W3C).
The W3C Media Annotations group has defined a set of metadata that they believe is representative and common for media resources. The ontology consist of the following fields:
ma:identifier: a URI or string to identify a resource
ma:title: a string providing the title of the resource
ma:language: a language code describing the language used in the resource
ma:locator: the URI at which the resource can be accessed
ma:contributor: a URI or string identifying the contributor and the nature of the contribution
ma:creator: a URI or string identifying an author
ma:createDate: a date of creation or publication of the resource
ma:location: a string or geo code identifying where the resource has been shot/recorded
ma:description: a string describing the content of the resource
ma:keyword: a word or word combination providing a topic, keyword or tag representing the resource
ma:genre: a string providing the genre of the resource
ma:rating: rating value, including the rating scale
ma:relation: a URI and string identifying a related resource and the relationship
ma:collection: a URI or string providing the name of a collection to which the resource belongs
ma:copyright: a URI or string with the copyright statement.
ma:license: a string or URI with the usage license
ma:publisher: a string or URI with the publisher of the resource
ma:targetAudience: a URI and classification string providing the issuer of the classification and the classification value
ma:fragments: a list of string and URI values that identify media fragments and their type
ma:namedFragments: a list of string and URI values the provide names to media fragments
ma:frameSize: a width - height pair in pixels
ma:compression: a string providing the compression algorithm
ma:duration: a float to provide the resource duration in seconds
ma:format String: the mime type of the resource
ma:samplingrate: a float with the audio sampling rate
ma:framerate: a float with the video frame rate
ma:bitrate: a float providing the average bit rate in kbps
ma:numTracks: an int of the number of tracks
Note that some of these fields are not single values, but simple constructs of multiple values. Thus, they are actually more complex than name-value pairs that, e.g. are typically used in HTML meta headers or in Dublin Core. I regard this as an issue for implementations.
The fields were chosen as typical metadata being available about media resources. The media fragments fields are a bit dubious in this respect, but could be useful in future.
The metadata is determined either from within the resource itself or from a metadata collection about the resource. As such, the document maps several existing metadata and media resource formats to this interface, amongst them:
As they didn’t have a mapping table for Ogg content, I offered the following:
MAWG
Relation
Ogg properties
How to do the mapping
Datatype
Descriptive Properties (Core Set)
Identification
ma:identifier
exact
Name
Name field in skeleton header (new)
String
ma:title
exact
Title
TITLE field in vorbiscomment header
String
exact
Title
Title field in skeleton header (new)
String
related
Album
ALBUM title in vorbiscomment header
String
ma:language
exact
Language
Language field in skeleton header (new)
language code
ma:locator
exact
file URI from system
URI
Creation
ma:contributor
exact
Artist, Performer
ARTIST and PERFORMER vorbiscomment headers
Strings
ma:creator
related
Organization
ORGANIZATION field in vorbiscomment header
ma:createDate
exact
Date
DATE field in vorbiscomment header
ISO date format
ma:location
exact
Location
LOCATION field in vorbiscomment header
String
Content description
ma:description
exact
Description
DESCRIPTION field in vorbiscomment header
String
ma:keyword
N/A
ma:genre
exact
Genre
GENRE field in vorbiscomment header
String
ma:rating
N/A
Relational
ma:relation
related
Version, Tracknumber
VERSION (version of a title), TRACKNUMBER (CD track) fields in vorbiscomment header
Strings
ma:collection
related
Album
ALBUM field of vorbiscomment header
String
Rights
ma:copyright
exact
Copyright
COPYRIGHT field of vorbiscomment header
String
ma:license
exact
License
LICENSE field of vorbiscomment header
String
Distribution
ma:publisher
related
Organization
ORGNIZATION field of vorbiscomment header
String
ma:targetAudience
more specific
Role
Role field of Skeleton header (new)
String
Fragments
ma:fragments
N/A
ma:namedFragments
N/A
Technical Properties
ma:frameSize
exact
extract from binary header of video track
int, int (width x height)
ma:compression
exact
Content-type
Content-type field of Skeleton header
MIME type
ma:duration
exact
calculate as duration = last_sample_time - first_sample_time of OggIndex header of skeleton
Float (or rather: rational - rational)
ma:format
exact
Content-type
Content-type field of Skeleton header
MIME type
ma:samplingrate
exact
calculate as granulerate = granulerate_numerator / granulerate_denominator of Skeleton header
Rational (or rather int / int)
ma:framerate
exact
calculate as granulerate = granulerate_numerator / granulerate_denominator of Skeleton header
Rational (or rather int / int)
ma:bitrate
exact
calculate as bitrate = length_of_segment / duration from OggIndex headers of skeleton
Float
ma:numTracks
exact
Tracknumber
TRACKNUMBER field of vorbiscomment header (track number on album)
Int
You will notice that the table mentions 4 fields in skeleton with a “new” marker - they are actually proposed fields in skeleton - a bit of coding will be necessary to introduce them into software. The space for these fields already exists in message header fields, so it won’t require a change of the skeleton format.
In the second specification of the Media Annotations WG, the group offers a standard API to access (i.e. read) the defined fields. They also intend to create an API to write the fields, but I doubt that will be easy because of the vast amount of file types they intend to support.
There is basically a single function that allows the extraction of metadata: MAObject[] getProperty(in DOMString propertyName, in optional DOMString sourceFormat, in optional DOMString subtype, in optional DOMString language, in optional DOMString fragment );
I proposed it may be possible to include this into HTML5 as follows: interface HTMLMediaElement : HTMLElement { ... getter MAObject getProperty(in DOMString propertyName, in optional unsigned long trackIndex); ... }
This would either extract the property for a particular track in a media resource or for the complete resource if no track index is given. The only problem I see is that the returned object is different depending on the requested property - the MAObject is only a parent class for the returned object types. I am not sure it is therefore possible to specify this easily in HTML5.
Overall I thought the specification was a nice piece of work. I am not sure I agree with all the chosen fields, but that is always an issue with metadata. The most important fields are there and that’s what matters.
Today, I was invited to give a talk at my old workplace CSIRO about the HTML5 media elements and accessibility.
A lot of the things that have gone into Ogg and that are now being worked on in the W3C in different working groups - including the Media Fragments and HTML5 WGs - were also of concern in the Annodex project that I worked on while at CSIRO. So I was rather excited to be able to report back about the current status in HTML5 and where we’re at with accessibility features.
Check out the presentation here. It contains a good collection of links to exciting demos of what is possible with the new HTML5 media elements when combined with other HTML features.
I tried something now with this presentation: I wrote it in a tool called S5, which makes use only of HTML features for the presentation. It was quite a bit slower than I expected, e.g. reloading a page always included having to navigate to that page. Also, it’s not easily possible to do drawings, unless you are willing to code them all up in HTML. But otherwise I have found it very useful for, in particular, including all the used URLs and video element demos directly in the slides. I was inspired with using this tool by Chris Double’s slides from LCA about implementing HTML 5 video in Firefox.
—\n 189823\n\n17753616 bbb_youtube_h264_499kbit.mp4\n13898515 bbb_youtube_h264_499kbit.h264\n 3796188 bbb_youtube_h264_499kbit.aac\n--------\n 58913\n\nI hope you believe me now..”
parent: 0
id: 607
author: “DonDiego”
authorUrl: ""
date: “2010-02-25 09:31:12”
content: “@Louise: FLV and MP4 are general-purpose container formats that can contain audio, video, subtitles and metadata in a variety of flavors.”
parent: 0
id: 608
author: “Monty”
authorUrl: “http://xiph.org”
date: “2010-02-25 10:53:24”
content: “DonDiego, you troll this every chance you get. I’m getting tired of addressing it in one place, having the rebuttal entirely ignored, and then having you plaster it somewhere else, anywhere else that’s visible.\n\nOgg is different from your favorite container. We know. It does not need to be extended for every new codec. It’s a transport layer that does not include metadata (that’s for Skeleton). Mp4 and Nut make metadata part of a giant monolithic design. Whoop-de-do. The overhead depends on how it’s being used (for the high bitrate BBB above, it’s using a tiny page size tuned to low bitrate vids, an aspect of the encoder that produced it, not Ogg itself). Etc, etc. \n\nDoing something different than the way you and your group would do it is not ‘horribly flawed’ it is just… different.\n\nWe’re not dropping Ogg and breaking tens of millions of decoders to use mp4 or Nut just because a few folks are angry that their pet format came too late or because your country doesn’t have software patents. Where I live, patents exist. You’re free to do anything that you want with the codecs, of course. Go ahead and put them in MOV or Nut! As you loudly proclaim, you’re in a country that doesn’t have software patents, so you don’t have to care.\n\nOr, “for the love of all that is holy”, get over it. Last I checked you weren’t willing to use Theora either… so why exactly are you here…? Obvious troll is obvious.”
parent: 0
id: 609
author: “Chris Smart”
authorUrl: “http://blog.christophersmart.com”
date: “2010-02-25 11:12:47”
content: “@DonDiego\nPage 93 of the ISO Base File Format standard states that Apple, Matsushita and Telefonaktiebolaget LM Ericsson assert patents in relation to this format.\n\nHere’s the standard:\nhttp://standards.iso.org/ittf/PubliclyAvailableStandards/c051533_ISO_IEC_14496-12_2008.zip\n\n-c”
parent: 0
id: 610
author: “Monty”
authorUrl: “http://xiph.org”
date: “2010-02-25 11:39:57”
content: “Since I have to rebut this again lest it grow legs:\n\nFor the record, If I was redesigning the Ogg container today, I’d consider changing two things:\n\n1) The specific packet length encoding encoding tops out at an overhead efficiency of .5%. If you accept an efficiency hit on small packet sizes, you can improve large packet size efficiency. This is one of the things Diego is ranting about. We actually had an informal meeting about this at FOMS in 2008. We decided that breaking every Ogg decoder ever shipped was not worth a theoretical improvement of .3% (depending on usage).\n\n2) Ogg page checksums are whole-page and mandatory. Today I’d consider making them switchable, where they can either cover the whole page or just the page header. It would optionally reduce the computational overhead for streams where error detection is internal to the codec packet format, or for streams where the user encoding does not care about error detection. Again— not worth breaking the entire install base. \n\nAt FOMS we decided that if we were starting from scratch, the first was a good idea and we were split on the checksums. But we’re not starting from scratch, and compatibility/interop is paramount.\n\nThe third big thing Diego (and the mplayer community in general) hate is the intentional, conscious decision to allow a codec to define how to parse granule positions for that codec’s stream. Granpos parsing thus requires a call into the codec. \n\nThe practical consequence: When an Ogg file contains a stream for which a user doesn’t have the codec installed… they can’t decode the stream! gasp Wait… how is that different from any other system? \n\nWhat’s different is that the demuxer also can’t parse the timestamps on those pages that wouldn’t be decodable anyway. Also, see above, parsing a timestamp requires a call to the installed codec. The mplayer mux layer can’t cope with this design, and they won’t change the player. We’re supposed to change our format instead.\n\nFourth cited difference is that Ogg is transport only and stream metadata is in Skeleton (or some other layer sitting inside the low level Ogg transport stream) rather than part of a monolithic stream transport design. Practical difference? None really. Except that their mux/demux design can’t handle it, and they’re not interested in changing that either.\n\nI hope this clarifies the years of sustained anti-Ogg vitriol from the Mplayer and spin-off communities. Could Ogg be improved? Sure! Is that a reason to burn everything and start over? DonDiego seems to think so.”
parent: 0
id: 611
author: “Chris Smart”
authorUrl: “http://blog.christophersmart.com”
date: “2010-02-25 11:41:42”
content: “@DonDiego\n\nYour assertion that FLV supports a variety of is not quite true (depends on your definition of “variety” - having “two” could be considered “variety”).\n\nAccording to the spec (“http://www.adobe.com/devnet/flv/pdf/video_file_format_spec_v10.pdf\”), FLV only supports the following Audio formats:\nPCM\nMP3\nNollymoser\nG.711\nAAC\nSpeex\n\nLikewise, only a few video formats are supported, namely:\nVP6\nH.263\nH.264\n\nMost importantly, it does not support free video and audio formats such as Theora and Vorbis.\n\n-c”
parent: 0
id: 612
author: “Multimedia Mike”
authorUrl: “http://multimedia.cx/eggs/”
date: “2010-02-25 12:14:31”
content: “@Chris Smart: Technically, there’s nothing preventing FLV from supporting a much larger set of audio and video codecs. However, it’s generally only useful to encode codecs that the Adobe Flash Player natively supports since that’s the primary use case for FLV. Adding support for another codec is generally just a matter of deciding on a new unique ID for that codec.\n\nDeciding on a new unique ID for a codec is usually all that’s necessary for adding support for a new codec to a general-purpose container format. It’s why AVI is still such a catch-all format— just think of a new unique ID (32-bit FourCC) for your experimental codec.\n\nThe beef we have with Ogg is — as Monty eloquently describes in his comment — that Ogg increases the coupling between container and codec layers. This adds complexity that most multimedia systems don’t have to deal with.”
parent: 0
id: 613
author: “Louise”
authorUrl: ""
date: “2010-02-25 12:17:03”
content: “@Monty\n\nVery interesting read!!\n\nIt is scary how a container that is suppose to free us from the proprietary containers, can be so bad.\n\nI found this blog from a x264 developer\nhttp://x264dev.multimedia.cx/?p=292\n\nwhich had this to say about ogg:\n\n[quote]\nMKV is not the best designed container format out there (it”
parent: 0
id: 614
author: “Multimedia Mike”
authorUrl: “http://multimedia.cx/eggs/”
date: “2010-02-25 12:23:01”
content: “@Louise: “Do you think VP8 would be back wards compatible if it contains 3rd party patents, and they were removed?”\n\nBackwards compatible with what?”
parent: 0
id: 615
author: “Monty”
authorUrl: “http://xiph.org”
date: “2010-02-25 14:08:36”
content: ”> It is scary how a container that is suppose to free us from the \n> proprietary containers, can be so bad.\n\nIt isn’t. It is very different from one what set of especially pretentious wonks expects and they’ve been wanking about it for coming up on a decade. None of this makes an ounce of difference to users, and somehow other software groups don’t seem to have any trouble with Ogg. For such a fatally flawed system, it seems to work pretty well in practice :-P\n\nSuggestions like ‘They should have just used MKV’ doesn’t make sense. Ogg predates MKV by many years, and interleave is a fairly recent feature in MKV. \n\nThe format designed by the mplayer folks is named Nut. Despite many differences in the details, the system it resembles most closely… is Ogg. Subjective evaluation of course, but I always considered the resemblance uncanny. \n\nLast of all, suppose just out of old fashioned spite and frustration, Xiph says ‘No more Ogg for the container! We use Nut now!’ That… pretty much ends FOSS’s practical chances of having any relevance in web video or really any net multimedia for the forseeable future. …all to get that .3% and a design change under the blankets that no user could ever possibly care about. Sign me up!”
parent: 0
id: 616
author: “silvia”
authorUrl: “http://blog.gingertech.net/”
date: “2010-02-25 20:39:55”
content: “@DonDiego To be fair, in your file size example, you should provide the correct sums:\n\n== quote\n17307153 bbb_theora_486kbit.ogv\n15009926 bbb_theora_486kbit.theora\n2107404 bbb_theora_486kbit.vorbis\n”
parent: 0
id: 617
author: “Louise”
authorUrl: ""
date: “2010-02-25 21:20:28”
content: “@Monty\n\nWas NUT designed before MKV was released?”
parent: 0
id: 618
author: “DonDiego”
authorUrl: ""
date: “2010-02-25 22:39:45”
content: “@silvia: I am providing the correct sums! You are misreading my table. Let me reformat the table slightly and pad with zeroes for readability:\n\n 17307153 bbb_theora_486kbit.ogv (the complete file)\n- 15009926 bbb_theora_486kbit.theora (the video track)\n- 02107404 bbb_theora_486kbit.vorbis (the audio track)\n ========\n 00189823 (container overhead)\n\n 17753616 bbb_youtube_h264_499kbit.mp4 (the complete file)\n- 13898515 bbb_youtube_h264_499kbit.h264 (the video track)\n- 03796188 bbb_youtube_h264_499kbit.aac (the audio track)\n ========\n 00058913 (container overhead)\n\nSo in this application, Ogg has more than 300% the overhead of MP4. Ogg is known to produce large overhead, but I did not expect this order of magnitude. Now I believe Monty that it’s possible to reduce this, but the purpose of Greg’s comparison was to test this particular configuration without additional tweaks. Otherwise the H.264 and AAC encoding settings could be tweaked further as well…\n\nI wonder what you tested when you say that in your experience Ogg files come out smaller than MPEG files. The term “MPEG files” is about as broad as it gets in the multimedia world. Yes, the MPEG-TS container has very high overhead, but it is designed for streaming over lossy sattelite links. This special purpose warrants the overhead tradeoff.”
parent: 0
id: 619
author: “DonDiego”
authorUrl: ""
date: “2010-02-25 22:44:32”
content: “@louise: NUT was designed after Matroska already existed.”
parent: 0
id: 620
author: “Monty”
authorUrl: “http://www.xiph.org/”
date: “2010-02-26 08:16:54”
content: “Silvia: DonDiego was illustrating a broken-out subtraction. His numbers are correct, as is his claim; Ogg is introducing more overhead (1%). That’s almost certainly reduceable, but I’ve not looked at the page structure in Vorbose to be sure of that claim. .5%-.7% is the intended working range. It climbs if the muxer is splitting too many packets or the packets are just too small (not the case here).\n\n>So in this application, Ogg has more than 300% the overhead of MP4. \n>Ogg is known to produce large overhead, but I did not expect this \n>order of magnitude.\n\nYes, Ogg is using more overhead. Let’s assume that a better muxer gets me .7% overhead (yeah, even our own muxer is overly straightforward and doesn’t try anything fancy; it hasn’t been updated since 1998 or so. “Have to extend to container for every new codec” jeesh…)\n\nSo this is really a screaming fight over the difference between .7% and .3%? \n\nI don’t debate for a second that Nut’s packet length encoding is better, and that’s the lion’s share of the difference assuming the file is muxed properly. And if/when (long term view, ‘when’ is almost certainly correct) Ogg needs to be refreshed in some way that has to break spec anyway, the Nut packet encoding will be one of the first things added because at that point it’s a ‘why not?’. But until then there’s no sensible way to defend the havoc a container change would wreak and all for reducing a .7% bitstream overhead down to .3%. It would be optimising something completely insignificant at great practical cost.”
parent: 0
id: 621
author: “silvia”
authorUrl: “http://blog.gingertech.net/”
date: “2010-02-26 10:07:54”
content: “@monty, @DonDiego thanks for the clarifications”
parent: 0
id: 622
author: “DonDiego”
authorUrl: ""
date: “2010-02-26 11:43:00”
content: “@Monty: You are giving me far too much credit! “for the love of all that is holy and some that is not, don’t do that” is a quote from Mans in reply to somebody proposing to add ‘#define _GNU_SOURCE’ to FFmpeg. I have been looking for an opportunity to steal that phrase and take credit as being funny for a long time. SCNR ;-p\n\nSpeaking of memorable quotes I cannot help but point at the following classic out of your feather after trying and failing to get patches into MPlayer:\nhttp://lists.mplayerhq.hu/pipermail/mplayer-dev-eng/2007-November/054865.html\n\n======\nFine. I give up.\n\nThere are plenty of things about the design worth arguing about… but\nyou guys are more worried about the color of the mudflaps on this\ndumptruck. You’re rejecting considered decisions out of hand with\nvague, irrelevant dogma. I’ve seen two legitimate bugs brought up so\nfar in a mountain of “WAAAH! WE DON’T LIKE YOUR INDEEEEENT.”\n\nI have the only mplayer/mencoder on earth that can always dump WMV2\nand WMV3 without losing sync. I just needed it for me. I thought it\nwould be nice to submit it for all your users who have been asking for\nthis for years. But it just ceased being worth it.\n\nPatch retracted. You can all go fuck yourselves. Life is too short\nfor this asshattery.\n\nMonty\n=====\n\nWe remember you fondly. I and many others didn’t know what asshat meant before, but now it found a place in everybody’s active vocabulary. I’m not being ironic BTW, sometimes nothing warms the heart more than a good flame and few have generated more laughter than yours :-)\n\nThe ironic thing is that your fame brought you attention and the attention brought detailed reviews, which made patch acceptance harder.\n\nI also failed getting patches into Tremor. You rejected them for silly reasons, but, admittedly, I did not have the energy to flame it through…\n\nFor the record: I have no vested interest in NUT. Some of the comments above could be read to suggest that Ogg would be a good base when starting from a clean slate. This is wrong, Ogg is the weakest part of the Xiph stack. You know that, but there are people all around the internet proclaiming otherwise. This does not help your case, on the contrary, so I try to inject facts into the discussion. Admittedly, sometimes I do it with a little bit of flair of my own ;-)\n\nCheers, Diego”
parent: 0
id: 623
author: “Monty”
authorUrl: “http://www.xiph.org/”
date: “2010-02-26 12:06:52”
content: “@DonDiego\n\na) I was indeed bucking up against rampant asshattery.\n\nb) Not sure how any of that is even slightly relevant to this thread.\n\nYou’re bringing it up in some sort of attempt to shame or embarrass because you’ve lost on facts? For the record, I meant it when I said it then, and I don’t feel any differently now. And asshat is indeed a fabulous word.\n\n[FTR, you’ve had two patches rejected and several more accepted if the twelve hits from Xiph.Org Trac are a complete set.]\n\nMonty”
parent: 0
id: 624
author: “silvia”
authorUrl: “http://blog.gingertech.net/”
date: “2010-02-26 12:12:01”
content: “This blog is not for personal attacks, but only for discussing technical issues. Unfortunately, the discussion on these comments is developing in a way that I cannot support any longer. I have therefore decided to close comments.\n\nThank you everyone for your contributions.”
parent: 0
I am sure Google is thinking about it. But … what does “it” mean?
Freeing VP8 Simply open sourcing it and making it available under a free license doesn’t help. That just provides open source code for a codec where relevant patents are held by a commercial entity and any other entity using it would still need to be afraid of using that technology, even if it’s use is free.
So, Google has to make the patents that relate to VP8 available under an irrevocable, royalty-free license for the VP8 open source base, but also for any independent implementations of VP8. This at least guarantees to any commercial entity that Google will not pursue them over VP8 related patents.
Now, this doesn’t mean that there are no submarine or unknown patents that VP8 infringes on. So, Google needs to also undertake an intensive patent search on VP8 to be able to at least convince themselves that their technology is not infringing on anyone else’s. For others to gain that confidence, Google would then further have to indemnify anyone who is making use of VP8 for any potential patent infringement.
I believe - from what I have seen in the discussions at the W3C - it would only be that last step that will make companies such as Apple have the confidence to adopt a “free” codec.
An alternative to providing indemnification is the standardisation of VP8 through an accepted video standardisation body. That would probably need to be ISO/MPEG or SMPTE, because that’s where other video standards have emerged and there are a sufficient number of video codec patent holders involved that a royalty-free publication of the standard will hold a sufficient number of patent holders “under control”. However, such a standardisation process takes a long time. For HTML5, it may be too late.
Technology Challenges Also, let’s not forget that VP8 is just a video codec. A video codec alone does not encode a video. There is a need for an audio codec and a encapsulation format. In the interest of staying all open, Google would need to pick Vorbis as the audio codec to go with VP8. Then there would be the need to put Vorbis and VP8 in a container together - this could be Ogg or MPEG or QuickTime’s MOOV. So, apart from all the legal challenges, there are also technology challenges that need to be mastered.
It’s not simple to introduce a “free codec” and it will take time!
Google and Theora There is actually something that Google should do before they start on the path of making VP8 available “for free”: They should formulate a new license agreement with Xiph (and the world) over VP3 and Theora. Right now, the existing license that was provided by On2 Technologies to Theora (link is to an early version of On2’s open source license of VP3) was only for the codebase of VP3 and any modifications of it, but doesn’t in an obvious way apply to an independent re-implementations of VP3/Theora. The new agreement between Google and Xiph should be about the patents and not about the source code. (UPDATE: The actual agreement with Xiph apparently also covers re-implementations - see comments below.)
That would put Theora in a better position to be universally acceptable as a baseline codec for HTML5. It would allow, e.g. Apple to make their own implementation of Theora - which is probably what they would want for ipods and iphones. Since Firefox, Chrome, and Opera already support Ogg Theora in their browsers using the on2 licensed codebase, they must have decided that the risk of submarine patents is low. So, presumably, Apple can come to the same conclusion.
Free codecs roadmap I see this as the easiest path towards getting a universally acceptable free codec. Over time then, as VP8 develops into a free codec, it could become the successor of Theora on a path to higher quality video. And later still, when the Internet will handle large resolution video, we can move on to the BBC’s Dirac/VC2 codec. It’s where the future is. The present is more likely here and now in Theora.
ADDITION: Please note the comments from Monty from Xiph and from Dan, ex-On2, about the intent that VP3 was to be completely put into the hands of the community. Also, Monty notes that in order to implement VP3, you do not actually need any On2 patents. So, there is probably not a need for Google to refresh that commitment. Though it might be good to reconfirm that commitment.
ADDITION 10th April 2010: Today, it was announced that Google put their weight behind the Theorarm implementation by helping to make it BSD and thus enabling it to be merged with Theora trunk. They also confirm on their blog post that Theora is “really, honestly, genuinely, 100% free”. Even though this is not a legal statement, it is good that Google has confirmed this.
At the recent FOMS/LCA in Wellington, New Zealand, we talked a lot about how Ogg could support accessibility. Technically, this means support for multiple text tracks (subtitles/captions), multiple audio tracks (audio descriptions parallel to main audio track), and multiple video tracks (sign language video parallel to main video track).
Creating multitrack Ogg files The creation of multitrack Ogg files is already possible using one of the muxing applications, e.g. oggz-merge. For example, I have my own little collection of multitrack Ogg files at http://annodex.net/~silvia/itext/elephants_dream/multitrack/. But then you are stranded with files that no player will play back.
Multitrack Ogg in Players As Ogg is now being used in multiple Web browsers in the new HTML5 media formats, there are in particular requirements for accessibility support for the hard-of-hearing and vision-impaired. Either multitrack Ogg needs to become more of a common case, or the association of external media files that provide synchronised accessibility data (captions, audio descriptions, sign language) to the main media file needs to become a standard in HTML5.
As it turn out, both these approaches are being considered and worked on in the W3C. Accessibility data that are audio or video tracks will in the near future have to come out of the media resource itself, but captions and other text tracks will also be available from external associated elements.
The availability of internal accessibility tracks in Ogg is a new use case - something Ogg has been ready to do, but has not gone into common usage. MPEG files on the other hand have for a long time been used with internal accessibility tracks and thus frameworks and players are in place to decode such tracks and do something sensible with them. This is not so much the case for Ogg.
For example, a current VLC build installed on Windows will display captions, because Ogg Kate support is activated. A current VLC build on any other platform, however, has Ogg Kate support deactivated in the build, so captions won’t display. This will hopefully change soon, but we have to look also beyond players and into media frameworks - in particular those that are being used by the browser vendors to provide Ogg support.
Multitrack Ogg in Browsers Hopefully gstreamer (which is what Opera uses for Ogg support) and ffmpeg (which is what Chrome uses for Ogg support) will expose all available tracks to the browser so they can expose them to the user for turning on and off. Incidentally, a multitrack media JavaScript API is in development in the W3C HTML5 Accessibility Task Force for allowing such control.
The current version of Firefox uses liboggplay for Ogg support, but liboggplay’s multitrack support has been sketchy this far. So, Viktor Gal - the liboggplay maintainer - and I sat down at FOMS/LCA to discuss this and Viktor developed some patches to make the demo player in the liboggplay package, the glut-player, support the accessibility use cases.
I applied Viktor’s patch to my local copy of liboggplay and I am very excited to show you the screencast of glut-player playing back a video file with an audio description track and an English caption track all in sync:
Further developments There are still important questions open: for example, how will a player know that an audio description track is to be played together with the main audio track, but a dub track (e.g. a German dub for an English video) is to be played as an alternative. Such metadata for the tracks is something that Ogg is still missing, but that Ogg can be extended with fairly easily through the use of the Skeleton track. It is something the Xiph community is now working on.
Summary This is great progress towards accessibility support in Ogg and therefore in Web browsers. And there is more to come soon.
Recently, I was asked for some help on coding with an HTML5 video element and its events. In particular the question was: how do I display the time position that somebody seeked to in a video?
Here is a code snipped that shows how to use the seeked event:
<video onseeked="writeVideoTime(this.currentTime);" src="video.ogv" controls></video> <p>position:</p><div id="videotime"></div> <script type="text/javascript"> // get video element var video = document.getElementsByTagName("video")[0]; function writeVideoTime(t) { document.getElementById("videotime").innerHTML=t; } </script>
Other events that can be used in a similar way are:
loadstart: UA requests the media data from the server
progress: UA is fetching media data from the server
suspend: UA is on purpose idling on the server connection mid-fetching
abort: UA aborts fetching media data from the server
error: UA aborts fetching media because of a network error
emptied: UA runs out of network buffered media data (I think)
stalled: UA is waiting for media data from the server
play: playback has begun after play() method returns
pause: playback has been paused after pause() method returns
loadedmetadata: UA has received all its setup information for the media resource, duration and dimensions and is ready to play
loadeddata: UA can render the media data at the current playback position for the first time
waiting: playback has stopped because the next frame is not available yet
playing: playback has started
canplay: playback can resume, but at risk of buffer underrun
canplaythrough: playback can resume without estimated risk of buffer underrun
seeking: seeking attribute changed to true (may be too short to catch)
seeked: seeking attribute changed to false
timeupdate: current playback position changed enough to report on it
ended: playback stopped at media resource end; ended attribute is true
ratechange: defaultPlaybackRate or playbackRate attribute have just changed
durationchange: duration attribute has changed
volumechange:volume attribute or the muted attribute has changed
I have talked a lot about synchronising multiple tracks of audio and video content recently. The reason was mainly that I foresee a need for more than two parallel audio and video tracks, such as audio descriptions for the vision-impaired or dub tracks for internationalisation, as well as sign language tracks for the hard-of-hearing.
It is almost impossible to introduce a good scheme to deliver the right video composition to a target audience. Common people will prefer bare a/v, vision-impaired would probably prefer only audio plus audio descriptions (but will probably take the video), and the hard-of-hearing will prefer video plus captions and possibly a sign language track . While it is possible to dynamically create files that contain such tracks on a server and then deliver the right composition, implementation of such a server method has not been very successful in the last years and it would likely take many years to roll out such new infrastructure.
So, the only other option we have is to synchronise completely separate media resource together as they are selected by the audience.
I created a Ogg video with only a video track (10m53s750). Then I created an audio track that is the original English audio track (10m53s696). Then I used a Spanish dub track that I found through BlenderNation as an alternative audio track (10m58s337). Lastly, I created an audio description track in the original language (10m53s706). This creates a video track with three optional audio tracks.
I took away all native controls from these elements when using the HTML5 audio and video tag and ran my own stop/play and seeking approaches, which handled all media elements in one go.
I was mostly interested in the quality of this experience. Would the different media files stay mostly in sync? They are normally decoded in different threads, so how big would the drift be?
The resulting page is the basis for such experiments with synchronisation.
The page prints the current playback position in all of the media files at a constant interval of 500ms. Note that when you pause and then play again, I am re-synching the audio tracks with the video track, but not when you just let the files play through.
I have let the files play through on my rather busy Macbook and have achieved the following interesting drift over the course of about 9 minutes:
You will see that the video was the slowest, only doing roughly 540s, while the Spanish dub did 560s in the same time.
To fix such drifts, you can always include regular re-synchronisation points into the video playback. For example, you could set a timeout on the playback to re-sync every 500ms. Within such a short time, it is almost impossible to notice a drift. Don’t re-load the video, because it will lead to visual artifacts. But do use the video’s currentTime to re-set the others. (UPDATE: Actually, it depends on your situation, which track is the best choice as the main timeline. See also comments below.)
It is a workable way of associating random numbers of media tracks with videos, in particular in situations where the creation of merged files cannot easily be included in a workflow.
The report explains the Australian Government’s existing regulatory framework for accessibility to audio-visual content on TV, digital TV, DVDs, cinemas, and the Internet, and provides an overview about what it is planning to do over the next 3-5 years.
It is interesting to read that according to the Australian Bureau of Statistics about 2.67 million Australians - one in every eight people - have some form of hearing loss and 284,000 are completely or partially blind. Also, it is expected that these numbers will increase with an ageing population and obesity-linked diabetes are expected to continue to increase these numbers.
For obvious reasons, I was particularly interested in the Internet-related part of the report. It was the second-last section (number five), and to be honest, I was rather disappointed: only 3 pages of the 40 page long report concerned themselves with Internet content. Also, the main message was that “at this time the costs involved with providing captions for online content were deemed to represent an undue financial impost on a relatively new and developing service.”
Audio descriptions weren’t even touched with a stick and both were written off with “a lack of clear online caption production and delivery standard and requirements”. There is obviously a lot of truth to the statements of the report - the Internet audio-visual content industry is still fairly young compared to e.g. TV, and there are a multitude of standards rather than a single clear path.
However, I believe the report neglected to mention the new HTML5 video and audio elements and the opportunity they provide. Maybe HTML5 was excluded because it wasn’t expected to be relevant within the near future. I believe this is a big mistake and governments should pay more attention to what is happening with HTML5 audio and video and the opportunities they open for accessibility.
In the end, I made a submission because I wanted the Australian Government to wake up to the HTML5 efforts and I wanted to correct a mistake they made with claiming MPEG-2 was “not compatible with the delivery of closed audio descriptions”.
I believe a lot more can be done with accessibility for Internet content than just “monitor international developments” and industry partnership with disability representative groups. I therefore proposed to undertake trials in particular with textual audio descriptions to see if they could be produced in a similar manner to captions, which would make their cost come down enormously. Also I suggested actually aiming for WCAG 2.0 conformance within the next 5 years - which for audio-visual content means at minimum captions and audio descriptions.
You can read the report here and my 4 page long submission here.
We basically taught people how to create and publish Ogg Theora video in HTML5 Web pages and how to make them work across browsers, including much of the available tools and libraries. We’re hoping that some people will have learnt enough to include modules in CMSes such as Drupal, Joomla and Wordpress, which will easily support the publishing of Ogg Theora.
I have been asked to share the material that we used. It consists of:
Vimeo started last week with a HTML5 beta test. They use the H.264 codec, probably because much of their content is already in this format through the Flash player.
But what really surprised me was their claim that roughly 25% of their users will be able to make use of their HTML5 beta test. The statement is that 25% of their users use Safari, Chrome, or IE with Chrome Frame. I wondered how they got to that number and what that generally means to the amount of support of H.264 vs Ogg Theora on the HTML5-based Web.
According to Statcounter’s browser market share statistics, the percentage of browsers that support HTML5 video is roughly: 31.1%, as summed up from Firefox 3.5+ (22.57%), Chrome 3.0+ (5.21%), and Safari 4.0+ (3.32%) (Opera’s recent release is not represented yet).
Out of those 31.1%,
8.53% browsers support H.264
and
27.78% browsers support Ogg Theora.
Given these numbers, Vimeo must assume that roughly 16% of their users have Chrome Frame in IE installed. That would be quite a number, but it may well be that their audience is special.
So, how is Ogg Theora support doing in comparison, if we allow such browser plugins to be counted?
With an installation of XiphQT, Safari can be turned into a browser that supports Ogg Theora. The Chome Frame installation will also turn IE into a Ogg Theora supporting browser. These could get the browser support for Ogg Theora up to 45%. Compare this to a claimed 48% of MS Silverlight support.
But we can do even better for Ogg Theora. If we use the Java Cortado player as a fallback inside the video element, we can capture all those users that have Java installed, which could be as high as 90%, taking Ogg Theora support potentially up to 95%, almost up to the claimed 99% of Adobe Flash.
I’m sure all these numbers are disputable, but it’s an interesting experiment with statistics and tells us that right now, Ogg Theora has better browser support than H.264.
UPDATE: I was told this article sounds aggressive. By no means am I trying to be aggressive - I am stating the numbers as they are right now, because there is a lot of confusion in the market. People believe they reach less audience if they publish in Ogg Theora compared to H.264. I am trying to straighten this view.
You probably heard it already: Linux.conf.au is live streaming its video in a Microsoft proprietary format.
Fortunately, there is now a re-broadcast that you can get in an open format from http://stream.v2v.cc:8000/ . It comes from a server in Europe, but relies on transcoding here in New Zealand, so it may not be completely reliable.
Today, the down under open source / Linux conference linux.conf.au in Wellington started with the announcement that every talk and mini-conf will be live streamed to the Internet and later published online. That’s an awesome achievement!
However, minutes after the announcement, I was very disappointed to find out that the streams are actually provided in a proprietary format and through a proprietary streaming protocol: a Microsoft streaming service that provides Windows media streams.
Why stream an open source conference in a proprietary format with proprietary software? If we cannot use our own technologies for our own conferences, how will we get the rest of the world to use them?
I must say, I am personally embarrassed, because I was part of several audio/video teams of previous LCAs that have managed to record and stream content in open formats and with open media software. I would have helped get this going, but wasn’t aware of the situation.
I am also the main organiser of the FOMS Workshop (Foundations of Open Media Software) that ran the week before LCA and brought some of the core programmers in open media software into Wellington, most of which are also attending LCA. We have the brains here and should be able to get this going.
Fortunately, the published content will be made available in Ogg Theora/Vorbis. So, it’s only the publicly available stream that I am concerned about.
Speaking with the organisers, I can somewhat understand how this came to be. They took the “easy” way of delegating the video work to an external company. Even though this company is an expert in open source and networking, their media streaming customers are all using Flash or Windows media software, which are current de-facto standards and provide extra features such as DRM. It seems apart from linux.conf.au there were no requests on them for streaming Ogg Theora/Vorbis yet. Their existing infrastructure includes CDN distribution and CDN providers certainly typically don’t provide Ogg Theora/Vorbis support or Icecast streaming.
So, this is actually a problem founded in setting up streaming through a professional service rather than through the community. The way in which this was set up at other events was to get together a group of volunteers that provided streaming reflectors for free. In this way, a community-created CDN is built that can deal with the streams. That there are no professional CDN providers available yet that provide Icecast support is a sign that there is a gap in the market.
But phear not - a few of the FOMS folk got together to fix the situation.
It involved setting up Icecast streams for each room’s video stream. Since there is no access to the raw video stream, there is a need to transcode the video from proprietary codecs to the open Ogg Theora/Vorbis format.
To do this legally, a purchase of the codec libraries from Fluendo was necessary, which cost a whopping EURO 28 and covers all the necessary patent licenses. The glue to get the videos from mms to icecast streams is a GStreamer pipeline which I leave others to talk about.
Now, we have all the streams from the conference available as Ogg Theora/Video streams, we can also publish them in HTML5 video elements. Check out this Web page which has all the video streams together on a single page. Note that the connections may be a bit dodgy and some drop-outs may occur.
Further, let me recommend the Multimedia Miniconf at linux.conf.au, which will take place tomorrow, Tuesday 19th January. The Miniconf has decided to add a talk about “How to stream you conference with open codecs” to help educate any potential future conference organisers and point out the software that helps solve these issues.
UPDATE: I should have stated that I didn’t actually do any of the technical work: it was all done by Ralph Giles, Jan Gerber, and Jan Schmidt.
I am a very happy camper today! Not because of the New Year - well, yes, there are new opportunities and challenges for the New Year. But I’ve just received an email from Philip J
In the previous post I explained that there is a need to expose the tracks of a time-linear media resource to the user agent (UA). Here, I want to look in more detail at different possibilities of how to do so, their advantages and disadvantages.
Note: A lot of this has come out of discussions I had at the recent W3C TPAC and is still in flux, so I am writing this to start discussions and brainstorm.
Declarative Syntax vs JavaScript API
We can expose a media resource’s tracks either through a JavaScript function that can loop through the tracks and provide access to the tracks and their features, or we can do this through declarative syntax.
Using declarative syntax has the advantage of being available even if JavaScript is disabled in a UA. The markup can be parsed easily and default displays can be prepared without having to actually decode the media file(s).
OTOH, it has the disadvantage that it may not necessarily represent what is actually in the binary resource, but instead what the Web developer assumed was in the resource (or what he forgot to update). This may lead to a situation where a “404” may need to be given on a media track.
A further disadvantage is that when somebody copies the media element onto another Web page, together with all the track descriptions, and then the original media resource is changed (e.g. a subtitle track is added), this has not the desired effect, since the change does not propagate to the other Web page.
For these reasons, I thought that a JavaScript interface was preferable over declarative syntax.
However, recent discussions, in particular with some accessibility experts, have convinced me that declarative syntax is preferable, because it allows the creation of a menu for turning tracks on/off without having to even load the media file. Further, declarative syntax allows to treat multiple files and “native tracks” of a virtual media resource in an identical manner.
Extending Existing Declarative Syntax
The HTML5 media elements already have declarative syntax to specify multiple source media files for media elements. The element is typically used to list video in mpeg4 and ogg format for support in different browsers, but has also been envisaged for different screensize and bandwidth encodings.
The elements are generally meant to list different resources that contribute towards the media element. In that respect, let’s try using it for declaring a manifest of tracks of the virtual media resource on an example:
Note that this somewhat ignores my previously proposed special itext tag for handling text tracks. I am doing this here to experiment with a more integrative approach with the virtual media resource idea from the previous post. This may well be a better solution than a specific new text-related element. Most of the attributes of the itext element are, incidentally, covered.
You will also notice that some of the tracks are references to tracks inside binary media files using the Media Fragment URI specification while others link to full files. An example is video.ogv?track=auddesc[en]. So, this is a uniform means of exposing all the tracks that are part of a (virtual) media resource to the UA, no matter whether in-band or in external files. It actually relies on the UA or server being able to resolve these URLs.
”type” attribute
“media” and “type” are existing attributes of the element in HTML5 and meant to help the UA determine what to do with the referenced resource. The current spec states:
The “type” attribute gives the type of the media resource, to help the user agent determine if it can play this media resource before fetching it.
The word “play” might need to be replaced with “decode” to cover several different MIME types.
The “type” attribute was also extended with the possibility to add the “charset” MIME parameter of a linked text resource - this is particularly important for SRT files, which don’t handle charsets very well. It avoids having to add an additional attribute and is analogous to the “codecs” MIME parameter used by audio and video resources.
”media” attribute
Further, the spec states:
The “media” attribute gives the intended media type of the media resource, to help the user agent determine if this media resource is useful to the user before fetching it. Its value must be a valid media query.
The “mobile” and “desktop” values are hints that I’ve used for simplicity reasons. They could be improved by giving appropriate bandwidth limits and width/height values, etc. Other values could be different camera angles such as topview, frontview, backview. The media query aspect has to be looked into in more depth.
”lang” attribute
The above example further uses “lang” and “role” attributes:
The “lang” attribute is an existing global attribute of HTML5, which typically indicates the language of the data inside the element. Here, it is used to indicate the language of the referenced resource. This is possibly not quite the best name choice and should maybe be called “hreflang”, which is already used in multiple other elements to signify the language of the referenced resource.
”role” attribute
The “role” attribute is also an existing attribute in HTML5, included from ARIA. It currently doesn’t cover media resources, but could be extended. The suggestion here is to specify the roles of the different media tracks - the ones I have used here are:
“media”: a main media resource - typically contains audio and video and possibly more
“dub”: a audio track that provides an alternative dubbed language track
“auddesc”: a audio track that provides an additional audio description track
“caption”: a text track that provides captions
“sign”: a video-only track that provides an additional sign language video track
“tad”: a text track that provides textual audio descriptions to be read by a screen reader or a braille device
Further roles could be “music”, “speech”, “sfx” for audio tracks, “subtitle”, “lyrics”, “annotation”, “chapters”, “overlay” for text tracks, and “alternate” for a alternate main media resource, e.g. a different camera angle.
Track activation
The given attributes help the UA decide what to display.
It will firstly find out from the “type” attribute if it is capable of decoding the track.
Then, the UA will find out from the “media” query, “role”, and “lang” attributes whether a track is relevant to its user. This will require checking the capabilities of the device, network, and the user preferences.
Further, it could be possible for Web authors to influence whether a track is displayed or not through CSS parameters on the element: “display: none” or “visibility: hidden/visible”.
Examples for track activation that a UA would undertake using the example above:
Given a desktop computer with Firefox, German language preferences, captions and sign language activated, the UA will fetch the original video at video.ogv (for Firefox), the German caption track at video.ogv?track=caption[de], and the German sign language track at signvid_gsg.ogv (maybe also the German dubbed audio track at video.ogv?track=audio[de], which would then replace the original one).
Given a desktop computer with Safari, English language preferences and audio descriptions activated, the UA will fetch the original video at video.mp4 (for Safari) and the textual audio description at tad_en.srt to be displayed through the screen reader, since it cannot decode the Ogg audio description track at video.ogv?track=auddesc[en].
Also, all decodeable tracks could be exposed in a right-click menu and added on-demand.
Display styling
Default styling of these tracks could be:
video or alternate video in the video display area,
sign language probably as picture-in-picture (making it useless on a mobile and only of limited use on the desktop),
captions/subtitles/lyrics as overlays on the bottom of the video display area (or whatever the caption format prescribes),
textual audio descriptions as ARIA live regions hidden behind the video or off-screen.
Multiple audio tracks can always be played at the same time.
The Web author could also define the display area for a track through CSS styling and the UA would then render the data into that area at the rate that is required by the track.
How good is this approach?
The advantage of this new proposal is that it builds basically on existing HTML5 components with minimal additions to satisfy requirements for content selection and accessibility of media elements. It is a declarative approach to the multi-track media resource challenge.
However, it leaves most of the decision on what tracks are alternatives of/additions to each other and which tracks should be displayed to the UA. The UA makes an informed decision because it gets a lot of information through the attributes, but it still has to make decisions that may become rather complex. Maybe there needs to be a grouping level for alternative tracks and additional tracks - similar to what I did with the second itext proposal, or similar to the and elements of SMIL.
A further issue is one that is currently being discussed within the Media Fragments WG: how can you discover the track composition and the track naming/uses of a particular media resource? How, e.g., can a Web author on another Web site know how to address the tracks inside your binary media resource? A HTML specification like the above can help. But what if that doesn’t exist? And what if the file is being used offline?
Alternative Manifest descriptions
The need to manifest the track composition of a media resource is not a new one. Many other formats and applications had to deal with these challenges before - some have defined and published their format.
I am going to list a few of these formats here with examples. They could inspire a next version of the above proposal with grouping elements.
Microsoft ISM files (SMIL subpart)
With the release of IIS7, Microsoft introduced “Smooth Streaming”, which uses chunking on files on the server to deliver adaptive streaming to Silverlight clients over HTTP. To inform a smooth streaming client of the tracks available for a media resource, Microsoft defined ism files: IIS Smooth Streaming Server Manifest files.
This is a short example - a longer one can be found here:
HTML5 has been criticised for not having a timing model of the media resource in its new media elements. This article spells it out and builds a framework of how we should think about HTML5 media resources. Note: these are my thoughts and nothing offical from HTML5 - just conclusions I have drawn from the specs and from discussions I had.
What is a time-linear media resource?
In HTML5 and also in the Media Fragment URI specification we deal only with audio and video resources that represent a single timeline exclusively. Let’s call such Web resources a time-linear media resource.
The resource can potentially consist of any number of audio, video, text, image or other time-aligned data tracks. All these tracks adhere to a single timeline, which tends to be defined by the main audio or video track, while other tracks have been created to synchronise with these main tracks.
This model matches with the world view of video on YouTube and any other video hosting service. It also matches with video used on any video streaming service.
Background on the choice of “time-linear”
I’ve deliberately chosen the word “time-linear” because we are talking about a single, gap-free, linear timeline here and not multiple timelines that represent the single resource.
The word “linear” is, however, somewhat over-used, since the introduction of digital systems into the world of analog film introduced what is now known as “non-linear video editing”. This term originates from the fact that non-linear video editing systems don’t have to linearly spool through film material to get to a edit point, but can directly access any frame in the footage as easily as any other.
When talking about a time-linear media resource, we are referring to a digital resource and therefore direct access to any frame in the footage is possible. So, a time-linear media resource will still be usable within a non-linear editing process.
As a Web resource, a time-linear media resource is not addressed as a sequence of frames or samples, since these are encoding specific. Rather, the resource is handled abstractly as an object that has track and time dimensions - and possibly spatial dimensions where image or video tracks are concerned. The framerate encoding of the resource itself does not matter and could, in fact, be changed without changing the resource’s time, track and spatial dimensions and thus without changing the resource’s address.
Interactive Multimedia
The term “time-linear” is used to specify the difference between a media resource that follows a single timeline, in contrast to one that deals with multiple timelines, linked together based on conditions, events, user interactions, or other disruptions to make a fully interactive multi-media experience. Thus, media resources in HTML5 and Media Fragments do not qualify as interactive multimedia themselves because they are not regarded as a graph of interlinked media resources, but simply as a single time-linear resource.
In this respect, time-linear media resources are also different from the kind of interactive mult-media experiences that an Adobe Shockwave Flash, Silverlight, or a SMIL file can create. These can go far beyond what current typical video publishing and communication applications on the Web require and go far beyond what the HTML5 media elements were created for. If your application has a need for multiple timelines, it may be necessary to use SMIL, Silverlight, or Adobe Flash to create it.
Note that the fact that the HTML5 media elements are part of the Web, and therefore expose states and integrate with JavaScript, provides Web developers with a certain control over the playback order of a time-linear media resource. The simple functions pause(), play(), and the currentTime attribute allow JavaScript developers to control the current playback offset and whether to stop or start playback. Thus, it is possible to interrupt a playback and present, e.g. a overlay text with a hyperlink, or an additional media resource, or anything else a Web developer can imagine right in the middle of playing back a media resource.
In this way, time-linear media resources can contribute towards an interactive multi-media experience, created by a Web developer through a combination of multiple media resources, image resources, text resources and Web pages. The limitations of this approach are not yet clear at this stage - how far will such a constructed multi-media experience be able to take us and where does it become more complicated than an Adobe Flash, Silverlight, or SMIL experience. The answer to this question will, I believe, become clearer through the next few years of HTML5 usage and further extensions to HTML5 media may well be necessary then.
Proper handling of time-linear media resources in HTML5
At this stage, however, we have already determined several limitations of the existing HTML5 media elements that require resolution without changing the time-linear nature of the resource.
1. Expose structure
Above all, there is a need to expose the above painted structure of a time-linear media resource to the Web page. Right now, when the
We need a means to expose the available tracks inside a time-linear media resource and allow the UA some control over it - e.g. to choose whether to turn on/off a caption track, to choose which video track to display, or to choose which dubbed audio track to display.
I’ll discuss in another article different approaches on how to expose the structure. Suffice for now that we recognise the need to expose the tracks.
2. Separate the media resource concept from actual files
A HTML page is a sequence of HTML tags delivered over HTTP to a UA. A HTML page is a Web resource. It can be created dynamically and contain links to other Web resources such as images which complete its presentation.
We have to move to a similar “virtual” view of a media resource. Typically, a video is a single file with a video and an audio track. But also typically, caption and subtitle tracks for such a video file are stored in other files, possibly even on other servers. The caption or subtitle tracks are still in sync with the video file and therefore are actual tracks of that time-linear media resource. There is no reason to treat this differently to when the caption or subtitle track is inside the media file.
When we separate the media resource concept from actual files, we will find it easier to deal with time-linear media resources in HTML5.
3. Track activation and Display styling
A time-linear media resource, when regarded completely abstractly, can contain all sorts of alternative and additional tracks.
For example, the existing elements inside a video or audio element are currently mostly being used to link to alternative encodings of the main media resource - e.g. either in mpeg4 or ogg format. We can regard these as alternative tracks within the same (virtual) time-linear media resource.
Similarly, the elements have also been suggested to be used for alternate encodings, such as for mobile and Web. Again, these can be regarded as alternative tracks of the same time-linear media resource.
Another example are subtitle tracks for a main media resource, which are currently discussed to be referenced using the element. These are in principle alternative tracks amongst themselves, but additional to the main media resource. Also, some people are actually interested in displaying two subtitle tracks at the same time to learn translations.
Another example are sign language tracks, which are video tracks that can be regarded as an alternative to the audio tracks for hard-of-hearing users. They are then additional video tracks to the original video track and it is not clear how to display more than one video track. Typically, sign language tracks are displayed as picture-in-picture, but on the Web, where video is usually displayed in a small area, this may not be optimal.
As you can see, when deciding which tracks need to be displayed one needs to analyse the relationships between the tracks. Further, user preferences need to come into play when activating tracks. Finally, the user should be able to interactively activate tracks as well.
Once it is clear, what tracks need displaying, there is still the challenge of how to display them. It should be possible to provide default displays for typical track types, and allow Web authors to override these default display styles since they know what actual tracks their resource is dealing with.
While the default display seems to be typically an issue left to the UA to solve, the display overrides are typically dealt with on the Web through CSS approaches. How we solve this is for another time - right now we can just state the need for algorithms for track activiation and for default and override styling.
Hypermedia
To make media resources a prime citizens on the Web, we have to go beyond simply replicating digital media files. The Web is based on hyperlinks between Web resources, and that includes hyperlinking out of resources (e.g. from any word within a Web page) as well as hyperlinking into resources (e.g. fragment URIs into Web pages).
To turn video and audio into hypervideo and hyperaudio, we need to enable hyperlinking into and out of them.
Hyperlinking into media resources is fortunately already being addressed by the W3C Media Fragments working group, which also regards media resources in the same way as HTML5. The addressing schemes under consideration are the following:
temporal fragment URI addressing: address a time offset/region of a media resource
spatial fragment URI addressing: address a rectangular region of a media resource (where available)
track fragment URI addressing: address one or more tracks of a media resource
named fragment URI addressing: address a named region of a media resource
a combination of the above addressing schemes
With such addressing schemes available, there is still a need to hook up the addressing with the resource. For the temporal and the spatial dimension, resolving the addressing into actual byte ranges is relatively obvious across any media type. However, track addressing and named addressing need to be resolved. Track addressing will become easier when we solve the above stated requirement of exposing the track structure of a media resource. The name definition requires association of an id or name with temporal offsets, spatial areas, or tracks. The addressing scheme will be available soon - whether our media resources can support them is another challenge to solve.
Finally, hyperlinking out of media resources is something that is not generally supported at this stage. Certainly, some types of media resources - QuickTime, Flash, MPEG4, Ogg - support the definition of tracks that can contain HTML marked-up text and thus can also contain hyperlinks. But standardisation in this space has not really happened yet. It seems to be clear that hyperlinks out of media files will come from some type of textual track. But a standard format for such time-aligned text tracks doesn’t yet exist. This is a challenge to be addressed in the near future.
Summary
The Web has always tried to deal with new extensions in the simplest possible manner, providing support for the majority of current use cases and allowing for the few extraordinary use cases to be satisfied by use of JavaScript or embedding of external, more complex objects.
With the new media elements in HTML5, this is no different. So far, the most basic need has been satisfied: that of including simple video and audio files into Web pages. However, many basic requirements are not being satisfied yet: accessibility needs, codec choice, device-independence needs are just some of the core requirements that make it important to extend our view of
This post has created the concept of a “media resource”, where we keep the simplicity of a single timeline. At the same time, it has tried to classify the list of shortcomings of the current media elements in a way that will help us address these shortcomings in a Web-conformant means.
If we accept the need to expose the structure of a media resource, the need to separate the media resource concept from actual files, the need for an approach to track activation, and the need to deal with styling of displayed tracks, we can take the next steps and propose solutions for these.
Further, understanding the structure of a media resources allows us to start addressing the harder questions of how to associate events with a media resource, how to associate a navigable structure with a media resource, or how to turn media resources into hypermedia.
Last week’s TPAC (2009 W3C Technical Plenary / Advisory Committee) meetings were my second time at a TPAC and I found myself becoming highly involved with the progress on accessibility on the HTML5 video element. There were in particular two meetings of high relevanct: the Video Accessibility workshop and Friday’s HTML5 breakout group on the video element.
HTML5 Video Accessibility Workshop
The week started on Sunday with the “HTML5 Video Accessibility workshop” at Stanford University, organised by John Foliot and Dave Singer. They brought together a substantial number of people all representing a variety of interest groups. Everyone got their chance to present their viewpoint - check out the minutes of the meeting for a complete transcript.
The list of people and their discussion topics were as follows:
Accessibility Experts
Janina Sajka, chair of WAI Protocols and Formats: represented the vision-impaired community and expressed requirements for a deeply controllable access interface to audio-visual content, preferably in a structured manner similar to DAISY.
Sally Cain, RNIB, Member of W3C PF group: expressed a deep need for audio descriptions, which are often overlooked besides captions.
Ken Harrenstien, Google: has worked on captioning support for video.google and YouTube and shared his experiences, e.g. http://www.youtube.com/watch?v=QRS8MkLhQmM, and automated translation.
Victor Tsaran, Yahoo! Accessibility Manager: joined for a short time out of interest.
Practicioners
John Foliot, professor at Stanford Uni: showed a captioning service that he set up at Stanford University to enable lecturers to publish more accessible video - it uses humans for transcription, but automated tools to time-align, and provides a Web interface to the staff.
Matt May, Adobe: shared what Adobe learnt about accessibility in Flash - in particular that an instream-only approach to captions was a naive approach and that external captions are much more flexible, extensible, and can fit into current workflows.
Frank Olivier, Microsoft: attended to listen and learn.
Technologists
Pierre-Antoine Champin from Liris (France), who was not able to attend, sent a video about their research work on media accessibility using automatic and manual annotation.
Hironobu Takagi, IBM Labs Tokyo, general chair for W4A: demonstrated a text-based audio description system combined with a high-quality, almost human-sounding speech synthesizer.
Dick Bulterman, Researcher at CWI in Amsterdam, co-chair of SYMM (group at W3C doing SMIL): reported on 14 years of experience with multimedia presentations and SMIL (slides) and the need to make temporal and spatial synchronisation explicit to be able to do the complex things.
We are slowly approaching the stage where we want to make multi-track video of the following type available and accessible:
original video track
original audio track
dubbed audio tracks in n different languages
audio description track in n different langauges
sign language video tracks in n different sign langauges
caption tracks in n different langauges
multiple other time-aligned text tracks in different langauges
audio and video track from different camera angles
music and speech tracks can be separate
different quality tracks are available
accompanying images, e.g. slides for a presentation
One of the issues with such a sizeable number of tracks is how to display them. Some of them are alternatives, some of them additions. Sign language is typically presented in a PiP (picture-in-picture) approach. If we have a music and a speech (or singing) track, we may want to have control over removing certain tracks - e.g. to be able to do karaoke. Caption and subtitle tracks in the same language are probably alternatives, while in different languages they could be additions. It is not a trivial challenge to handle such complex files in an application.
At this point, I am only trying to solve a sub-challenge. As we talk about a particular track in a multi-track media file, we will want to identify it by name. Should there be a standard for naming the track, so that we can e.g. address them by a URL, e.g. with the intention of only delivering a subset of tracks from the larger file? We could introduce that for Ogg - but maybe there is an opportunity to do this across file formats?
To find some answers to these and related questions, I want to discuss two approaches.
The first approach is a simple numbering approach. In it, the audio, video, and annotation tracks are all ordered and then numbered through. This will result in the following sets of track names: video[0] … [n], audio[0] … [n], timed text[0] … [n], and possibly even timed images[0] … [n]. This approach is simple, easy to understand, and only requires ordering the tracks within their types. It allows addressing of a particular track - e.g. as required by the media fragment URI scheme for track addressing. However, it does not allow identification of alternatives, additions, or presentation styles.
Should alternatives, additions, and presentation styles be encoded in the name of track? Or should this information go into a meta description area of the multi-track video? Something like skeleton in Ogg? Or should it go a step further and be buried in an external information file such as an m3u file (or ROE for Ogg)?
I want to experiment here with the naming scheme and what we would need to specify to be able to decide which tracks to ignore and which to combine for a presentation. And I want to ask for your comments and advice.
This requires listing exactly what types of content tracks we may have to deal with.
In the video space, we have at minimum the following track types:
main video content - with alternative camera angles
subsidiary video content - with alternative camera angles
sign language videos - in alternative languages
Alternatives are defined by camera angle and language. Also, each track can be made available in a different quality. I’d also regard additional image content, such as slides in a presentation, into subsidiary video content. So, here we could use a scheme such as video_[main,side,sign]_language_angle.
In the audio space, we have at minimum the following track types:
main audio content - in alternative languages
background audio content - e.g.music, SFX, noise
foreground speech or singing content - in alternative languages
audio descriptions - in alternative languages
Alternatives are defined by language and content type. Again, each track can be made available in a different quality. Here we could use a scheme such as audio_type_language.
In the text space, we have at minimum the following track types:
subtitles - in different languages
captions - in different languages
textual audio descriptions - in different languages
other time-aligned text - in different languages
Alternatives are defined by language and content type - e.g. lyrics, captions and subtitles really compete for the same screen space. Here we could use a scheme such as text_type_language.
A generic track naming scheme It seems, the generic naming scheme of
<content_type>_<track_type>_ [_]
can cover all cases.
Are there further track types, further alternatives I have missed? What do you think?
I had the great pleasure to be part of the W3C presentations at Web Directions South. But I had the even greater pleasure to upload part of Doug Schepers’ talk as recorded by Laurent Lefort. It contains the shocking news that the W3C got acquired by Twitter and how standards will change through that in the near future. Here’s the video - enjoy!
_This talk focuses on the efforts engaged by W3C to improve the new HTML 5 media elements with mechanisms to allow people to access multimedia content, including audio and video. Such developments are also useful beyond accessibility needs and will lead to a general improvement of the usability of media, making media discoverable and generally a prime citizen on the Web.
Silvia will discuss what is currently technically possible with the HTML5 media elements, and what is still missing. She will describe a general framework of accessibility for HTML5 media elements and present her work for the Mozilla Corporation that includes captions, subtitles, textual audio annotations, timed metadata, and other time-aligned text with the HTML5 media elements. Silvia will also discuss work of the W3C Media Fragments group to further enhance video usability and accessibility by making it possible to directly address temporal offsets in video, as well as spatial areas and tracks._
On Wednesday evening I gave a 3 min presentation on video accessibility in HTML5 at the WebJam in Sydney. I used a video as my presentation means and explained things while playing it back. Here is the video, without my oral descriptions, but probably still useful to some. Note in particular how you can experience the issues of deaf (HoH), blind (VI) and foreign language users:
The feedback has encouraged me to develop a new specification that includes the concerns and makes it easier to associate out-of-band time-aligned text (i.e. subtitles stored in separate files to the video/audio file). A simple example of the new specification using srt files is this:
By default, the charset of the itext file is UTF-8, and the default format is text/srt (incidentally a mime type the still needs to be registered). Also by default the browser is expected to select for display the track that matches the set default language of the browser. This has been proven to work well in the previous experiments.
Check out the new itext specification, read on to get an introduction to what has changed, and leave me your feedback if you can!
The itextlist element You will have noticed that in comparison to the previous specification, this specification contains a grouping element called “itextlist”. This is necessary because we have to distinguish between alternative time-aligned text tracks and ones that can be additional, i.e. displayed at the same time. In the first specification this was done by inspecting each itext element’s category and grouping them together, but that resulted in much repetition and unreadable specifications.
Also, it was not clear which itext elements were to be displayed in the same region and which in different ones. Now, their styling can be controlled uniformly.
The final advantage is that association of callbacks for entering and leaving text segments as extracted from the itext elements can now be controlled from the itextlist element in a uniform manner.
This change also makes it simple for a parser to determine the structure of the menu that is created and included in the controls element of the audio or video element.
Incidentally, a patch for Firefox already exists that makes this part of the browser. It does not yet support this new itext specification, but here is a screenshot that Felipe Corr
Just a brief note to let everyone know about a new wikipage I created for my Mozilla work about video accessibility, where I want to track the status and outcomes of my work. You can find it at https://wiki.mozilla.org/Accessibility/Video_a11y_Aug09. It lists the following sections: Test File Collection, Specifications, Demo implementations using JavaScript, Related open bugs in Mozilla, and Publications.
As part of my experiments in video accessibility I am also looking at the audio element. I have just finished a proof of concept for parsing Lyrics files for music in lrc format.
Looking at accessibility for video includes sign language. It is a most fascinating area to get into and an area that still leaves a lot to formalise and standardise. A lot has happened in recent years and a lot still needs to be done.
Sign languages are different languages to spoken languages: they emerged in parallel to spoken languages in communities whose boundaries may not overlap with the boundaries of spoken languages. However, most developed means to translate spoken language artifacts (i.e. letters) into sign language artifacts (i.e. signs). So, a typical signer will speak/write at least 3-4 “languages”: the spoken language of their hearing peers, lip reading of that spoken language, letter signs of the spoken language, and finally the native sign language of the community they live in.
Encoding sign language in the computer is a real challenge. Firstly, there is the problem of enumerating all available languages. Then there is the challenge to find an alphabet to represent all “characters” that can be used in sign across many (preferably all) sign languages. Then there is the need to encode these characters in a way that computers can deal with. And finally, there is the need to find a screen representation of the characters. In this blog post, I want to describe the status for all of these.
Currently, sign language can only be represented as a video track by recording sign speakers. Once a sign character list together with an encoding and representation means for them and a specification of the different sign languages is available, it is possible to encode sign sentences in computer-readable form. Further, programs can be written that can present sign sentences on screen, that translate between different sign languages, and between sign and spoken languages. Also, avatars can be programmed that actually present animated sign sentences.
Imagine a computer that instead of presenting letters in your spoken language uses sign language characters and has keys with signs on them instead of letters. To a sign speaker this would be a lot more natural, since for most sign is their mother tongue.
Listing all existing sign languages It was a challenge to create codes for all existing spoken languages - the current list of language codes has only been finalised in 1998.
Until the 1980s, scientists assumed that it is impossible to develop as rich a language with signs as with writing and speaking. Thus, the native languages of deaf people were often regarded as inferior to spoken languages. In many countries it was even prohibited to teach the language in schools for the deaf and instead they were taught to speak an oral language and read lips. In France this prohibition was only lifted in 1991! Only in about 1985 was it proven that sign languages are indeed as rich as spoken languages and deserve the right to be called a “language” and be treated as a fully capable means of communication.
So, there hasn’t actually been much time to map out a list of all sign languages. The best list I was able to find is in Wikipedia. It lists 28 N/S American, 38 European, 34 Asia-Pacific-AU/NZ, 30 African, and 13 Middle Eastern sign languages - in summary 143 sign languages. This list contains 177 sign languages.
Interestingly, there is also a new International Sign Language in development called Gestuno which is in use in international events (Olympics, conferences etc.) but has only a limited vocabulary.
While not complete, the current IANA subtag language registry now regards sign languages as valid derivatives of a country’s languages and therefore handles them identically to spoken languages. It’s also extensible such that any sign language not yet registered can still be specified.
Characters for sign languages The written word is very powerful for preserving and sharing information. For a very long time there has been no written representation of sign languages. This is not surprising considering that there are still indigenous spoken languages that have no written representation. Also, the written representation of the spoken language around the community of a sign language would have served the sign community sufficiently for most purposes - except for the accurate capture of their thoughts and sign communications. It would always be a foreign language.
To move sign languages into the 20th century, the invention of characters for signs was necessary.
The real challenge lies in capturing the proper signs deaf people use to communicate amongst themselves.
This is rather challenging, since sign languages uses the hands, head and body, with constantly changing movements and orientations for communication. Thus, while spoken language only has one dimension (sound) over time, sign languages have “three dimensions” and capturing this in characters is difficult. Many sign languages to this date don’t have a widely used written form, e.g. AUSLAN. Mostly in use nowadays are sequences of photos or videos - which of course cannot be computer processed easily.
Two main writing systems have been developed: the phonemic Stokoe notation and the iconic SignWriting.
Stokoe notation was created by William Stokoe for ASL in 1960, with Latin letters and numbers used for the shapes they have in fingerspelling, and iconic glyphs to transcribe the position, movement, and orientation of the hands. Adaptations were made to other sign languages to include further phonemes not found in ASL. Stokoe notation is written left-to-right on a page and can be typed with the proper font installed. It has a Unicode/ASCII mapping, but does not easily apply to other sign languages than ASL since it does not capture all possible signs. It has no representation for facial and body expressions and is therefore a relatively poor representation for sign.
SignWriting was created by Valerie Sutton in 1974, a dancer who had two years earlier developed DanceWriting and later developed MimeWriting, SportsWriting, and ScienceWriting. SignWriting is a writing system which uses visual symbols to represent the handshapes, movements, and facial expressions of sign languages. It is a generic sign alphabet with a list of symbols that can be used to write any sign language in the world.
SignWriting can be easily learnt by signers and is more popular now than Stokoe. Signers compose the symbols together in a spatial way to represent their signs. They then write the composed symbols from top to bottom on a page, similar to other iconic character sets. SignWriting currently supports 73 different sign languages, whose dictionaries and encyclopedias are captured in SignPuddle. This will eventually allow the creation of complete corpora for all sign languages.
Unicode encoding of SignWriting and visual representation Because of its unique challenges of having to cover the spatial combination of symbols as a new symbol rather than just the sequential combination of symbols, it took a while to get a Unicode representation of SignWriting.
A binary representation of SignWriting is defined in ISWA 2008. It is based on a representing 639 base symbols and their potential 6 fill and 16 rotation variants in 61,343 code points, that completely cover the subset of 35023 valid symbol codes. The spatial aspect of SignWriting are encoded in a 2-dimensional coordinate system. The dimensions go from -1919 through 1919 to place the top left corner of the symbol.
SignWriting base symbols are encoded in plane 4 of Unicode, which provides 65,536 code points, easily covering the defined 61,343 Binary SignWriting code points. Further special control and number characters are used to encode the spatial layout.
Visual Representation of SignWriting Valerie Sutton created over 35k individual PNG images for ISWA 2008, which have been reformatted for standard color & reduced file size, and renamed to the character code. They are a font used to represent the signs. The images can be accessed on Valerie’s server.
Closing After learning all this today, I have to say that Valerie Sutton has just turned into a new idol of mine. The achievements with SignWriting and the possibilities it will enable are massive.
Now I just have to figure out what to do when we hit on a sign language track that has been encoded in SignWriting and it represents captions. Maybe it is possible to display sign as overlay but on the left side of the video. This would be similar to some other languages that go from top to bottom rather than left to right.
It should now support ARIA and tab access to the menu, which I have simply put next to the video. I implemented the menu by learning from YUI. My Firefox 3.5.3 actually doesn’t tab through it, but then it also doesn’t tab through the YUI example, which I think is correct. Go figure.
Also, the textual audio descriptions are improved and should now work better with screenreaders.
As soon as some kind soul donates a sign language track for “Elephants Dream”, I will have a pretty complete set of video accessibility tracks for that video. This will certainly become the basis for more video a11y work!
In the W3C Media Fragment Working Group (MFWG) we have had long discussions about the use of the URI query (”?”) or the URI fragment (”#”) addressing approach for addressing directly into media fragments, and the diverse new HTTP headers required to serve such URI requests, considering such side conditions as the stripping-off of fragment parameters from a URI by Web browsers, or the existence of caching Web proxies.
As explained earlier, URI queries request (primary) resources, while URI fragments address secondary resources, which have a relationship to their primary resource. So, in the strictest sense of their specifications, to address segments in media resources without losing the context of the primary resource, we can only use URI fragments.
Browser-supported Media Fragment URIs
For this reason, URI fragments are also the way in which my last media fragment addressing demo has been implemented. For example, I would address
In an effort to give a demo of some of the W3C Media Fragment WG specification capabilities, I implemented a HTML5 page with a video element that reacts to fragment offset changes to the URL bar and the
If you simply load that Web page, you will see the video jump to an offset because it is referred to as “elephants_dream/elephant.ogv#t=20”.
If you change or add a temporal fragment in the URL bar, the video jumps to this time offset and overrules the video’s fragment addressing. (This only works in Firefox 3.6, see below - in older Firefoxes you actually have to reload the page for this to happen.) This functionality is similar to a time linking functionality that YouTube also provides.
When you hit the “play” button on the video and let it play a bit before hitting “pause” again - the second at which you hit “pause” is displayed in the page’s URL bar . In Firefox, this even leads to an addition to the browser’s history, so you can jump back to the previous pause position.
Three input boxes allow for experimentation with different functionality.
The first one contains a link to the current Web page with the media fragment for the current video playback position. This text is displayed for cut-and-paste purposes, e.g. to send it in an email to friends.
The second one is an entry box which accepts float values as time offsets. Once entered, the video will jump to the given time offset. The URL of the video and the page URL will be updated.
The third one is an entry box which accepts a video URL that replaces the . It is meant for experimentation with different temporal media fragment URLs as they get loaded into the
Javascript Hacks
You can look at the source code of the page - all the javascript in use is actually at the bottom of the page. Here are some of the juicy bits of what I’ve done:
Since Web browsers do not support the parsing and reaction to media fragment URIs, I implemented this in javascript. Once the video is loaded, i.e. the “loadedmetadata” event is called on the video, I parse the video’s @currentSrc attribute and jump to a time offset if given. I use the @currentSrc, because it will be the URL that the video element is using after having parsed the @src attribute and all the containing elements (if they exist). This function is also called when the video’s @src attribute is changed through javascript.
This is the only bit from the demo that the browsers should do natively. The remaining functionality hooks up the temporal addressing for the video with the browser’s URL bar.
To display a URL in the URL bar that people can cut and paste to send to their friends, I hooked up the video’s “pause” event with an update to the URL bar. If you are jumping around through javascript calls to video.currentTime, you will also have to make these changes to the URL bar.
Finally, I am capturing the window’s “hashchange” event, which is new in HTML5 and only implemented in Firefox 3.6. This means that if you change the temporal offset on the page’s URL, the browser will parse it and jump the video to the offset time.
Optimisation
Doing these kinds of jumps around on video can be very slow when the seeking is happening on the remote server. Firefox actually implements seeking over the network, which in the case of Ogg can require multiple jumps back and forth on the remote video file with byte range requests to locate the correct offset location.
To reduce as much as possible the effort that Firefox has to make with seeking, I referred to Mozilla’s very useful help page to speed up video. It is recommended to deliver the X-Content-Duration HTTP header from your Web server. For Ogg media, this can be provided through the oggz-chop CGI. Since I didn’t want to install it on my Apache server, I hard coded X-Content-Duration in a .htaccess file in the directory that serves the media file. The .htaccess file looks as follows:
<Files "elephant.ogv"> Header set X-Content-Duration "653.791" </Files>
This should now help Firefox to avoid the extra seek necessary to determine the video’s duration and display the transport bar faster.
I also added the @autobuffer attribute to the
ToDos
This is only a first and very simple demo of media fragments and video. I have not made an effort to capture any errors or to parse a URL that is more complicated than simply containing “#t=”. Feel free to report any bugs to me in the comments or send me patches.
Also, I have not made an effort to use time ranges, which is part of the W3C Media Fragment spec. This should be simple to add, since it just requires to stop the video playback at the given end time.
Also, I have only implemented parsing of the most simple default time spec in seconds and fragments. None of the more complicated npt, smpte, or clock specifications have been implemented yet.
The possibilities for deeper access to video and for improved video accessibility with these URLs are vast. Just imagine hooking up the caption elements of e.g. an srt file with temporal hyperlinks and you can provide deep interaction between the video content and the captions. You could even drive this to the extreme and jump between single words if you mark up each with its time relationship. Happy experimenting!
UPDATE: I forgot to mention that it is really annoying that the video has to be re-loaded when the @src attribute is changed, even if only the hash changes. As support for media fragments is implemented in
Thanks go to Chris Double and Chris Pearce from Mozilla for their feedback and suggestions for improvement on an early version of this.
Say, you are watching Thomas’ live stream from above at http://localhost:8800 and you want to jump back by 2 min. Your player would grab the current streaming time, e.g. 2009-08-26T12:34:04Z and subtract the two minutes, giving 2009-08-26T12:32:04Z. Then the player would use this to tell your streaming server to jump back by two minutes using this URL: http://localhost:8800#t=clock:2009-08-26T12:32:04Z.
Or another example would be: you had a stream running all day from a conference and you want to go back to a particular session. You know that it was between 10am and 11am German time (UTC+2 right now). Then your URL would be as follows: http://conference:8800#t=clock:2009-08-26T10:00+02:00,2009-08-26T11:00+02:00




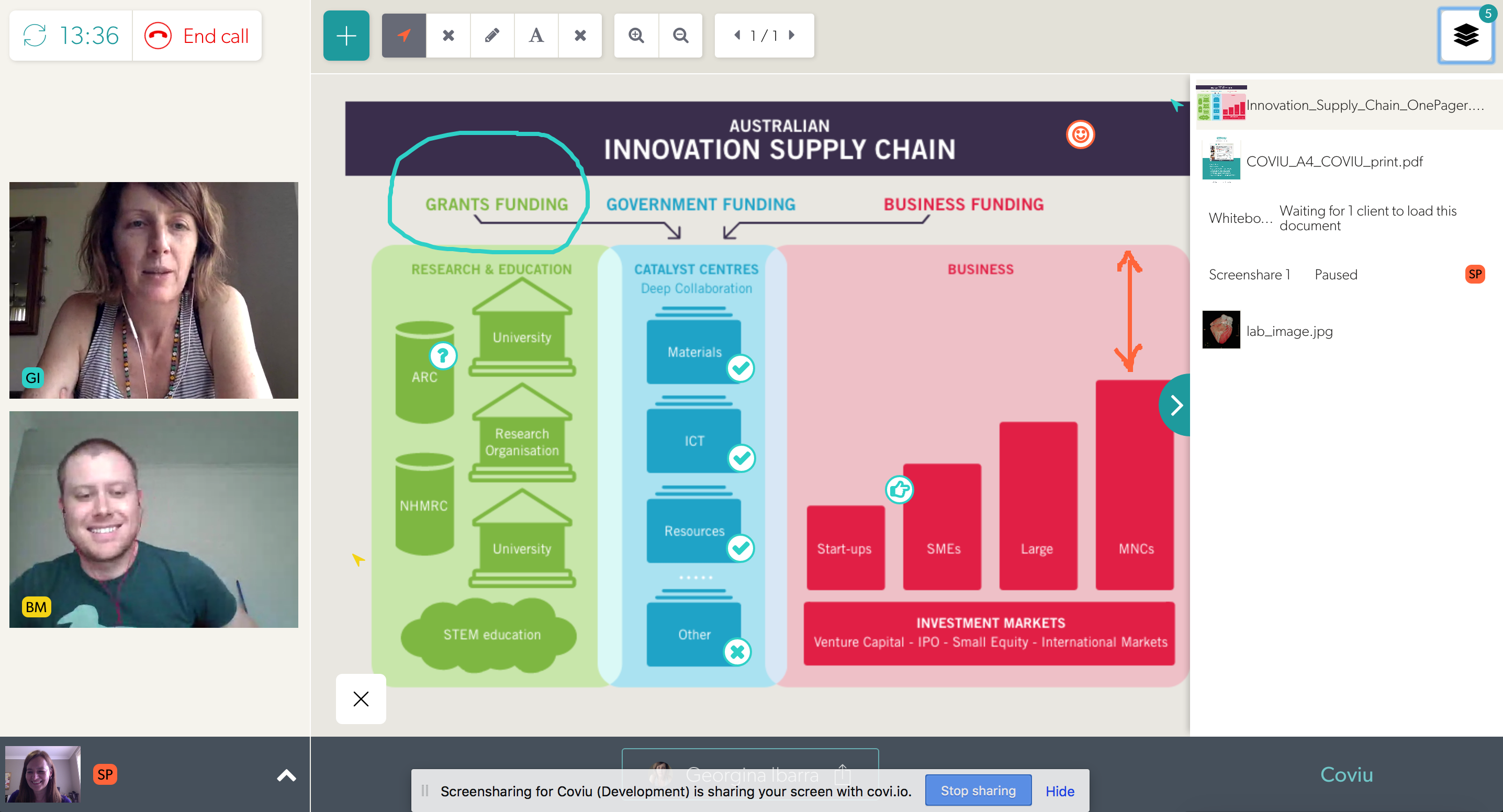



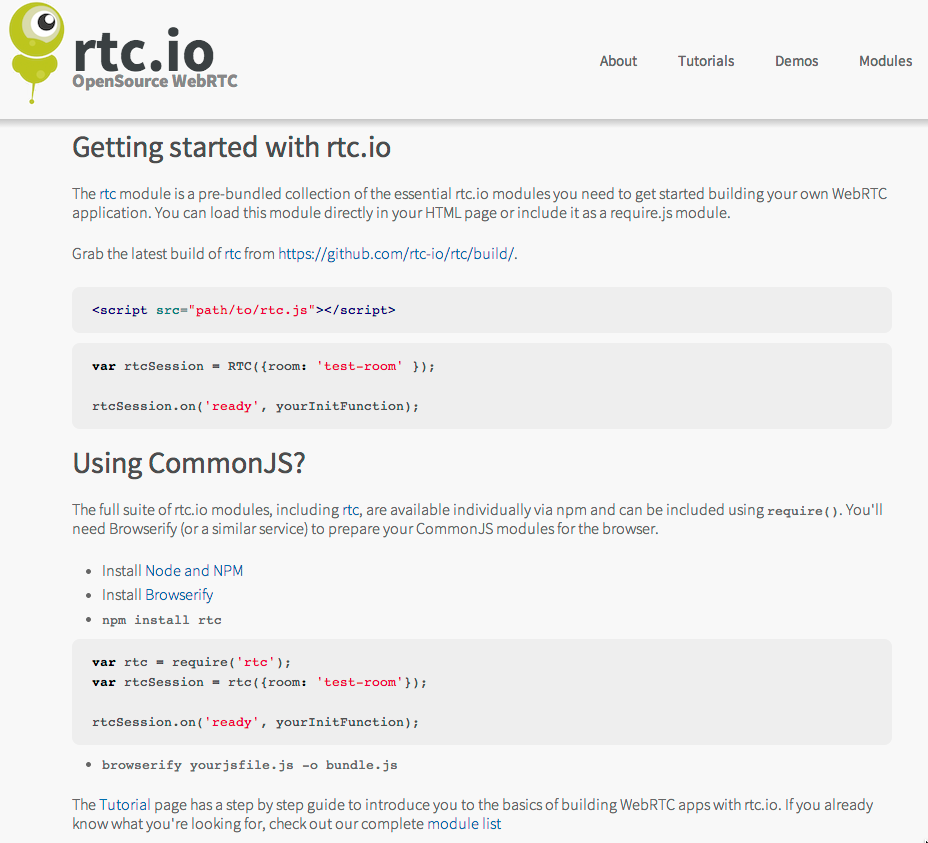 Using
Using 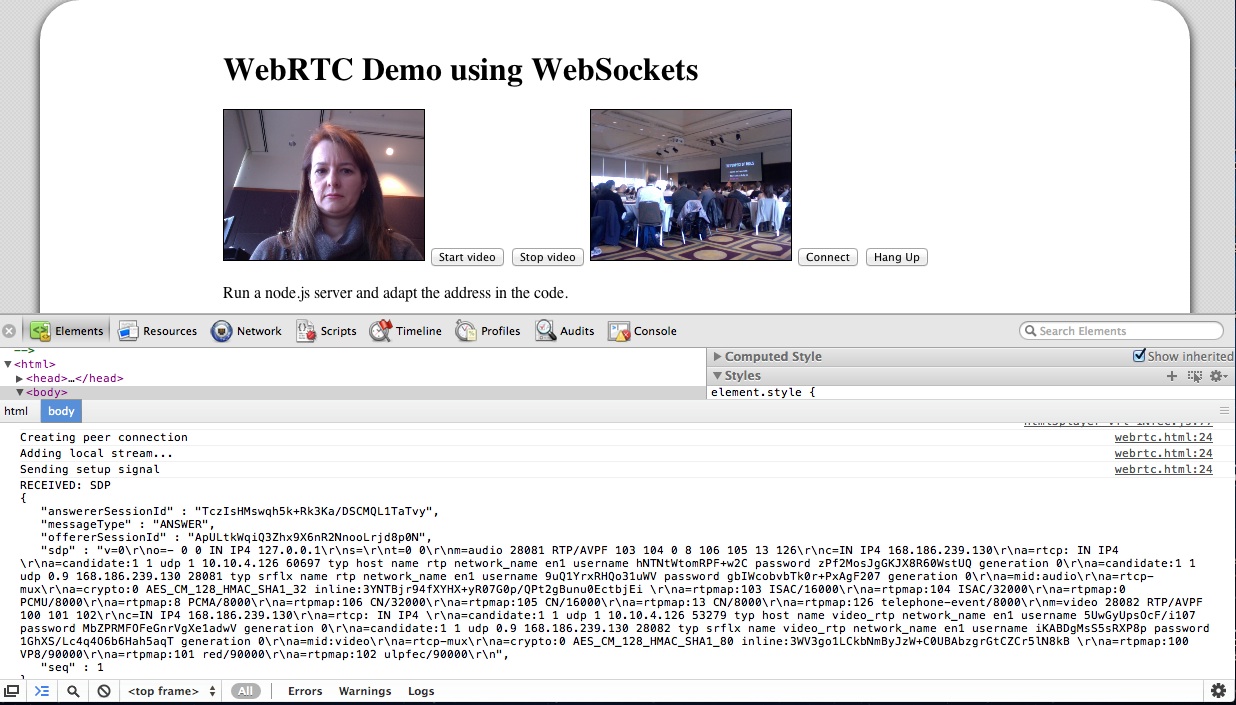






{kind=link}